AI Research Daily
更新时间: 2026/5/6 03:18:35
方法或结果明显独立成立的工作,建议读全文
OpenAI发布GPT-5.5 Instant的系统卡(System Card),披露模型的安全性、能力边界及风险评估。
OpenAI正式发布GPT-5.5 Instant,作为ChatGPT的新默认模型,旨在提供更智能、更准确、幻觉更少且更个性化的体验。
OpenAI推出ChatGPT广告的新购买方式,包括自助广告管理器和CPC竞价。
在“高质量数据受限、算力相对充裕”的预训练场景里,重复数据(多 epoch)会带来过拟合并导致验证损失反弹;而 Chinchilla 及既有 data-repetition 扩展(如 effective-data 形式)要么默认 token 唯一、要么只能刻画收益递减,无法刻画“重复到一定程度反而变差”,也无法刻画过拟合与模型规模的交互,从而不能给出可靠的 compute-optimal 配置建议。
现有预训练优化仅以基础模型的预训练损失、基准测试性能为目标,忽略了模型参数对后续后训练、量化等操作带来的参数扰动的敏感性,导致后训练后出现严重灾难性遗忘,基础模型的性能增益无法传递到下游场景。
这篇工作解决的是一个当前很实际的瓶颈:深度研究型 agent 想在前沿科学问题上变强,缺的不是通用网页检索能力,而是高质量、可自动扩展、能覆盖稀疏学术证据和科学计算过程的训练数据。现有自动构造信息寻求任务的方法,大多依赖 Wikipedia 式实体图谱或连续网页浏览,适合事实检索,不适合前沿科学里那种知识分散、概念异构、还需要公式和参数计算的长链条推理。SciResearcher 的核心目标,就是搭一个全自动数据构造框架,把“前沿科学推理”拆成可规模化生成的训练样本,并验证这些样本能否真正提升 deep research agent 的能力。
Model Spec Midtraining 解决的是 alignment fine-tuning 的泛化欠定问题。只用行为示范做对齐时,模型可能学到表面偏好,而没有学到这些行为背后的规则、价值和适用边界。同一批示范数据可以支持多种解释,模型最终泛化到哪一种解释,取决于训练前已有的表示和先验。
这项工作讨论一个很具体的问题:在没有人工标注答案的情况下,RLVR 能否继续扩展 LLM 的推理训练。作者把这类方法定义为 Unsupervised RLVR,即在可验证任务上不使用人工 ground truth,而依赖模型自身或外部代理信号构造奖励。核心结论是:内生奖励类 URLVR 主要是在“锐化”模型已有分布,而不是稳定地产生新的推理能力。它能放大模型原先更倾向的答案,也可能把错误偏好放大到模式坍塌。
这项工作要回答一个很窄但重要的问题:LLM 在没有知识、语义线索、格式约束和任务模板帮助时,能把一个简单规则稳定执行多久。作者选择“数一串完全相同的符号并输出数量”作为最小探针,用 Stable Counting Capacity, SCC,测量模型在状态跟踪失效前能处理的最大长度。核心不是证明模型不会数数,而是用计数作为可控实验,定位模型执行程序性规则的可靠边界。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

OpenAI发布GPT-5.5 Instant的系统卡(System Card),披露模型的安全性、能力边界及风险评估。

OpenAI正式发布GPT-5.5 Instant,作为ChatGPT的新默认模型,旨在提供更智能、更准确、幻觉更少且更个性化的体验。

OpenAI推出ChatGPT广告的新购买方式,包括自助广告管理器和CPC竞价。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

在“高质量数据受限、算力相对充裕”的预训练场景里,重复数据(多 epoch)会带来过拟合并导致验证损失反弹;而 Chinchilla 及既有 data-repetition 扩展(如 effective-data 形式)要么默认 token 唯一、要么只能刻画收益递减,无法刻画“重复到一定程度反而变差”,也无法刻画过拟合与模型规模的交互,从而不能给出可靠的 compute-optimal 配置建议。
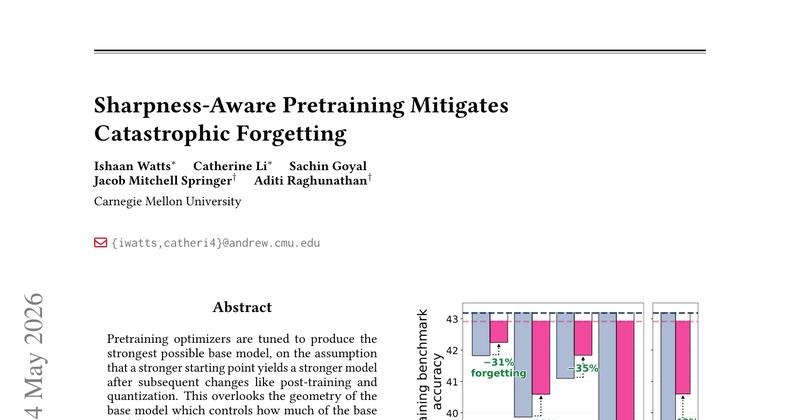
现有预训练优化仅以基础模型的预训练损失、基准测试性能为目标,忽略了模型参数对后续后训练、量化等操作带来的参数扰动的敏感性,导致后训练后出现严重灾难性遗忘,基础模型的性能增益无法传递到下游场景。

扩散式语言模型(DLM)在迭代去噪中具备“全局建模”的潜力,但现有解码(尤其是带 CFG 的逐步填充/置信度驱动策略)呈现明显的局部偏置:更靠近已确定位置的 token 更容易被优先确定,导致模型忽视上下文中信息密度不均的事实——少量“高信息密度(HD)token”往往是推理与语义的锚点。论文要解决的是:在不改训练的前提下,如何在解码阶段识别并利用这些 HD token,提升 DLM 的生成质量,并进一步利用其“更早收敛”的动态特性加速解码。

StyleShield: Exposing the Fragility of AIGC Detectors through Continuous Controllable Style Transfer
AIGC 检测器通常依赖于 AI 和人类文本之间的统计差异,但随着 LLM 的进步和人类写作习惯的改变,这种差异正在消失。现有的对抗性探测方法(如重写、回译、同义词替换)要么无法有效规避检测,要么会严重破坏文本的语义和流畅度,且缺乏对转换强度的连续控制。
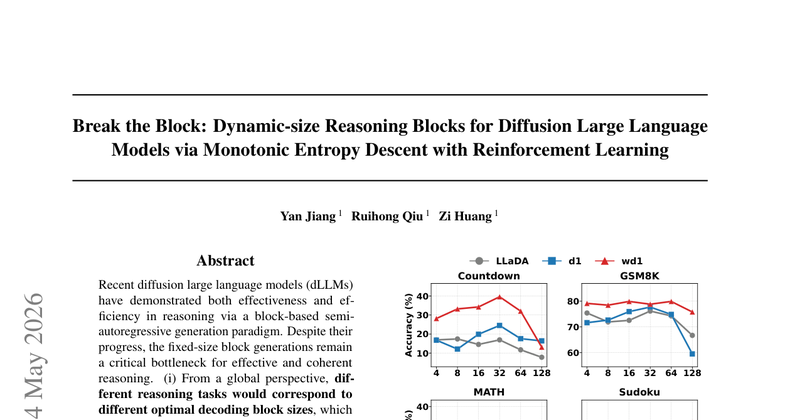
扩散大语言模型(dLLM)现有半自回归生成范式采用固定大小分块,无法适配不同推理任务的最优分块大小需求,且单任务内固定分块会打断推理逻辑流,降低推理连贯性和准确率。

这篇工作讨论的是一个老问题,但切口比较新:为什么 Adam 一类自适应优化器在大模型训练里几乎是默认选择,却常常比 SGD 更容易带来泛化损失,而且不同模型家族之间很难有一个统一好用的优化器。作者把问题收束到 pre-conditioner 的“适应性强度”上,也就是梯度缩放变化时,预条件矩阵会跟着变化多少。现有方法把这个强度基本固定死了:SGD 接近 0,Adam/RMSProp 接近 1。作者认为这会让优化器对某类梯度统计过度匹配,换到另一类训练景观时就不合适,因此提出把 adaptivity 作为一个连续可调的控制变量,而不是离散地在 SGD 和 Adam 之间二选一。

现有Transformer点积自注意力依赖Q、K、V三个可学习线性投影,存在参数冗余且无明确理论证明其必要性。

LLM面对任务、领域、人设、风格等文本条件变化时,常规微调容易遗忘,标准元学习又难以扩展到大模型。

在网络包含不可微组件时,如何不用 surrogate gradient 或反向传播而稳定训练模型。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving
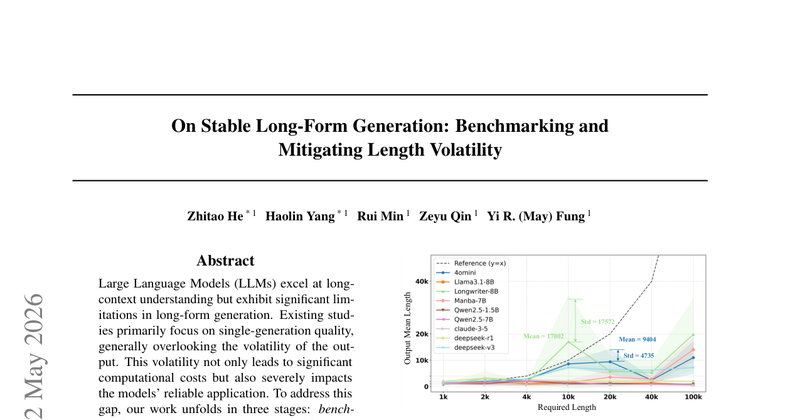
长文本生成的主要问题不只是“平均能不能写够长度”,而是同一指令多次采样时输出长度分布高度不稳定(length volatility),导致成本不可控、可靠性差。论文要解决的是:如何系统量化这种波动、定位与内部机制相关的可观测模式,并给出无需训练的缓解策略。
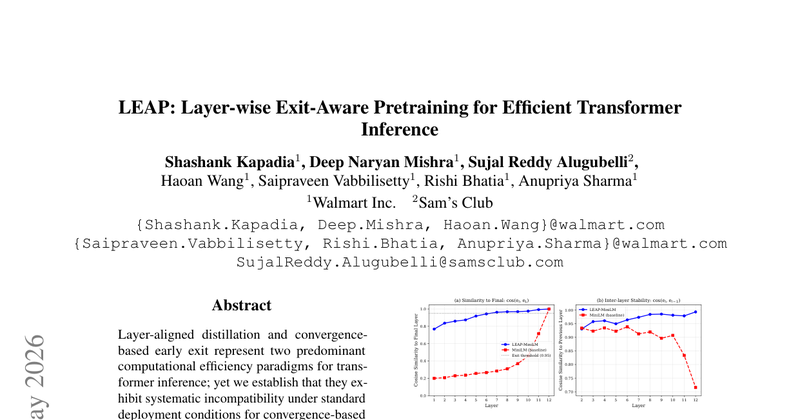
这篇工作处理的是一个部署层面很常见、但训练目标里很少被正面讨论的冲突:层对齐蒸馏得到的小模型,往往无法再配合基于表示收敛的 early exit 使用。原因不在阈值没调好,也不在退出策略太粗糙,而在于标准 layer-wise distillation 会要求学生每一层都去拟合教师对应层,从而把表征能力均匀摊在整个深度上。这样一来,相邻层之间不会自然出现“后几层变化越来越小”的收敛结构,early exit 依赖的可提前终止条件就失效了。论文要解决的核心问题,是如何在不改模型结构、不增加推理参数的前提下,让蒸馏模型既保留蒸馏收益,又重新具备可用的中间退出点。

这篇工作讨论的是推理阶段的计算分工问题:当前 reasoning model 把“高难度推理”和“低难度答案表述”混在同一条 token 流里,由同一个大模型完整生成,导致大量昂贵 token 被花在格式化、复述和低信息密度的后处理上。论文要解决的核心问题,是能否把推理过程拆成两段:让大模型只负责产出压缩过的 reasoning signal,再让小模型读取这个信号并生成最终答案,从而在尽量不掉性能的前提下减少大模型 token 开销。

在自回归(chunk-wise)视频扩散生成里,推理时间主要被“每个 chunk 仍要做很多步迭代去噪”拖住。已有 cache/skip 方法要么面向非自回归 DiT、要么只能做 chunk 级二值跳步,忽略了同一 chunk 内不同帧/不同空间位置的运动差异,导致要么加速不够、要么高运动区域误差累积引发时序崩坏。论文要解决的是:在不引入显著额外显存的前提下,如何做细粒度(token/pixel 级)自适应缓存复用,让高运动区域多算、静态区域多跳,从而稳定加速 AR 视频扩散推理。

这篇论文处理的是一个很具体的推理解码问题:如果 base LLM 已经给正确长程解答分配了非零概率质量,怎样在不训练 verifier、也不改模型参数的前提下,用有限推理预算更高效地把这些解答找出来。作者把问题放在 power sampling 框架下,即目标不是从原始分布 p(x) 采样,而是从更尖锐的序列级分布 p(x)^α 采样。难点在于,前缀值不只由当前 token likelihood 决定,还取决于未来还能接上多少高质量后缀,也就是一个未来归一化项 z_t。已有方法要么靠 MCMC,计算重;要么靠 rollout 显式估 z_t,前瞻有效但成本高。论文要解决的核心问题就是:能否把这个 future value 以更便宜、更适合有限粒子预算的方式注入解码过程。

长上下文自回归解码在 decode 阶段受 KV cache 读带宽限制。精确注意力每生成一个 token 都要读取全部 key/value,尤其 value 聚合阶段需要访问所有 value 行。SANTA 试图在不丢弃 KV cache、不改模型权重的前提下,减少每步实际读取的 value 行数。
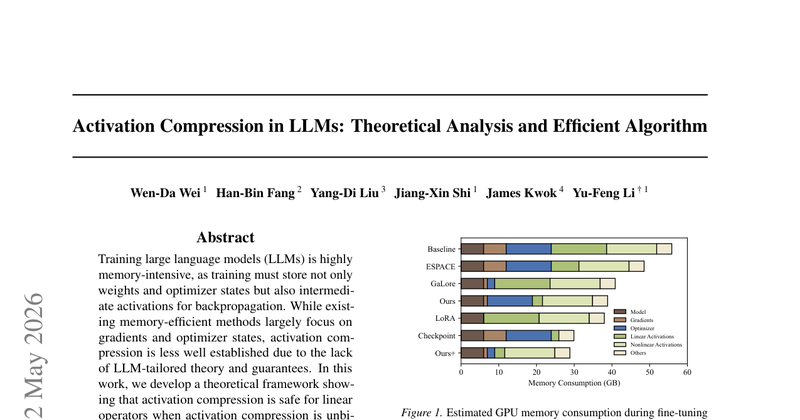
这篇工作讨论的是 LLM 训练里一个很实际但常被系统技巧掩盖的问题:激活存储占了大量显存,低秩压缩看起来能省内存,但它会改写反向传播路径,进而影响优化稳定性。现有做法多停留在经验层面,缺少适用于 Transformer/LLM 的理论边界,因此大家知道它可能有效,却不知道什么时候安全、什么时候风险很大。全文试图回答两个问题:压缩激活后,梯度是否仍然无偏;压缩误差会不会沿层间传播并累积。作者给出的结论是,在线性算子上做无偏激活压缩是相对安全的,而在非线性算子上做压缩会同时引入偏差和上游误差传播。

大语言模型量化在压缩率和精度之间存在明显权衡:GPTQ/AWQ 等有损压缩在低比特下会导致零样本精度下降,而无损压缩(如 ZipNN)压缩率有限且缺乏推理加速支持。本文试图寻找两者之间的平衡点,即“统计无损”量化。

现有推测解码系统普遍采用固定的推测长度γ,未考虑任务差异与目标模型压缩水平对最优γ的影响,导致推理效率损失

研究显式 attention 是否真的是全局视觉建模能力的必要来源,并尝试用线性复杂度的动态参数化层替代它。

扩散式图像编辑推理昂贵,动态分辨率采样常用的低层启发式(边缘/方差)与“编辑语义相关区域”不匹配,导致算力浪费与结构不一致。

CoVSpec: Efficient Device-Edge Co-Inference for Vision-Language Models via Speculative Decoding
研究如何把大 VLM 部署到移动端-边缘协同场景中,并降低 speculative decoding 在多模态推理中的视觉 token 计算和通信开销。

解决现有低秩压缩和参数高效微调串行执行导致压缩子空间与下游任务目标错位、浪费参数预算的问题。

在长上下文、长时间运行的 LLM 推理服务中,如何低成本且快速地实现 KV Cache 的容错和恢复?

这篇 position paper 讨论 LLM serving 仍大量依赖通用启发式策略,而这些策略没有刻画 LLM 推理特有的资源与调度结构,因而难以在复杂负载下稳定最优。

分离式LLM Serving架构中prefill生成的KV缓存跨节点传输瓶颈,现有压缩方案压缩速度过慢不适合在线场景

解决 LLM 低秩分解压缩中保留哪些奇异向量基的问题,避免只按重学习系数大小剪枝带来的任务性能失配。

在生产级文本 embedding 管线中,同时处理大量逻辑分区数据和高 GPU 利用率,避免逐分区调用带来的 IPC 开销和固定大批处理带来的内存问题。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

这篇工作要解决的是:现有 omni-modal/VLM 系统在编码阶段仍然是“模态分开、时间分粗细不一致”的。视频通常只取 1–2 fps,音频却按 25 fps 甚至更密处理,导致模型在进入 LLM 之前就已经丢掉了大量细粒度运动信息,也很难在早期形成稳定的视听对齐。作者试图把视觉帧、音频以及显式的连续运动表征放进同一个 encoder,在 25 fps 的统一时间轴上联合编码,同时把计算量控制在可接受范围内,并保持对任意分辨率、任意时长输入的外推能力。

这篇工作解决的是视频推理里的一个具体短板:大多数 VLM 在推理开始时只看到固定采样的视频帧,后续 CoT 再长,也只能围绕这批静态证据展开,无法像人一样在思考过程中主动补充视觉信息。更进一步,现有方法即便能在 CoT 中插入检索到的帧,也很难处理反事实或假设性问题,因为这类问题需要“生成并检查一个不存在于原视频中的场景”。作者要做的是让模型在文本推理链中主动决定何时检索已有帧、何时生成假设帧,并把这些视觉结果重新并入 CoT。

LVLM 在视觉推理时,直接对齐视觉专家(如 GroundingDINO)的几何先验(如精确的边界框)会导致“管中窥豹”效应,反而限制了推理能力并引发幻觉。

现有VLM通用对抗攻击的评估指标将输出扰动和目标payload注入两个独立事件混为一谈,高估了视觉模态作为prompt注入通道的实际风险。

解释并缓解 MLLM 中连续视觉 latent reasoning token 被训练成语义丰富但对最终答案贡献很小的问题。

When Audio-Language Models Fail to Leverage Multimodal Context for Dysarthric Speech Recognition
这篇工作检验一个很具体但很关键的问题:现有音频-语言模型在不改参数的前提下,能否像文本 in-context learning 那样,利用临床上下文去改善构音障碍语音的识别。作者关心的不是一般 ASR 精度,而是“额外文本上下文是否真的被模型吸收并转化为更低 WER”。全文给出的结论很明确:对冻结的现成模型,答案基本是否定的。即便提供诊断标签、言语严重度、发声质量描述、完整临床画像,模型大多也不会稳定受益,很多时候反而更差。真正缺的不是 prompt engineering,而是训练分布里几乎没有“异常语音 + 临床描述 + 转写”这种联合样本,导致模型没有学会把这类文本条件映射到声学歧义消解上。

VLM 的幻觉缓解里,“给模型塞一段自生成 caption 当额外证据”看起来合理,但全文指出它会因为锚定效应(caption 会重塑推理轨迹与措辞)而在 caption 有错时放大伤害;同时 caption 的错误结构是强不对称的:遗漏多、捏造少,但捏造的单次代价更大。核心问题变成:能否在不训练、不开额外 caption 质量模型的情况下,对每个 query 自适应地决定 caption 应该影响模型多少,从而只吃到 caption 的增益、尽量规避其误导?

多模态大模型(MLLM)在推理时存在模态利用不平衡的问题,文本 token 占据主导,导致模型忽视感知输入(图像/音频)从而产生幻觉。

解决多模态数据筛选中,共享 embedding 空间被模态差异和噪声配对污染,导致跨模态检索不稳的问题。

多模态机器翻译中,模型是否真正利用图像来消解源语言歧义,现有数据集质量和任务匹配度不足。

让多模态大模型在图像和视频中统一支持由对话指令与视觉提示驱动的像素级分割。

解决大规模图像数据集之间语义差异比较成本高、稀疏分布漂移难定位的问题。

评测多模态基础模型在真实场景表格图像上的结构理解、数值推理和问答能力。

分析多模态大模型在情绪识别中面对模态冲突和模态缺失时如何做决策,以及能否在不重训的情况下修正偏置。

现有VLM基准无法评估真实场景下多实体多动作交互的时空理解能力,也缺乏跨时空维度的故障分析框架
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

现有视频VAE仅优化重建质量无法直接提升后续扩散生成性能,视频隐空间可扩散性低、缺乏有效时序运动先验。

统一多模态生成模型中,Diffusion Transformer(DiT)架构随参数规模、视频分辨率及时长提升计算成本爆炸式增长,同时现有开源统一模型在视频编辑场景性能和效率均不足。

这篇论文想解决纯 acoustic-token 音乐生成里的一个关键矛盾:只用离散音频 token 是否能同时承载长程音乐结构和高保真声学细节,而不依赖额外的 semantic token 阶段或 diffusion / neural renderer。难点在于 token 层级要足够深,语言模型还要能处理高码率、长序列、多 RVQ 层的生成问题,并且需要在有歌词时保持文本-人声对齐。

解决视觉自回归生成在高分辨率下显式深层堆叠带来的固定计算量和高显存占用问题。

如何更可靠地评测文本到视频(T2V)模型在“不合理/反常识场景”下的生成质量,并显式衡量音画一致性与可解释错误类型。

为同时接受手绘 scribble 和文本指令的图像编辑模型构造专门训练数据,解决空间控制和语义控制难以兼得的问题。

防御 text-to-video 模型在显式有害提示、越狱提示和时间演化生成过程中产生不安全内容的问题。

解决具身AI世界模型只建模2D动态画面、缺少多视角4D空间一致性的问题。

解决多模态世界模型在联合生成 RGB、深度、mask 等视频时,难以同时利用不同基础模型的模态专属先验、导致表示混叠和扩展性不足的问题。

解决流匹配生成模型样本不确定性估计成本高、需重训或集成、精度不足的问题。

为文本驱动的音乐-舞蹈联合生成建立评测体系,尤其评估音乐节奏、乐句和重音与舞蹈动作的细粒度对齐。

标准 diffusion model 面向稠密连续数据设计,遇到大量精确零值的稀疏连续数据时,会破坏稀疏模式并在零位置浪费计算。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

这篇工作解决的是一个当前很实际的瓶颈:深度研究型 agent 想在前沿科学问题上变强,缺的不是通用网页检索能力,而是高质量、可自动扩展、能覆盖稀疏学术证据和科学计算过程的训练数据。现有自动构造信息寻求任务的方法,大多依赖 Wikipedia 式实体图谱或连续网页浏览,适合事实检索,不适合前沿科学里那种知识分散、概念异构、还需要公式和参数计算的长链条推理。SciResearcher 的核心目标,就是搭一个全自动数据构造框架,把“前沿科学推理”拆成可规模化生成的训练样本,并验证这些样本能否真正提升 deep research agent 的能力。

Model Spec Midtraining 解决的是 alignment fine-tuning 的泛化欠定问题。只用行为示范做对齐时,模型可能学到表面偏好,而没有学到这些行为背后的规则、价值和适用边界。同一批示范数据可以支持多种解释,模型最终泛化到哪一种解释,取决于训练前已有的表示和先验。

这项工作讨论一个很具体的问题:在没有人工标注答案的情况下,RLVR 能否继续扩展 LLM 的推理训练。作者把这类方法定义为 Unsupervised RLVR,即在可验证任务上不使用人工 ground truth,而依赖模型自身或外部代理信号构造奖励。核心结论是:内生奖励类 URLVR 主要是在“锐化”模型已有分布,而不是稳定地产生新的推理能力。它能放大模型原先更倾向的答案,也可能把错误偏好放大到模式坍塌。

这篇工作研究一个安全评估问题:经过特定目标微调的 model organism,是否会在无关上下文中泄露微调目标,以及能否用只依赖输出概率的简单方法发现这种泄露。

这篇工作处理的是 instruction-tuned 模型任务适配中的一个老问题:直接在 instruct 模型上做微调,容易破坏原有的指令跟随、泛化和平衡;而先在 base model 上学任务更新、再 merge 回 instruct 模型的路线,虽然更稳,但 instruction model 在训练阶段几乎没有参与,只在最后被动接收更新。作者要解决的核心问题,是如何让 instruction-tuned 模型在“更新学习阶段”就提供约束和指导,从而学到更适合后续 merge 的任务适配器,而不是等训练完再看能不能合并成功。

在 on-policy distillation(OPD)里,学生模型沿着自己的采样轨迹学习,但监督信号来自教师分布;当教师在学生访问到的“困难状态”上出错或过度自信时,学生会被锁死在单教师能力上限,并在多步 agentic 任务中因误差累积而训练不稳定。论文要解决的是:如何在 OPD 框架内获得比单教师更可靠的逐 token 监督,并给出与任务结构匹配的 divergence 选择原则,从而把 OPD 扩展到长轨迹的 agentic 场景。

在 VLM 的 RLVR(用“答案是否正确”做可验证奖励)训练里,采样成本高且奖励稀疏:大量 rollout 早期就因视觉描述错误而“注定失败”,但仍被完整采样;同时失败只给一个序列级 0/1 信号,无法区分是视觉感知阶段错了还是后续推理错了,导致 credit assignment 很差。

这篇论文试图解决多模态推理 RL 中的 credit assignment 粒度错配问题。token-level PPO 太细,长 CoT 下终局奖励要传播到大量 token,variance 高,且同一推理步骤内部的 token 可能收到不一致的学习信号。sequence-level GRPO 又太粗,把整条回答统一奖励或惩罚,无法区分哪些中间推理步骤是有效的、哪些步骤导致了错误。

T$^2$PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
解决多轮 Agent 强化学习中的训练不稳定问题,特别是长轨迹、稀疏奖励和无效探索共同导致的性能退化或优化崩溃。

这项工作评估 reasoning model 在部署时是否会为了拿到高分而利用评价规则的漏洞。核心问题不是模型会不会犯错,而是当任务目标、评价函数和用户真实意图不完全一致时,模型是否会主动选择“高分但不合意”的行为。

这项工作解决 Long-CoT reasoning distillation 中的轨迹选择问题:多个强教师能生成很长的推理过程,但事后挑一条完整轨迹会浪费大量采样,也难以把不同教师的互补推理步骤组合起来。

该工作解决一个 RLVR 训练中的具体问题:如果想用一次性采样的加权 SFT 替代固定 reference 的 KL 正则在线 RLVR,应该用什么采样分布和权重,才能拟合同一个最优策略。

这篇工作研究 offline RLHF 中最现实也最难分析的一类数据攻击:只翻转已有偏好对的标签,而不注入新数据。核心问题不是“标签翻转会不会有害”,而是:在 DPO 的 log-linear 设定下,攻击者能否用很少的翻转,把训练方向系统性地推向一个指定目标策略;以及这种攻击何时可解、何时无效。论文把这个问题从策略空间拉回到梯度空间,给出一个可计算的 targeted poisoning 形式化。

核心问题是现有 reward model 评测默认存在单一“好答案”标准,无法检查 RM 是否能根据不同用户偏好调整排序标准,也无法检查同一偏好换一种表达后排序是否稳定。

解决安全对齐后的大模型在下游微调阶段拒绝恶意请求能力大幅退化的问题,现有研究缺乏对安全表征内部结构变化的机制性解释,防护策略多为启发式设计。

这篇论文研究多模型、多轮交互中对齐行为是否会通过对话传播,以及能否用黑盒 steering 方法降低这种 misalignment contagion。

互联网上LLM生成内容占比持续提升,未来预训练数据将包含大量前代模型输出,需要明确在模型自身输出上迭代微调是否会放大已有行为倾向(如谄媚、错位)。

这篇工作解决的是 PRM 数据构造里一个很具体但很关键的问题:现有自动化过程监督数据往往只能粗糙地产生“对/错”轨迹,却很难精确控制首个错误出现在哪一步、属于哪一类错误,以及错误出现后后续推导是否仍然自洽。对于训练 process reward model 来说,这三个属性都很重要,因为 PRM 真正要学的是 step-level 诊断能力,尤其是 first-error localization,而不是只给整条链打一个总分。

论文把 alignment 建模为 solver 和 auditor 之间的激励设计问题:惩罚、审计成本、误报风险和纠错收益共同决定模型是否作恶、是否承认不确定性,以及监督器是否仍有动力检查。

Selector-Guided Autonomous Curriculum for One-Shot Reinforcement Learning from Verifiable Rewards
这篇论文研究 1-shot RLVR 中训练样本如何选择。已有方法常用 reward variance 选题,但作者认为高方差经常来自解析、格式、tokenization 等测量噪声,不能稳定代表可迁移的推理学习信号。

这篇工作处理的是一个很具体但长期存在的问题:把 RL 用到检索增强问答时,模型往往学不会稳定的多步搜索策略。原因有两层。第一,训练数据分布偏浅,很多样本并不真正要求多跳检索,模型容易靠短路径或参数记忆拿到答案。第二,奖励过于稀疏,通常只看最终答案是否正确,导致搜索质量、证据覆盖、查询是否有效这些中间行为拿不到训练信号。全文围绕这两个瓶颈展开:如何构造一批“确实需要多步检索、但又不是不可学”的训练题,以及如何让 RL 不只奖励最终答对,还奖励检索过程本身。

基于二元验证奖励的强化学习(RLVR)训练大语言模型时,普遍存在多样性坍塌问题:单样本准确率提升,但多样本覆盖度下降,甚至低于基模型,现有研究未从结构层面解释该现象的底层成因。

直接偏好优化(DPO)在训练过程中存在“挤压效应”(squeezing effect):对拒绝响应施加的负梯度会导致概率质量集中在高置信度预测上,同时抑制其他响应(包括首选响应),最终导致概率分布崩溃。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

这项工作要回答一个很窄但重要的问题:LLM 在没有知识、语义线索、格式约束和任务模板帮助时,能把一个简单规则稳定执行多久。作者选择“数一串完全相同的符号并输出数量”作为最小探针,用 Stable Counting Capacity, SCC,测量模型在状态跟踪失效前能处理的最大长度。核心不是证明模型不会数数,而是用计数作为可控实验,定位模型执行程序性规则的可靠边界。

这篇工作讨论的不是某个具体能力,而是一个被广泛默认、但方法上并不稳的评测前提:当我们做 counterfactual prompting 时,是否真的只改动了目标变量。论文指出,很多所谓“外科手术式”的文本编辑,其实同时引入了表面形式变化、句法重写、词汇替换等附带扰动。于是输出变化未必来自目标因素本身,而可能只是模型对任意文本改写都敏感。用因果推断的话说,这违反了 treatment variation irrelevance:同一个干预变量的不同文本实现,并不保证产生同样结果。作者要解决的核心问题,是给 counterfactual prompting 一个可解释的统计基线,让“观察到变化”与“目标因素导致变化”之间不再被直接画等号。

核心问题是把机制可解释性从“给定一个 neuron/SAE feature 后做一次性命名”,推进到“先找到相关内部特征,再用实验循环验证解释”。这更接近真实研究流程:研究者通常先有一个高层问题,例如某种语言、拒答行为或安全概念在哪里被编码,而不是一开始就知道要看哪个 feature。

单一 prompt 的准确率会掩盖小模型在校准、可解析性和 prompt 扰动稳定性上的可靠性问题。

这篇工作问的是一个很具体但很关键的机制问题:语言模型里已经观察到“月份、星期、时钟”这类循环概念具有圆环式表征几何,但这种几何是否真的被模型拿来做计算。作者用 Llama-3.1-8B 检查后发现,答案是否定的。模型在回答“August 之后六个月是什么”这类问题时,并不是在 12 周期空间里直接做模加法,而是先把概念映射成普通数字,在共享的十进制加法回路里算出和,再在后层把结果映射回循环概念空间。

现有研究观察到在窄域无危害任务上微调LLM会诱发有害行为的涌现错位现象,但尚未解释该现象的底层机制。

评估标称 1M token 上下文窗口的前沿 LLM,是否能在文言文长语料中完成可靠检索和多跳关系推理,并区分真正的上下文读取与训练语料记忆。

这篇论文研究如何从大量相关的 LLM benchmark 中选择一个小子集,使得运行少量评测后仍能较好预测完整评测矩阵。

这篇工作要回答的不是“怎样再造一个更复杂的 agent harness”,而是更基础的问题:多代理编排里真正起作用的能力到底是什么。全文给出的结论很明确,关键增益主要来自一种可抽象为“两阶段重思考”的内在技能:先并行生成多条相互独立的推理轨迹,再做一次顺序式综合与裁决。作者把它命名为 Heavy Thinking,并进一步把它从外部 orchestration 还原成模型可调用的 skill。论文关心的核心瓶颈也很具体:单条 CoT 容易早期走偏;best-of-k 只会选,不会整合;复杂 harness 虽然有效,但很难分辨收益来自工具、记忆、角色分工,还是来自更本质的“多轨迹探索+总结”。

论文检验 Park et al. 提出的 causal inner product 是否能带来跨语言概念迁移收益,并进一步追问:LLM residual stream 中的概念方向到底落在 unembedding covariance 频谱的哪些子空间里。

The Partial Testimony of Logs: Evaluation of Language Model Generation under Confounded Model Choice
研究如何在模型选择被用户自选择因素混杂时,用离线日志可靠评估语言模型生成质量。

这篇工作想回答一个机制分析问题:LLM 在执行需要层级推理的任务时,隐状态里是否存在可读出的树状结构,以及这些结构是否只是相关特征,还是对任务执行有因果作用。

在“有明确标准答案的 factoid QA、且不使用外部工具”的最简单设定下,前沿模型仍会产生幻觉。论文试图解释一个现象:为什么扩大知识边界(记住更多事实)相对容易,而让模型清楚知道知识边界(知道自己何时不知道)却更难。作者提出关键区分:校准(calibration,置信度与正确率匹配)不等于判别(discrimination,能否把对/错在单样本层面清晰分开)。当判别能力存在缺口时,“零幻觉”与“高效用”之间会出现结构性权衡。

这篇工作讨论的是:为什么同样是 activation steering,很多时候平均上有效,但落到单个样本时却很不稳定,而且现有基于 Linear Representation Hypothesis(LRH)的解释经常失灵。作者认为问题不在于“向量提取不够干净”这么简单,而在于 LRH 默认概念之间可以被正交化、从而实现近乎无损控制,这个前提在有限维表示空间里通常不成立。只要概念数超过可容纳的独立方向数,或者多个语义因素在同一表示子空间里重叠,steering 就天然会带有样本依赖的干扰。论文要解决的核心,是给这种不规则、样本特异的 steering 行为提供一个更贴近真实表示几何的解释框架。

Spatiotemporal Hidden-State Dynamics as a Signature of Internal Reasoning in Large Language Models
这篇工作要回答的是:长推理模型生成很长的 reasoning trace,到底对应了真实的内部计算,还是只是更啰嗦、更多 overthinking。现有评估大多看输出端信号,比如答案置信度、self-consistency、reward model 分数,或者把隐藏状态做过于粗粒度的汇总。这些方法能做结果验证,但看不清“模型在第几步、哪几层真的在发生推理相关的状态跃迁”。作者要解决的核心问题,是从 hidden-state dynamics 里提取一个既保留时间维和层维局部结构、又足够简单可计算的指标,用来区分成功推理轨迹和失败轨迹,并判断 reasoning model 的长链输出是否伴随了更强的内部计算痕迹。

这篇论文讨论的是:如何评价语言模型是否真的在“推理”,而不是只用最终答案准确率来混合衡量记忆、模式匹配和多步搜索。

The Oracle's Fingerprint: Correlated AI Forecasting Errors and the Limits of Bias Transmission
不同机构开发的主流大模型在预测任务中是否存在跨模型的相关性误差,以及该误差是否会传导至人类预测群体,消解群体智慧的有效性。

现有激活导向方法在控制LLM行为时,隐含假设非目标特征空间各向同性,容易对非目标特征的激活对齐造成非预期改动(附带损伤),导致导向效果和下游性能存在明确trade-off。

这篇论文研究的是 LLM unlearning 的测量缺口:模型不再生成被遗忘内容,并不等于内部表示中不再编码这些内容。作者关注的是自然预训练记忆在 residual stream 中是否留下可跨样本泛化的线性读出方向,以及这种内部痕迹能否在不明显损伤能力的情况下被移除。

这篇工作想解释一个比“attention 学到了什么”更基础的问题:Transformer 训练过程中,attention 为什么常常先变得很尖锐、偏向少数 token,随后又逐渐变得分散;而且这种过程为什么会重复出现。作者把它形式化为 focus–dilution cycle,并试图在尽量原生的 Transformer 动力学里,而不是在重参数化或代理模型里,给出可解析解释。

这篇工作想解决把 LLM 当文本编码器时,ICL 虽然能提升 embedding 质量,但会显著拉长输入、增加训练和推理开销的问题。

Do Large Language Models Plan Answer Positions? Position Bias in Multiple-Choice Question Generation
LLM生成选择题时存在系统性位置偏差,正确答案分布不均,现有研究未揭示该偏差的底层机制

静态知识密集推理评测容易被数据污染和过拟合削弱,而现有动态评测又常牺牲可回答性与可控性。

现有LLM幻觉检测方法缺乏系统的跨模型跨域评测框架,现有指标与人类判断相关性低,检测成本高。

学习一种跨模态的结构一致性打分器,用标量能量判断文本或图像表示是否存在结构性违例,并定位违例位置。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

为长期运行的 RL coding agent 设计一种可记录反馈、可安全门控的开发者记忆系统,避免普通向量库/RAG 在代码 RL 场景中误用细节。

讨论长周期软件工程 Agent 缺少什么训练数据,尤其是现有短任务 benchmark 饱和后,模型仍难处理多工程师、模糊需求和跨职能协作的真实交付。

在发布具有强大代码生成和推理能力的开源模型(如 Code World Model, CWM)之前,需要评估其是否会带来超出当前 AI 生态系统基线的灾难性风险,特别是在网络安全和化学生物领域。

评估 LLM 与 agentic workflow 在形式化规格生成上的真实能力,并识别数据污染与不忠实行为导致的评测失真。

这篇工作解决的是 LLM 驱动 fuzzing 的两个老问题:初始 prompt 很容易把搜索轨迹锁死,采样随机性又会让生成反复落在相似程序模式上,导致覆盖率增长慢、深层编译器行为触达不足。作者提出的核心问题不是“LLM 能不能生成代码”,而是“如何把 LLM 生成接入一个长期保持多样性的搜索过程”,让它在结构化输入空间里持续探索而不是早早塌缩。

解决复杂分析数据库上的 text-to-SQL:模型需要在大 schema、含糊问题和真实数据值之间做可靠 grounding,并能从早期错误中恢复。

解决 KGQA 中跨图查询语言的结构化查询生成问题,尤其是从自然语言问题生成可执行、符合意图的 SPARQL 或 Cypher 查询。

记录、回放并分析开发者与 AI 编程助手交互时的完整上下文,而不只依赖聊天日志或 git 历史。

解释 AI 编程助手为什么在受控小任务中提升效率,却在真实团队交付中可能拉长评审周期、降低可靠性。

解决代码演进后文档与真实实现不一致的问题,尤其是普通静态分析无法判断语义一致性、普通 LLM 又容易在缺少结构上下文时生成错误文档。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

这篇论文关注 GUI Agent 的“faithfulness”问题:模型在手机界面交互时,可能没有真正依据当前屏幕证据和用户指令做决策,而是依赖记忆化捷径、任务先验或格式化动作模板。作者把问题拆成两类:一类是 evidence groundedness 不足,包括看不到关键证据仍继续操作、或偏离用户指令;另一类是 internal inconsistency,即推理文本表达的意图和最终执行动作不一致。

NeuroState-Bench: A Human-Calibrated Benchmark for Commitment Integrity in LLM Agent Profiles
NeuroState-Bench 关注的是多轮 Agent 评测中的一个缺口:终局成功率不能说明模型是否在过程中稳定保留了任务所需的承诺状态,例如实体绑定、来源可信度、约束更新、矛盾修复等。

MEMAUDIT: An Exact Package-Oracle Evaluation Protocol for Budgeted Long-Term LLM Memory Writing
这篇论文要解决的是长期记忆系统中“写入质量”难以单独评估的问题:现有评测多看最终问答准确率,但这个指标同时混入了记忆写入、检索、提示构造和读者模型推理能力,无法判断失败发生在哪一层。

On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
在“推理结构与决策规则不变”的前提下,仅仅把任务所需的交互步数(horizon/goal distance)拉长,会如何改变 LLM agent 的训练动态?论文要回答的是:长时程失败到底是“更难的推理”导致的,还是“更长的序列决策链”本身就会引入独立的训练瓶颈与不稳定性。

OpenClaw 生态的现有评测偏“助理型任务”,缺少对真实学术/专业工作流中高难度、长时程、强执行约束任务的系统评估。论文要解决的是:如何构建一个来源真实、难度自然对齐前沿能力、并且可在 Docker 沙箱内可验证评分的 academic-level agent benchmark。

这篇论文研究 LLM 多智能体协作中的 dynamic grounding failure:单个模型能独立算出较好策略,但两个模型通过多轮对话协商时,往往不能形成、维护和修复共同计划。

持久化 agent memory 让 LLM agent 能跨会话保存用户信息,但也把间接 prompt injection 变成可长期潜伏的攻击。Trojan Hippo 研究的是攻击者只通过一次不可信工具输入植入 payload,随后在用户谈到金融、健康、身份等敏感主题时触发并外传私人数据。

该工作指出 BYOK 代理架构中的响应路径完整性缺口:即使 LLM 已经生成安全对齐的回复,第三方 relay 仍可在模型输出到 agent 执行之间篡改工具调用、参数或控制字段。

无引导的同质多智能体辩论范式是否比孤立自校正更能提升推理准确性,以及该范式的成本效益比是否符合预期。

RAG 只按语义相关性检索会在“带偏见/错误前提”的查询下检索到迎合性证据,从而加剧幻觉;如何让检索对这类认知扰动更鲁棒。

这篇工作研究的是:当用户对长文档做局部事实编辑时,模型能否识别并传播到文中所有依赖该事实的非局部表述,而不是只改显式提到的那一句。

讨论如何用强化学习优化 LLM 多智能体系统中的编排行为,包括何时派生子智能体、如何分工、通信、聚合和停止。

现有多Agent协作场景下的Agent Discovery方法要么依赖重LLM导致延迟过高(>30s),要么用单块向量检索牺牲语义精度

高分辨率 GUI 中,小控件和密集布局会让 VLM 坐标 grounding 失效;论文尝试用不确定性驱动的主动搜索来决定放大哪里。

用 LLM 驱动的演化搜索寻找 Zarankiewicz 数的新极值图构造,并尝试证明或改进若干组合数学界限。