★+4111.3k
RustCoding Agentv0.11.1
面向终端的多会话编码Agent框架(jcode)。
对比多款CLI,给出RAM/启动耗时数据;适合多会话工作流与低资源环境。
⚙ Rust实现TUI/PTY交互;会话可扩展,支持可选本地embedding以控内存。
- v0.11.1 (2026-04-28)
- TTF 14.0ms;首输入48.7ms(10次PTY)
- 1会话PSS 27.8MB(关embedding);每加会话~9.9MB
更新时间: 2026/4/30 00:30:30
方法或结果明显独立成立的工作,建议读全文
OpenAI 讨论为持续扩展 AI 能力而建设更大规模计算基础设施的问题,重点是 Stargate 和新增数据中心容量。
构建开放的多语言 sparse MoE 语言模型,并验证极高稀疏度、dense-to-MoE upcycling 和长 token 训练能否同时带来 compute efficiency 与多语言能力。
掩码扩散语言模型(MDM)作为自回归大语言模型(AR-LLM)的替代范式存在训练不稳定、在强左向token依赖任务上表现差的问题,现有块结构混合模型未显式注入token级左向局部归纳偏置,无法同时兼顾左向依赖任务和全局约束生成任务的性能与训练稳定性。
解决全模态大模型的实际落地痛点:跨模态对齐效果差、训练不稳定、长多模态序列推理效率低、多模态输入吞吐能力不足。现有全模态模型普遍存在推理延迟高、模态覆盖不全、长上下文多模态任务性能弱的问题。
现有RLHF等大模型强化学习流程普遍使用不完美代理奖励,传统奖励质量评估指标(如排序准确率、MSE)将所有奖励误差都视为有害,忽略了不同误差对策略梯度优化过程的差异化影响,也无法解释部分代理奖励效果优于真实奖励的现象。
论文解决的是 reasoning model 后训练中的一个具体优化问题:只有输出级监督时,RLVR 在初始成功概率 p0 很小时会启动很慢;但直接做 latent trajectory 的边缘似然训练又更容易记住错误标注。作者用一个连续损失族刻画这两种训练信号之间的取舍,并解释模型应该多快“承诺”到监督信号上。
这项工作研究一个对 post-train 和 pretrain 接口都很关键的问题:为什么同样从基座模型出发、使用相同训练数据,RL 往往能带来跨任务泛化,而 SFT 更容易引入任务特化和能力遗忘。作者不只比较外部指标,而是把 base、SFT、RL 模型的内部激活对齐到同一个稀疏特征空间,观察训练范式如何改写表示。
论文处理的是一个很具体但关键的问题:CoT 让 Transformer 在表达能力上可以模拟图灵机,但这种能力是否能从有限长度的训练轨迹中学到,并外推到更长推理长度,并不成立。作者把问题从“存在一个 Transformer 可以表达某种计算”收紧到“标准 Transformer 在有限训练分布上能否学到可长度泛化的 CoT 计算”。在标准位置编码和有限 alphabet 条件下,结论偏负面:即使给 CoT,长度可泛化的可学习任务仍然落在 TC0 附近,不能自动获得图灵完备推理能力。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

OpenAI 讨论为持续扩展 AI 能力而建设更大规模计算基础设施的问题,重点是 Stargate 和新增数据中心容量。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

构建开放的多语言 sparse MoE 语言模型,并验证极高稀疏度、dense-to-MoE upcycling 和长 token 训练能否同时带来 compute efficiency 与多语言能力。

掩码扩散语言模型(MDM)作为自回归大语言模型(AR-LLM)的替代范式存在训练不稳定、在强左向token依赖任务上表现差的问题,现有块结构混合模型未显式注入token级左向局部归纳偏置,无法同时兼顾左向依赖任务和全局约束生成任务的性能与训练稳定性。

ADE 处理的是词表嵌入层的表达瓶颈:单个 token 只有一个向量,难以同时承载多义性、句法角色和组合语义;已有 codebook / multi-anchor embedding 又多停留在静态词级组合,难以放进现代 Transformer 并高效训练。

Probabilistic Transformer 在放大规模时对超参很敏感,难以像标准 Transformer 那样稳定扩展;这篇工作要解决其跨尺度可训练性问题。

在小参数与严格推理预算下,如何同时获得长上下文的高效状态跟踪能力与注意力的选择性路由能力;以及小模型在低成功率阶段做 GRPO 类 RL 时,如何避免负优势梯度主导导致能力退化。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

这篇论文讨论深度剪枝中的一个基础假设:Transformer 层冗余是否是预训练模型自身的固定结构属性。作者给出的答案是否定的。层是否可删,取决于模型、校准数据和校准目标三者的组合。用语言建模 perplexity 找到的冗余层,未必适合保留下游推理能力。

这篇工作要回答的是:面向 test-time scaling 的推理型 LLM,剪枝是否一定会伤害长链推理能力。已有结论主要来自结构化剪枝,也就是直接删整层或整块网络,因此观察到随着推理 token 预算增加,模型在数学和复杂推理任务上的收益明显变差。作者重新检查这个结论,问题被收紧为:如果不改网络拓扑,只做非结构化剪枝,把单个权重置零,是否仍然会破坏 TTS 带来的性能增益,以及不同层的稀疏率分配会怎样影响这种关系。

论文解决的是 multi-agent LLM 应用的 serving 问题:现有 serving 系统把 agent 工作流当成普通随机流量处理,忽略了 agent 图结构、角色分工和执行模式带来的可预测性,导致 prefix cache、调度和扩缩容效率低。

这篇论文解决多 agent 推理中的 KV cache 内存重复问题。多个 agent 读取同一长文档上下文时,常规做法会为每个 agent 分别保存一份 KV cache;PolyKV 改为只预填充一次,保存一个压缩后的共享 KV 池,再注入到多个独立 agent 的 cache 中。

现有通用音频基座模型参数量大推理成本高,此前音频领域知识蒸馏方法依赖监督信号、模型logits或层级对齐,无法适配仅输出embedding的自监督音频模型

研究 compound AI systems 在生产环境中如何服务多模型、检索器和工具组成的异构推理工作流,同时控制延迟、吞吐和成本。

评估小参数 LLM 在带硬件加速的单板计算机上本地推理时,如何同时权衡吞吐、延迟、能耗、成本和硬件利用率。

解决长上下文解码阶段 attention 对 KV cache 带宽和计算的压力,尤其是现有加速器在长序列下性能明显退化的问题。

解决FlashAttention的在线softmax依赖浮点运算导致无法实现端到端整数量化的问题

解决移动端单NPU-PIM系统上运行推测解码时,同步执行空闲开销大、异步执行无效计算多的问题

针对软件工程场景中 LLM 部署成本、内存占用、延迟和碳排放过高的问题,提出一个压缩流程选择与排序框架。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

解决全模态大模型的实际落地痛点:跨模态对齐效果差、训练不稳定、长多模态序列推理效率低、多模态输入吞吐能力不足。现有全模态模型普遍存在推理延迟高、模态覆盖不全、长上下文多模态任务性能弱的问题。

这篇工作解决的是多模态自动评测里的可靠性问题。VLM judge 通常只给一个离散分数,但这个分数没有不确定性刻画,用户无法知道它是“有把握地打了 4 分”,还是“在 2 到 5 分之间都拿不准,最后碰巧输出了 4 分”。作者关心的不是如何让 judge 更高分,而是如何在不重训模型的前提下,把单点分数变成带覆盖保证的区间,并进一步分析这种不确定性在不同视觉任务上是否有系统差异。

这篇工作研究的是 VLM 的一种具体安全失效机制:把恶意指令渲染成图像中的文字后,模型为什么有时会读出来并执行,有时又会失败。作者不满足于只做更高攻击成功率,而是想找到一个可解释、与具体目标模型解耦的指标,来刻画 typographic prompt injection 成功与否的原因,并进一步用这个指标做更系统的红队测试。

LVLM 幻觉缓解里,为什么很多 decoding-time steering(DTI)虽然降低幻觉频率,却会让剩余幻觉更“严重”、更容易滚雪球;以及能否在不改参数的前提下,从源头阻断这种自回归误差累积。论文把关键矛盾定位在干预时机与对象:在 decoding 阶段持续加 steering,往往是在错误表征已经形成后被动补救,且对多模态对齐与细粒度视觉证据不够敏感。

评估 VLM 在图表、地图、信息图、线路图和科学图示等 diagram QA 中是否真正定位到支撑答案的视觉证据,而不只是答对问题。

开放世界视频时间定位中,现有数据集规模和语义覆盖不足,导致模型对长尾概念和复杂文本查询的定位能力差。

解决现有VLA模型采用单块生成范式忽略机器人操作层级性,导致语义到动作映射鸿沟大、表示负担重的问题

现有的统一多模态模型(uMMs)评估协议独立测试视觉理解和生成能力,无法衡量这两种能力在语义上是否一致。

现有的 VQA 数据集侧重于粗粒度类别和单实体的简单推理,无法有效评估多模态大语言模型(MLLMs)在细粒度多模态实体理解和复杂多跳推理上的能力。

GPT-Image-2生成的伪造文档缺乏公开评测数据集,且其自检测能力未被系统性验证

改进大多模态模型在跨模态检索中的细粒度对齐,缓解模型忽略视觉区域、过度依赖文本线索的问题。

解决 VLM 在指令跟随时语言先验过强、输出流畅但缺乏视觉证据支撑的问题。
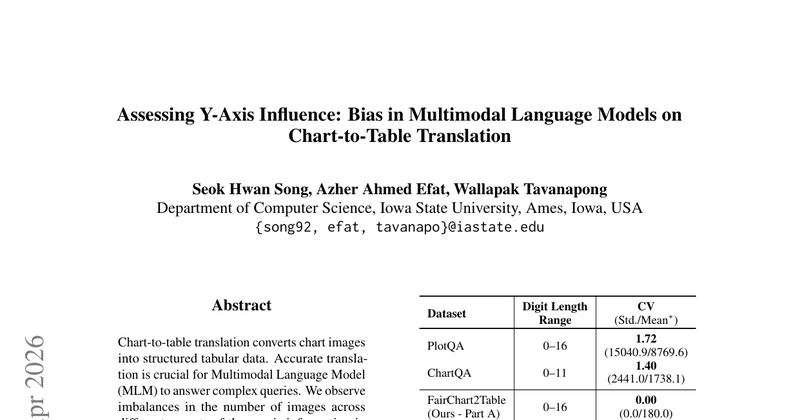
现有公开图表数据集的Y轴信息分布不平衡,导致多模态大模型在图表转表格任务上存在未被系统研究的Y轴相关偏见

评估程序性视频 caption 的事实一致性,尤其是模型是否漏掉关键动作、工具、食材、地点,以及这些角色是否和视频证据对齐。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

这篇工作要解决的不是“怎么再做一个视觉偏好优化算法”,而是一个更具体的扩展性问题:当偏好数据规模变大时,为什么现有 Diffusion-DPO 一类离线偏好学习方法并没有稳定变好,甚至会很快饱和。全文给出的答案是,现有开源视觉偏好数据里存在大量冲突型偏好样本:胜者图像可能在审美上更好,但在文本对齐、结构完整性、细节保真等维度更差。DPO 把这类二元偏好当成单一、干净、可传递的监督信号来学,会把互相矛盾的梯度混在一起,结果是随着数据增加,模型并没有学到更清晰的偏好边界。作者进一步指出,问题不只在算法,也在数据:旧数据集分辨率低、prompt 覆盖窄、类别分布不平衡,而且很多样本来自较早期生成模型,偏好信号本身就不够稳定。

这篇工作要解决的不是“如何把扩散模型做得更大”,而是一个更具体的问题:扩散式文生图模型在复杂文本约束下,往往缺少类似语言模型那种可递归、可分步的内部推理过程,因此对结构布局、对象关系和细粒度文本跟随的处理不稳定。作者关注的是 joint attention 这一层里视觉 token 与文本 token 对齐的关键位置,试图让模型在一次去噪步内部再做多次轻量递归更新,而不是只靠单次前向把跨模态对齐一次性做完。难点在于视觉 latent 是连续表示,不像离散文本 token 那样容易做显式 reasoning;如果直接堆更多层或更多 denoising steps,计算代价又很高,且不一定把额外算力用在真正需要推敲的局部结构上。
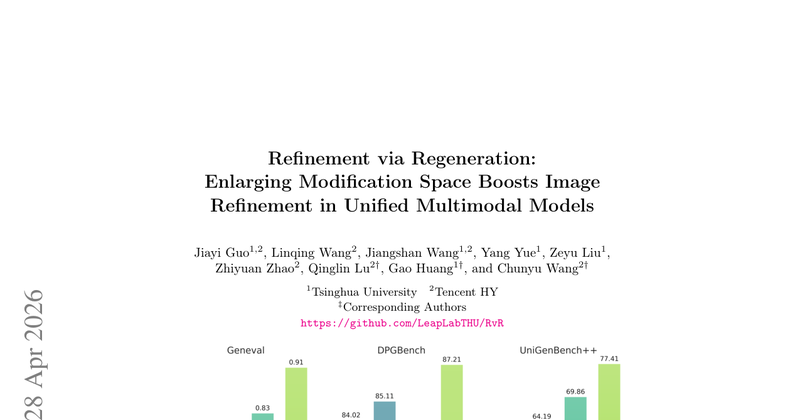
统一多模态模型(UMM)做 T2I 生成时,如何把“初次生成的图”进一步提升到更高的 prompt 对齐上限。论文指出主流的“先理解差异→生成编辑指令→局部编辑”(RvE) 会被两类约束卡住:编辑指令对 mismatch 的描述天然粗糙且不完备;编辑任务要求未编辑区域像素级保持,导致可修改空间过小,难以做结构性修正(多物体、关系、布局类 prompt 尤其明显)。

解决原生音视频联合生成的三个核心问题:跨模态联合训练优化难度高、自回归流式生成采样速度慢、训练推理不一致。现有方法要么局限于窄域数据集,要么需要多阶段蒸馏从双向模型转换为因果生成器。

解决非 Indic 原生的冻结 TTS 基座在 Telugu、Tamil、Hindi 上无法直接建模脚本与口音的问题,目标是在不重训声学解码器、且不使用商业训练数据的前提下逼近商用品质。

让 AR 图像生成在分辨率/长宽比上“动态可变”,并通过更短 token 序列降低高分辨率生成的计算与序列长度瓶颈。

现有扩散模型DPO训练将多维度人类视觉偏好压缩为二元标签,产生严重标签噪声与冲突梯度,误导模型训练

解决组合式文本到图像生成中,多区域、多实体 prompt 难以被同一个全局起始噪声充分表达的问题。
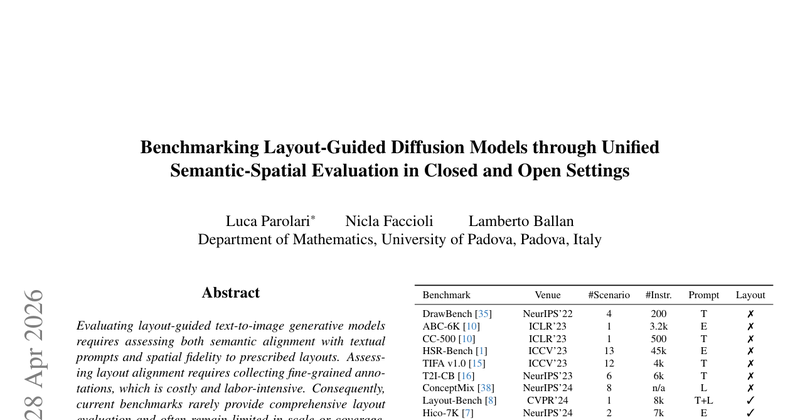
评估 layout-guided text-to-image diffusion 模型时,现有指标难以同时衡量文本语义对齐和空间布局一致性,且细粒度标注成本较高。

视频生成模型中人体动作质量很关键,但现有视频指标偏向全局场景统计,不能细致评估人体结构、姿态和运动稳定性。

解决视频扩散模型从预训练能力到真实产品可用性之间的落差,重点是提示词敏感、时间不一致和推理成本高。

解决图像编辑模型在需要复杂推理和计划时,最终图像质量高但编辑步骤不可靠、难以归因的问题。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

现有RLHF等大模型强化学习流程普遍使用不完美代理奖励,传统奖励质量评估指标(如排序准确率、MSE)将所有奖励误差都视为有害,忽略了不同误差对策略梯度优化过程的差异化影响,也无法解释部分代理奖励效果优于真实奖励的现象。

论文解决的是 reasoning model 后训练中的一个具体优化问题:只有输出级监督时,RLVR 在初始成功概率 p0 很小时会启动很慢;但直接做 latent trajectory 的边缘似然训练又更容易记住错误标注。作者用一个连续损失族刻画这两种训练信号之间的取舍,并解释模型应该多快“承诺”到监督信号上。

这篇工作处理的是 autoformalization 里一个长期缺位的问题:模型把自然语言翻成形式逻辑后,怎样在没有人工 gold formalization 的前提下判断“语义是否忠实”,以及一旦不忠实,错误究竟出在 formalize、back-translate 还是 re-formalize 哪一段。现有评估多看语法合法、可执行、或下游任务是否跑通,但这些都不能直接回答语义保真。作者提出的 roundtrip verification 把“原始形式化结果”和“回译再形式化结果”做语义等价检查,用可判定的 formal tool 给出一个弱监督验证信号;若不等价,再做 stage-level diagnosis 和 scoped repair,而不是整条链路重生一遍。

这篇论文关注 weak-to-strong alignment 的失效诊断:当弱监督模型在某些样本区域不确定或有盲区时,强模型可能学到一个表面更自信、但实际错误的策略。论文试图用偏差、方差、协方差分解来解释这类风险,而不是只看整体准确率或弱强模型是否一致。

这篇工作要解决的问题不是“如何做更好的可解释性分析”,而是更进一步:怎样把机制可解释性里识别出的内部特征,真正转成可执行的训练决策,尤其是数据选择。作者关注的是一个常见断层:SAE、feature steering、causal tracing 这类方法能告诉我们模型里“有什么机制”,但很少告诉我们“接下来该拿哪些数据去强化这些机制”。IGDS试图把这一步补上:先找出与目标任务表现存在因果关系的内部特征,再用这些特征给候选训练样本打分,挑出能强激活这些特征的‘Feature-Resonant Data’做SFT,从而在更少数据下得到更好的任务提升。

这篇工作处理的是 label-free RLVR 里的一个核心矛盾:不用人工答案标签,训练成本会低很多,但如果奖励来自多数投票或 LLM judge,就容易把‘看起来一致’误当成‘真的正确’,从而产生假阳性奖励,最后把策略往错误方向推。作者要解决的不是一般意义上的RL稳定性,而是 machine-checkable 任务中,怎样在没有 ground-truth label 的情况下,同时满足三件事:可扩展、与真实正确性对齐、训练时梯度不塌。

领域语料微调/持续补数通常是开环:评测发现模型缺陷,但无法定位到训练数据哪里缺、该补什么。论文要解决的是:让“训练数据构造”和“评测”共享同一套可追踪的知识表示,从而把数据工程变成可迭代修复的闭环流程。

这篇论文研究一个评测盲区:混入良性数据、事后对齐训练、inoculation prompt 这类常见干预,可以让模型在标准 emergent misalignment 评测上看起来正常,但失配行为仍会被训练上下文相似的提示触发。

论文研究一个很实际的安全评估问题:在不能生成样本、甚至法律上不允许尝试生成样本的场景下,如何判断一个上传的 LoRA 是否把生成模型专门化到了 NSFW 或 CSAM 等有害内容方向。

这篇工作问的是:什么样的 instruction-tuning 数据才是真正“有用”的,尤其是在数据预算受限时,怎样从大量指令样本里挑出最能提升 instruction following 的子集。作者不再只看样本本身的难度、困惑度或 reward 分数,而是从 in-context learning 角度定义样本价值:一个候选样本如果作为 demonstration,能稳定降低一批语义相关、且有一定挑战性的 probe 样本的 instruction-following difficulty,那么它更可能是高质量的 instruction-tuning 数据。

在离线偏好优化(DPO/IPO/KTO/SimPO)里,性能对超参(尤其是 margin/温度类超参)很敏感,导致需要反复调参。论文试图用一种“实例级自适应”的方式,减少或替代人工调参,同时保持训练开销接近原方法。

标准预训练和后训练(SFT/RL)目标优化的是单个样本的似然,这与测试时依赖聚合或过滤输出(如 Pass@N、多数投票、Best-of-N)的推理策略不一致,导致模型在测试时扩展计算(test-time scaling)时表现次优。

很多 LLM 的推理能力并非不存在,而是用户原始问题与模型更易激活的结构化推理输入之间存在分布错配;这篇工作试图在推理时自动改写问题来激活能力。

定制化政策/合规 guardrails 需要高质量标注数据,但人工标注昂贵;如何仅用任务描述+少量无标注样本生成可信的合成训练集。

讨论 Perspective API 将在 2026 年关闭后,NLP、CSS 和 LLM 毒性评测长期依赖单一闭源测量工具所暴露的可复现性和概念有效性问题。

解决跨领域、跨长度文档摘要中,自动评测指标与人类判断不一致,以及如何用评测信号反哺摘要生成的问题。

解决 LLM 安全防护过度依赖英语、导致跨语言 jailbreak 容易绕过的问题,尤其是在黑盒部署场景下如何做无需训练的外部防护。

澄清 RLHF 标注员判断在对齐流程中的规范性角色:他们是在扩展设计者偏好、提供事实证据,还是拥有独立决定权。

现有白盒LLM越狱攻击依赖添加离散对抗后缀,易被检测,此前认为直接优化原始prompt embedding会破坏语义

现有LLM个性化方法依赖稠密用户交互历史,冷启动场景下效果差,外部异构用户信号噪声大难以有效利用
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

这项工作研究一个对 post-train 和 pretrain 接口都很关键的问题:为什么同样从基座模型出发、使用相同训练数据,RL 往往能带来跨任务泛化,而 SFT 更容易引入任务特化和能力遗忘。作者不只比较外部指标,而是把 base、SFT、RL 模型的内部激活对齐到同一个稀疏特征空间,观察训练范式如何改写表示。

论文处理的是一个很具体但关键的问题:CoT 让 Transformer 在表达能力上可以模拟图灵机,但这种能力是否能从有限长度的训练轨迹中学到,并外推到更长推理长度,并不成立。作者把问题从“存在一个 Transformer 可以表达某种计算”收紧到“标准 Transformer 在有限训练分布上能否学到可长度泛化的 CoT 计算”。在标准位置编码和有限 alphabet 条件下,结论偏负面:即使给 CoT,长度可泛化的可学习任务仍然落在 TC0 附近,不能自动获得图灵完备推理能力。

研究“subliminal learning(潜意识学习)”里一个更强、更可控的信号注入方式:当学生模型只在看似无关的教师生成数据上做微调时,究竟能转移多复杂的偏置信号、转移的机制是什么、以及这种信号能被数据以多高精度编码与恢复。

这篇论文问的是:Transformer 不只是理论上能用 CoT 模拟通用计算,是否真的能通过 next-token training 学会一个通用语言解释器。作者用一个简化但计算完备的语言 MicroPy,把问题转成学习小步执行轨迹。

这篇论文研究的是一个很具体但常被混淆的问题:Transformer 内部是否保留了“输出置信度之外”的错误信号,使得外部监控器可以从中间层激活读出 token 级决策质量。作者把这个性质定义为 observability,并指出很多以往 probe 结果其实主要在读 softmax confidence 的影子,而不是独立的内部可监控信号。论文真正要回答的是:这种可观测性是不是 Transformer 的普遍属性,还是由架构配置和训练过程决定的。

在机制可解释性研究中,常用的基于优化器更新轨迹的低秩诊断方法(如对 AdamW 更新进行 SVD)能否真实反映特征形成的参数空间方向?

现有softmax注意力Transformer的通用逼近理论仅针对宽泛函数类给出宽松资源边界,缺乏针对特定目标函数的紧凑资源开销量化结果,缺少具体目标导向的构造性逼近理论。

现有Transformer上下文学习(ICL)的理论研究多聚焦线性分类的实现条件,缺乏高斯混合二分类任务下ICL性能随输入维度、上下文示例数、预训练任务数的经验缩放规律刻画,且线性注意力下的结论是否适用于全结构Transformer尚不明确。

标准随机采样常只带来词面变化,难以在测试时扩展中产生语义上真正不同的候选解。

传统 voxelwise fMRI encoding model 容易受测量噪声、被试差异和空间相关冗余影响,难以干净地分析故事理解时语言表征与脑活动的对应关系。

长文档摘要的自动评测与可操作反馈长期不可靠:指标与人评相关性弱,且不给出可用于改写的缺陷定位。

检验小型指令模型在被提示“故意考差”时,是否会出现低于随机水平的表现,从而可作为 sandbagging 的可检测信号。

检验 LLM 是否真正从文本中学到具身认知与文化差异,具体用指示词 this/that、这/那 的跨语言理解作为探针。

研究不同前沿 LLM 输出的 token rank-frequency 分布是否存在可复用的统计规律,并据此构造极低延迟的实时验证原语。

解决闭源 LLM 参数规模不可见的问题,尝试用“事实知识容量”而非推理成本来反推模型参数量。

评估 LLM 是否能可靠完成网络系统架构设计中的约束推理、配置选择和多目标权衡。

系统介绍如何从形式化和算法角度验证神经网络,包括前馈网络、循环网络、注意力机制和 Transformer。

研究在多步训练中,学生模型是否会通过只蒸馏非类别 logits 仍然继承教师模型的隐藏 trait,以及这种现象是否由持续的梯度对齐驱动。

表格基础模型(TFM)的 in-context 机制对“近似干净输入”有隐含先验,真实脏数据(缺失/异常/重复)导致先验失配,从而同时损害准确率与校准;如何用可学习的方式把清洗过程对齐到模型先验。

现有Hopfield联想记忆在高记忆负载和干扰场景下检索精度低,且缺乏自注意力计算的生物动力学解释
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

现有代码理解评测过于偏向局部片段,无法衡量真实软件开发中跨文件、跨实体、多跳代码理解能力。

现有AI能力基准无法提供递归自我改进的早期预警信号,缺乏衡量AI自主复现经典AI研究突破能力的评估方案。

提升 LLM 在 instructed code editing 中的可靠性,尤其是在需要通过可执行测试且避免无关代码改动的场景。

评估 LLM 从自然语言需求生成 REST API 测试用例时,现有代码覆盖率和崩溃指标无法衡量测试是否验证了预期功能。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

论文试图把 recursive language model 的“在 latent space 中反复计算”扩展到 multi-agent system,让多个异构 agent 通过连续隐状态递归协作,而不是依赖多轮文本交互。

这篇工作讨论的是 GUI agent 在高动态界面中的部分可观测问题:如果 agent 每一步只看动作后的单张截图,那么很多关键状态变化会发生在两次截图之间并直接消失,导致决策依据缺失。

这篇工作解决的是终端 agent 训练数据里一个比“任务数量不够”更具体的问题:已有自动合成方法虽然能扩任务数,但很难控制 agent 真正在轨迹中经历到的“场景多样性”和“技能组合多样性”。论文把终端执行过程抽象成“在一串中间场景上依次施用技能”,然后围绕这个抽象去做任务合成。目标不是再造更多表面不同的 task,而是系统地产生覆盖更广技能迁移路径、更少冗余、更适合采样训练轨迹的可执行任务实例。

多语言 Agent benchmark 如果只是机器翻译英文题目,容易引入 query-answer 错配、文化语境偏移和难度失衡,导致评测结果不再测模型能力。

解决复杂执行型 LLM agent benchmark 中,任务失败究竟来自模型能力不足还是 benchmark 规范、脚本与评测基础设施本身缺陷的问题。

评估语言模型 Agent 在混合动机多智能体环境中的协作与竞争能力,尤其是短期结盟和长期对抗同时存在时的谈判行为。

解决 agent workflow 设计过度依赖逐任务搜索、无法复用跨任务结构知识的问题。

评测 LLM 从不同来源内容中生成结构化输出时,是否同时满足 schema 合规和字段值正确。

解决多语言 RAG 在文化语境查询上常因检索空间固定而取错证据、导致回答缺乏文化贴合度的问题。

解决现有web agent基准仅覆盖短单站点任务,无法评估真实长程多站点web导航任务的问题

试图给人类与 Agent 协作的“杠杆率”建立一个逐任务度量:Agent 替代的人类工作量,除以人类用于说明任务、处理中断和验收结果的时间。

现有智能体验证框架仅适用于封闭世界场景,无法解释大模型在开放机构场景下部署困难的核心问题

如何利用 LLM 自动化探索和优化复杂的计算机体系结构设计空间(如缓存替换策略、分支预测器)?

用 LLM agent、程序合成和实验设计构成闭环,自动比较认知科学中的竞争理论。

解决生产级多 Agent 系统在复杂工业环境中难以模块化组合、运行时观测和持续演化的问题。
面向终端的多会话编码Agent框架(jcode)。
对比多款CLI,给出RAM/启动耗时数据;适合多会话工作流与低资源环境。
⚙ Rust实现TUI/PTY交互;会话可扩展,支持可选本地embedding以控内存。
开源终端式代理开发环境,内置编码代理,也可接入Claude Code等CLI代理。
适合在终端中做AI辅助开发;客户端开源,支持社区协作与代理化提交流程。
⚙ Rust实现客户端;UI框架MIT,其余代码AGPLv3;提供bootstrap/run/presubmit脚本。
把 DeepSeek Web 对话转为多家兼容 API
适合用现有 SDK 接入 DeepSeek,多账号轮询
⚙ Go 后端用 PromptCompat、账号池和流式适配
面向编码代理的技能化开发方法论。
用规格、计划、TDD和评审降低代理跑偏。
⚙ 自动触发设计、worktree、计划、子代理、TDD、评审。