AI Research Daily
更新时间: 2026/4/21 21:27:32
方法或结果明显独立成立的工作,建议读全文
这不是论文,也不是预训练方法研究。内容讨论的是 Gemini app 如何调用用户 Google Photos 和个人偏好做个性化图像生成,核心是产品侧的个性化检索、上下文接入和隐私声明,而不是基座模型训练、统一建模目标或 post-training 方法。
在不增加参数量的前提下,把“推理所需的额外计算”从后训练阶段的显式 CoT 文本生成,前移到预训练阶段的隐空间迭代计算里;同时解决循环/早退式动态深度在训练中容易塌缩(总是浅层退出或总是跑满循环)的问题,并验证这种“第三条 scaling 轴(loop depth)”在多万亿 token 规模下是否仍然带来稳定收益。
这篇论文解决的是 looped language model 的两个核心障碍:一是训练不稳定,表现为 residual state 爆炸和 loss spikes;二是即便 looped 架构在参数效率上有吸引力,也缺少像参数规模、数据规模那样可预测的 scaling law,因此很难把“循环深度”当成一个可靠的计算扩展轴。作者的目标不是单纯把已有 recurrent-depth 模型训稳,而是把 looping 从一个脆弱技巧,变成可分析、可训练、可做训练与测试时计算扩展的体系。
如何把“专家手写数据清洗规则”扩展到海量语料的逐样本精细处理,同时避免规则僵化、覆盖不足与人工成本不可承受。
这篇试图把前两篇的经验观察收束成一个更清楚的机制命题:为什么 RYS 只在中层有效,以及这种“可重复的中层”是否对应一个语言无关、甚至跨代码与 LaTeX 的共享语义空间。它关心的不是单次 hack,而是 Transformer 内部表示与可编辑性的关系。
文章讨论一个很具体但不寻常的问题:Transformer 的不同层是否承担了相对稳定的功能分工,以及能否利用这种分工,在不训练、不改权重的前提下直接改造模型能力。作者从 Base64 输入也能完成推理这一现象出发,提出早层负责“读入/翻译”、中层负责抽象推理、晚层负责“写出/重编码”的三段式假设,并据此做层复制实验。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

这不是论文,也不是预训练方法研究。内容讨论的是 Gemini app 如何调用用户 Google Photos 和个人偏好做个性化图像生成,核心是产品侧的个性化检索、上下文接入和隐私声明,而不是基座模型训练、统一建模目标或 post-training 方法。

文章介绍 Kimi K2.6 在开源 coding 模型上的更新,重点放在长时程工程任务、工具调用稳定性,以及面向 agentic coding 的能力组织方式。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

在不增加参数量的前提下,把“推理所需的额外计算”从后训练阶段的显式 CoT 文本生成,前移到预训练阶段的隐空间迭代计算里;同时解决循环/早退式动态深度在训练中容易塌缩(总是浅层退出或总是跑满循环)的问题,并验证这种“第三条 scaling 轴(loop depth)”在多万亿 token 规模下是否仍然带来稳定收益。

这篇论文解决的是 looped language model 的两个核心障碍:一是训练不稳定,表现为 residual state 爆炸和 loss spikes;二是即便 looped 架构在参数效率上有吸引力,也缺少像参数规模、数据规模那样可预测的 scaling law,因此很难把“循环深度”当成一个可靠的计算扩展轴。作者的目标不是单纯把已有 recurrent-depth 模型训稳,而是把 looping 从一个脆弱技巧,变成可分析、可训练、可做训练与测试时计算扩展的体系。

如何把“专家手写数据清洗规则”扩展到海量语料的逐样本精细处理,同时避免规则僵化、覆盖不足与人工成本不可承受。
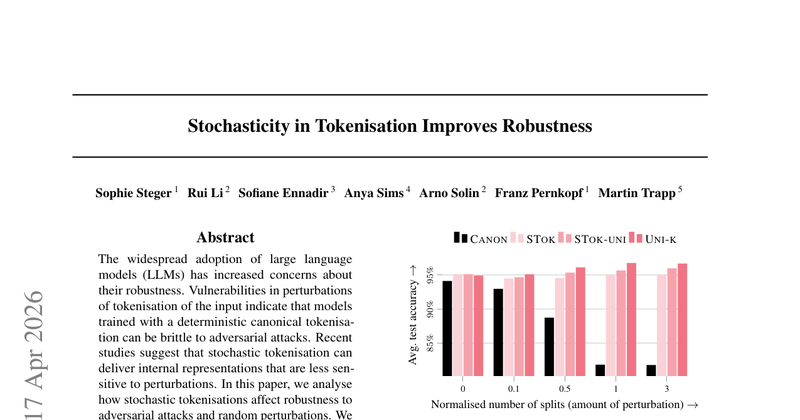
LLM 在训练时只见过“规范(canonical)分词”,导致对等价字符串的“非规范分词”(同一字符串、不同 token 序列)高度脆弱;核心问题是:在不改词表的前提下,引入训练期分词随机性,能否系统性提升对随机扰动与最坏情况(对抗)分词攻击的鲁棒性,并解释这种鲁棒性来自哪里。

试图缓解单一参数空间中跨领域知识相互干扰的问题,用显式结构约束替代自由 token 生成。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

解决并行推理中大量错误分支在早期就已注定失败、却仍持续消耗算力的问题。
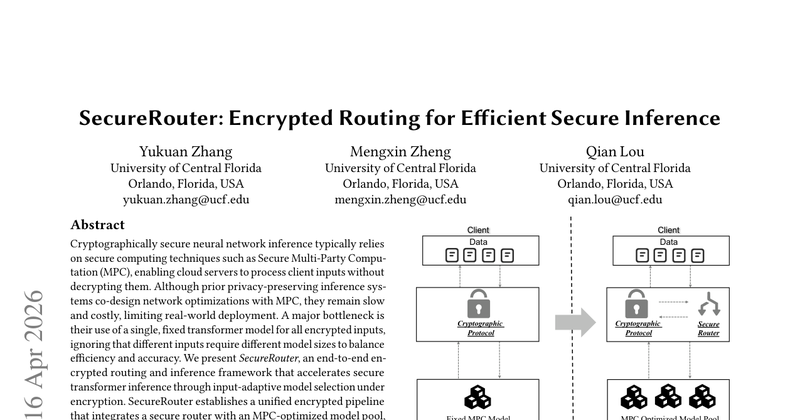
解决基于安全多方计算(MPC)的隐私保护Transformer推理中,使用单一固定模型导致效率低下的问题。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

评估视频 MLLM 是否具备基于规则、时序和实体感知的体育裁判能力,而不只是泛化视频理解能力。

解决低资源场景下长序列文档级音频-文本跨模态对齐时,模态维度不平衡导致的模态特有结构丢失问题
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

在文生图模型里,很多不安全语义不是来自单一显式概念(裸露、血腥等),而是来自“两个各自无害的概念组合后触发的隐含语境”。论文要解决的是:如何把这种 Multi-Concept Compositional Unsafety (MCCU) 形式化、系统构造评测集,并用可量化指标评估模型与防御方法在“安全性—可用性”之间的权衡。

从无声视频生成语音时,如何利用语音 codec token 的层级结构,把说话人语义与细粒度韵律更好地对齐到视觉信号。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

解决现有 verifier 在复杂推理任务中容易被错误中间步骤误导、且缺乏外部 grounding 导致奖励信号不可靠的问题。

这篇工作要回答的是:LLM 的 RL post-training 到底是在学习新的任务行为,还是只是在把基座模型原本就有的高概率输出进一步“压尖”。作者没有停留在概念争论,而是把两种机制放进同一个 KL-regularized RL 框架里做可控比较:一类目标只做 distribution sharpening,另一类目标直接优化 task reward,再加上两者混合。核心问题不是“RL 有没有用”,而是“task reward 这个训练信号是否提供了超出分布重加权的增益,以及这种增益在什么条件下出现”。

这篇工作解决的是 group-wise preference optimization 的一个实际瓶颈:偏好数据常常对同一 prompt 采样出多个回答,但现有 DPO 类方法大多只取一正一负,浪费了组内监督;而一旦真的用 group/listwise 目标,loss 会把同组样本的梯度耦合在一起,训练时必须同时保留整组 activation,显存随组大小快速上升,导致方法难以扩展、也难做系统比较。

评估 LLM 在小分子药物设计任务上的真实能力边界,并检验基于环境反馈的 RL 后训练能否显著提升化学任务表现。

如何攻击并绕过大型推理模型(LRMs)在生成中间推理步骤时的安全对齐机制?
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

这篇试图把前两篇的经验观察收束成一个更清楚的机制命题:为什么 RYS 只在中层有效,以及这种“可重复的中层”是否对应一个语言无关、甚至跨代码与 LaTeX 的共享语义空间。它关心的不是单次 hack,而是 Transformer 内部表示与可编辑性的关系。

文章讨论一个很具体但不寻常的问题:Transformer 的不同层是否承担了相对稳定的功能分工,以及能否利用这种分工,在不训练、不改权重的前提下直接改造模型能力。作者从 Base64 输入也能完成推理这一现象出发,提出早层负责“读入/翻译”、中层负责抽象推理、晚层负责“写出/重编码”的三段式假设,并据此做层复制实验。

这篇延续前文,核心问题变成两件事:RYS 这种中层 relayering 到底是不是 Qwen2-72B 的偶然现象;以及如果它可泛化,Transformer 中层是否真的存在跨语言、跨表面形式的共享语义空间。作者把问题从单模型技巧推进到“结构是否普适”。


定位 post-training 过程中输出多样性塌缩究竟发生在哪个阶段,并区分训练方法、训练数据组成和推理格式各自的作用。

这篇工作研究的是:预训练 Transformer 的层到底是不是严格按顺序、逐层依赖地完成计算,还是说中间层在很大程度上共享表示空间,因此可以被跳过、重排,甚至并行而不立刻失效。更具体地说,作者想回答两个机制问题:第一,中间层是否形成了相对统一的表示坐标系;第二,模型性能对层顺序和层数的敏感性在不同深度区间、不同任务上是否不同。这个问题和常见的剪枝或蒸馏不同,重点不是压缩,而是借由对 frozen 模型做结构扰动,反推预训练后层功能的组织方式。

如何用 LLM 的内部表征信号更稳健地估计不确定性,从而检测幻觉/事实性错误。

评测并刻画通用 LLM 在中文互联网亚文化“抽象语言”上的能力边界与失败模式。

梳理如何把可解释性直接写进大语言模型的结构与计算过程,而不是依赖训练后的外部解释工具。

评估以差分隐私保护输入为条件的 LLM 模拟器,能否生成既保隐私又保分布真实性的合成数据。

研究 flow matching 生成模型对数据删减、架构变化和训练配置变化为何表现出异常稳定性,以及这种稳定性是否会保留潜在表示与样本质量。

人类在与LLM交互时,哪些维度会影响他们对模型的拟人化倾向和信任度?

这篇工作试图用谱分析解释 Transformer 在推理、事实回忆和指令跟随时的隐藏状态几何差异,并问这些差异能否作为 reasoning 的可测信号。

探索 looped transformer 是否更适合在 in-context learning 场景中模拟迭代式学习算法,尤其是数据拟合类任务中的算法结构。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

这篇工作要回答的不是“模型能不能完成一次编辑任务”,而是“当用户把一段较长、较专业、需要多轮修改的文档工作委托给 LLM 时,模型能否在长链条操作里保持文档完整性,不持续引入细小但累积的破坏”。作者把问题定义为 delegated work 下的 document fidelity:模型既要执行编辑指令,又不能在未被要求的地方删改、漂移、格式损坏或语义失真。难点在于,这类任务很难做大规模自动评测,因为多数专业文档没有标准参考答案,且真正风险来自多轮交互后的误差累积,而不是单轮成功率。

评测多模态基础模型在真实 3D CAD 编辑任务中的能力缺口,尤其是视频+语音+指点+绘制等自然交互指令下的编辑表现。

如何利用 LLM 自动发现用于动态系统推理的简单、可解释的算法,而无需在大型数据集上训练神经网络?