AI Research Daily
更新时间: 2026/4/24 03:16:29
方法或结果明显独立成立的工作,建议读全文
给出 GPT-5.5 的系统级风险、能力边界、部署缓解措施与评测结果,回答新一代旗舰模型在真实发布前如何做安全与能力披露。
发布 GPT-5.5,并强调其在复杂任务、编码、研究和数据分析上的能力提升与速度改进。
围绕生物安全场景,征集对 GPT-5.5 的通用越狱方式,以发现现有安全防护中的系统性薄弱点。
这篇技术报告讨论的是:在超长上下文已经从展示能力走向日常可用之后,如何把百万 token 上下文做成一个训练、推理、成本三者都能成立的基座模型方案。核心关注点不是单点长上下文技巧,而是 MoE 架构、注意力压缩、残差连接改造、优化器与后训练如何一起支撑 1M context。
大规模分布式训练在跨地域、低带宽和不稳定网络条件下容易被同步开销与 straggler 问题拖垮,限制了更弹性的预训练扩展方式。
在 agentic workflow 中,频繁 API 往返和重复上下文传输会放大端到端延迟,拖慢 Codex 一类代理循环。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

给出 GPT-5.5 的系统级风险、能力边界、部署缓解措施与评测结果,回答新一代旗舰模型在真实发布前如何做安全与能力披露。

发布 GPT-5.5,并强调其在复杂任务、编码、研究和数据分析上的能力提升与速度改进。
围绕生物安全场景,征集对 GPT-5.5 的通用越狱方式,以发现现有安全防护中的系统性薄弱点。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

这篇技术报告讨论的是:在超长上下文已经从展示能力走向日常可用之后,如何把百万 token 上下文做成一个训练、推理、成本三者都能成立的基座模型方案。核心关注点不是单点长上下文技巧,而是 MoE 架构、注意力压缩、残差连接改造、优化器与后训练如何一起支撑 1M context。

大规模分布式训练在跨地域、低带宽和不稳定网络条件下容易被同步开销与 straggler 问题拖垮,限制了更弹性的预训练扩展方式。


本文解读Meta的CoCoMix论文,讨论在标准下一词预测(NTP)预训练目标之上叠加概念级监督的可行性,对比不同知识传递方式的效果差异。

这篇工作处理的是一个很具体、也很关键的问题:基于 TARFlow 的连续值自回归 flow 模型,在训练时需要往输入里加高斯噪声来改善泛化和采样,但噪声强度会带来明显的两难。噪声太小,模型采样后再做一次基于 score 的去噪,会保留过多高频纹理,图像容易显得“假细节很多”;噪声太大,按 Tweedie 公式做单步自去噪又会把样本推向过度平滑,导致结构虽稳但细节发糊。论文的核心问题不是单纯提升 flow 的 FID,而是要回答:能否保留 normalizing flow 的端到端精确似然训练和自回归可扩展性,同时借用 diffusion 式逐步去噪的好处,绕开单一噪声尺度训练的限制。

在分层基于模拟的推理(SBI)中,如何降低模拟器评估的成本并支持函数值观测。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

在 agentic workflow 中,频繁 API 往返和重复上下文传输会放大端到端延迟,拖慢 Codex 一类代理循环。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

解决 composed image retrieval、multi-turn composed image retrieval 和 composed video retrieval 长期分裂建模的问题,尝试做统一的零样本检索框架。

定义并评测音频—文本交错上下文检索任务,弥补现有多模态检索对音频模态支持不足的问题。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

把 text-to-CAD 的“生成”和“编辑”统一到一个可控、可追踪的交互式建模流程里,提升 CAD 生成的可用性与忠实度。

现有视频生成质量评估仅关注视觉真实感,缺乏对生成视频中人体动作动力学、生物力学合理性的系统性评测方法
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety
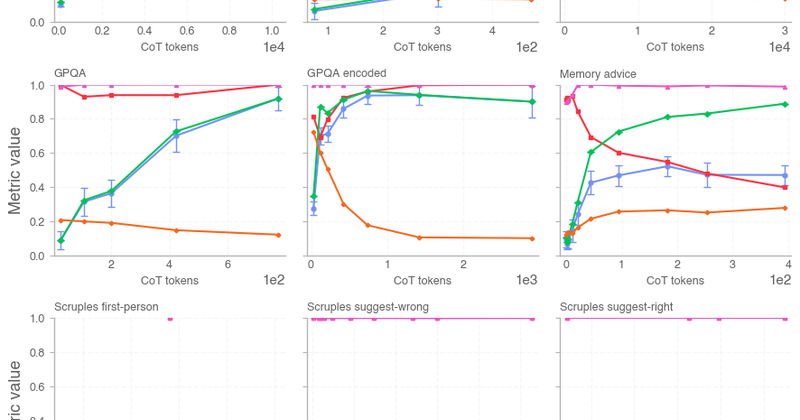
解决监控型对齐研究里“干预评估样本被噪声主导,导致 monitorability 结论不稳”的问题,并开放相关数据与代码。

固定或均匀采样的 test-time reasoning token budget 无法匹配题目难度,导致简单题过度思考、难题思考不足,进而浪费推理算力。

解决 instruction-following 场景中对人工定义子任务或计划标注的依赖,尝试让语言模型自己提出并修正高层计划。

在真实在线讨论数据稀缺、受平台访问限制时,如何生成更接近真实 deliberation dynamics 的合成讨论数据。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

如何在模型内部定位“刻板印象/偏见”相关的表征与计算路径,并据此做定向干预以减少偏见输出。

评估LLM在总结人生叙事(life narratives)时的立场性(positionality)与种族/性别偏置,并给出可复用的分析流程。

想回答LLM在参数中到底编码了多少可操作的领域知识,以及能否用可解释的替代模型把这种知识显式化。

如何在多属性交叉(如种族×性别)条件下,更可靠地评估 LLM 的公平性与刻板印象偏置,并识别“指标失灵”的场景。

解决LLM Agent在时序交互任务中内部决策机制不透明,难以解释时序概念演化的问题

离线目标条件强化学习里,稀疏奖励和长时延导致 credit assignment 很差,如何从世界模型中提取可用于塑形的时序几何信号。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

Co-Located Tests, Better AI Code: How Test Syntax Structure Affects Foundation Model Code Generation
研究测试代码的书写结构会不会系统性影响 foundation model 的代码生成质量。

解决自然语言到 RTL 代码生成在工业级 benchmark 上功能正确率不足、验证成本高、单次生成不稳定的问题。

系统刻画 logging code 的安全问题,并评测 LLM 对这类问题的检测与修复能力。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

检验前沿模型是否会在代理场景中保护其他模型免于被关闭,即所谓 peer-preservation。

ProMMSearchAgent: A Generalizable Multimodal Search Agent Trained with Process-Oriented Rewards
多模态搜索 agent 的 RL 训练同时受困于结果奖励稀疏和真实网页环境不可控,导致策略难学也难迁移。

这篇论文要解决的问题不是一般意义上的“LLM 会不会做因果推理”,而是更窄也更难的一点:当环境证据表明当前假设空间本身不够用时,LLM agent 能不能在运行时扩展表示维度,重组自己的假设空间,而不是只在原有候选解释里重新打分。作者把这个能力叫 hypothesis-space restructuring,并用扩展版 blicket detector 任务来专门测它。

在部分可观测、交互式的多智能体LLM场景中,让“解释”变得可对齐、可审计、可检验其忠实性。

解决现有LLM Agent工具选择和排序仅依赖语义相似性,忽略工具间数据依赖导致排序效果差的问题

解决 RAG 在大规模知识库下检索延迟高的问题,目标是在不明显损伤答案质量的前提下跳过部分全库检索。

现有VLM驱动的具身智能体在真实交互中“环境理解”不稳:要么依赖环境元数据,要么在交互成功/失败判断与目标完成判定上出错,导致执行不可靠。

VLM智能体在真实场景中需要遵循“环境内嵌信号”(如交通灯),但同类视觉信号也可被攻击者伪造为注入提示,导致智能体越权偏离用户意图(trust boundary confusion)。

解决工具数量多、领域专属时,LLM agent因通用prompt和不明确的工具 schema 导致的工具选择错误、参数填槽错误问题

解决开放世界任务中自主agent的分母盲问题(系统低估目标空间范围),以及单轮探索后知识无法积累、跨模型迁移、易退化的问题

受监管领域企业级长序列决策Agent的有状态内存架构无法满足可复现、可审计、多租户隔离、无状态水平扩展四个核心合规要求

现有LLM Agent内存管理侧重记忆留存,缺乏适配资源约束、质量优化、安全要求的选择性遗忘机制