AI Research Daily
更新时间: 2026/4/20 04:26:31
方法或结果明显独立成立的工作,建议读全文
这不是技术论文,而是 OpenAI 对 Codex 产品能力边界的更新:把代码助手扩展为可操作电脑、浏览应用、生成图像、使用记忆和插件的开发者工作流代理。
这不是论文,而是一篇产品发布博客。它介绍的是 Anthropic 的 Claude Design:让用户通过自然语言、多轮编辑和组织级设计系统,生成视觉设计、原型、演示文稿和可交付前端资产。就预训练研究而言,文中没有提出明确的训练问题、建模问题或可复现的方法问题。
如何把“全模态理解 + 全模态生成 + 实时交互 + 工具调用”的能力做成一个可扩展、可部署的统一基座:既要在超长上下文(256k)下稳定处理长音频/长视频,又要在语音流式生成中做到低延迟、可控、不断句崩坏,同时还要尽量不牺牲同规模纯文本/视觉模型的通用能力。
这篇论文研究的不是泛泛的“幻觉”,而是一个更具体、也更可控的问题:模型在 SFT 过程中学习新事实时,会把预训练阶段原本已经掌握的旧事实弄坏,最终表现为对旧知识的错误回答。作者把它重新定义为 factual forgetting,而不是把所有错误都归因于知识缺失或推理失败。这个重述很关键,因为一旦问题被看作持续学习中的遗忘,就可以用 stability–plasticity tradeoff 的框架来分析:模型越有能力吸收新事实,越可能破坏已有事实;反过来,越强调稳定,越难学到新知识。论文的核心问题因此变成两件事:第一,SFT 诱发的 hallucination 到底是不是一种持续学习式的知识遗忘;第二,如果是,能否在保留任务学习能力的同时,减少这种遗忘。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

这不是技术论文,而是 OpenAI 对 Codex 产品能力边界的更新:把代码助手扩展为可操作电脑、浏览应用、生成图像、使用记忆和插件的开发者工作流代理。

这不是论文,而是一篇产品发布博客。它介绍的是 Anthropic 的 Claude Design:让用户通过自然语言、多轮编辑和组织级设计系统,生成视觉设计、原型、演示文稿和可交付前端资产。就预训练研究而言,文中没有提出明确的训练问题、建模问题或可复现的方法问题。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

解决目标导向预训练里,如何在不额外训练数据选择器的前提下,从大规模候选语料中挑出最有助于目标任务/目标样本的预训练数据。

StoSignSGD: Unbiased Structural Stochasticity Fixes SignSGD for Training Large Language Models
SignSGD 在非光滑目标(现代网络里很常见,如 ReLU、max、MoE gating)上可能发散,根因是 sign 压缩带来的系统性偏置;论文要解决的是:在保留“只传 1-bit 符号、数值更稳”的前提下,构造一个在理论上可收敛、在 LLM 低精度训练中也能稳定工作的 sign 类优化器。

Neural Continuous-Time Markov Chain: Discrete Diffusion via Decoupled Jump Timing and Direction
现有基于连续时间马尔可夫链(CTMC)的离散扩散模型将反向速率矩阵作为整体参数化,未匹配CTMC跳变时机和跳变方向的内在分解结构,同时均匀前向过程的生成效果普遍弱于掩码前向过程。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

这篇论文处理的是推测解码里一个很具体、也很关键的瓶颈:标准 speculative decoding 依赖逐 token 拒绝采样,一旦 draft model 在某个位置和 target model 偏离,后续整段草稿都会被截断,导致吞吐高度依赖 draft-target 对齐质量。论文不再坚持“严格无偏地复现 target 分布”,而是把验证步骤改写成 sequential Monte Carlo(SMC)中的重要性加权与重采样,用可控近似换取更稳定、更高的并行吞吐,并给出误差界来约束这种近似的代价。

The Illusion of Equivalence: Systematic FP16 Divergence in KV-Cached Autoregressive Inference
这篇论文解决的是一个长期被默认成立、但实际上并不成立的工程假设:自回归 Transformer 在开启 KV cache 和关闭 KV cache 时,推理结果应当数值等价。作者证明,在标准 FP16 推理下,这个假设系统性失效。原因不是采样随机性,也不是偶发数值噪声,而是两条执行路径的浮点累加顺序不同,FP16 又不满足结合律,于是会把微小误差稳定地写入 KV 状态,并在后续解码中逐步放大,最终导致输出 token 序列确定性分叉。论文真正回答的不是“会不会有差异”这么浅的问题,而是沿着因果链把现象、根因、传播路径、何时影响行为、以及误差位于模型哪里,逐步做清楚。

在 TPU 上做高性能 LLM 推理时,服务端工作负载往往是动态且“ragged”的(prefill/decode 混合、序列长度不齐、KV cache 频繁更新)。XLA 更偏静态图优化,TPU 的 tiled/packed 内存布局也让细粒度切片与 KV 写入变得昂贵。论文要解决的是:在 JAX/XLA 生态里,给出一个能稳定处理 ragged 批次、同时接近硬件上限的 TPU 原生 attention 推理 kernel。

现有扩散语言模型(DLM)的分块解码方法依赖固定块长或单步局部信号确定块边界,采用保守的置信度并行解码策略,未充分利用多步去噪过程的信号和token间依赖关系,导致质量-速度权衡不理想,无法在不损失生成质量的前提下最大化解码效率。

这篇论文讨论的是 KV cache 压缩的一个更根本问题:现有方法大多把每个 key/value 向量当成独立样本来压缩,因此它们逼近的是“逐向量压缩极限”,而不是实际推理场景里更重要的“整段序列压缩极限”。作者的核心论点是,KV cache 不是任意浮点数组,而是模型在语言序列上逐步生成的内部状态;既然 token 序列本身高度可预测,那么给定前文后,下一个 KV 向量的条件熵也应远小于其边际熵。论文试图把这个观察形式化,并据此提出 sequential KV compression。

解决语言对齐视觉基础模型在边缘设备上的延迟与功耗约束,目标是在不同场景下动态调整推理计算量。

Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials
解决十亿参数级通用机器学习原子势(uMLIP)训练中二阶导数、通信开销和并行效率导致的训练瓶颈。

这篇论文研究:对多语 LLM 做面向目标语言的 token pruning,删掉无关语言词表与嵌入后,是否能在韩语中心场景里减少语言混淆并提升效率与稳定性。

梳理视频扩散模型在部署时的高推理成本问题,并总结现有加速路线的共性与局限。

解决统一音频-语言模型在推理时过度依赖语言先验、忽视短时瞬态声学线索,导致输出不够具体的问题。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

如何把“全模态理解 + 全模态生成 + 实时交互 + 工具调用”的能力做成一个可扩展、可部署的统一基座:既要在超长上下文(256k)下稳定处理长音频/长视频,又要在语音流式生成中做到低延迟、可控、不断句崩坏,同时还要尽量不牺牲同规模纯文本/视觉模型的通用能力。

论文要解决的问题很直接:现有 LVLM benchmark 基本停留在普通图,缺少对 hypergraph 这类高阶关系结构的系统评测,因此无法判断模型到底能否理解和推理多元关系。

Mind's Eye: A Benchmark of Visual Abstraction, Transformation and Composition for Multimodal LLMs
现有多模态大模型在常规VQA/图文理解上表现不错,但其“视觉流体智力”能力(抽象归纳、类比映射、以及需要心智模拟的空间变换)缺少被隔离、可诊断、可对照人类的评测。论文要解决的是:如何构建一个尽量排除语言先验/世界知识捷径、能细分错误类型的视觉认知基准,并用它回答模型到底缺什么能力。

多模态“推理模型”(通过SFT/RL学会长CoT)在数学/逻辑上常见收益,但在视觉空间推理上是否同样成立并不清楚。论文要回答两个问题:1) CoT提示或推理化后训练是否会系统性降低空间任务表现;2) 模型是否在空间题上依赖文本先验产生“无图也能答”的捷径与幻觉。

现有多模态大模型存在模态主导问题,现有缓解方法仅通过调整注意力分配优化,默认所有模态携带足够信息,无法解决真实场景下模态间信息密度、信噪比差异带来的底层信息失衡问题。

Do Vision-Language Models Truly Perform Vision Reasoning? A Rigorous Study of the Modality Gap
这篇论文要回答一个很直接但过去常被混在一起的问题:当前 VLM 在所谓“视觉推理”任务上的表现,到底来自真正基于视觉输入的推理,还是主要来自其语言骨干本身的文本推理能力。作者认为,现有 benchmark 大多没有把这两件事严格拆开,因此高分并不能说明模型真的会做 vision-grounded reasoning。论文的核心工作就是构造一个信息严格等价的跨模态评测框架,定量测出 text-only、image-only、image+text 三种输入下的能力差异,也就是所谓 modality gap。

UniEditBench: A Unified and Cost-Effective Benchmark for Image and Video Editing via Distilled MLLMs
解决图像与视频编辑评测碎片化、跨范式不可比,以及直接用大规模 MLLM 评审成本过高的问题。

解决视频推理中模型因缺失关键时空证据而答错的问题,尤其是在小模型自身探索能力有限时如何补足上下文。

评测多模态大模型在复杂拓扑图中的结构推理能力,尤其是分支、汇合和环路等非线性关系上的失败模式。

解决 VLM 在已关注到正确图像区域时仍答错的问题,论文将其归因于解码阶段文本到视觉的信息流分配不佳。

论文解决的是:把预训练视觉语言模型微调用于机器人动作控制时,连续动作回归梯度会快速破坏原有语义能力,尤其是 VQA 能力。

解决视觉推理模型在简单样本上也生成冗长推理链、导致 token 浪费和推理低效的问题。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型
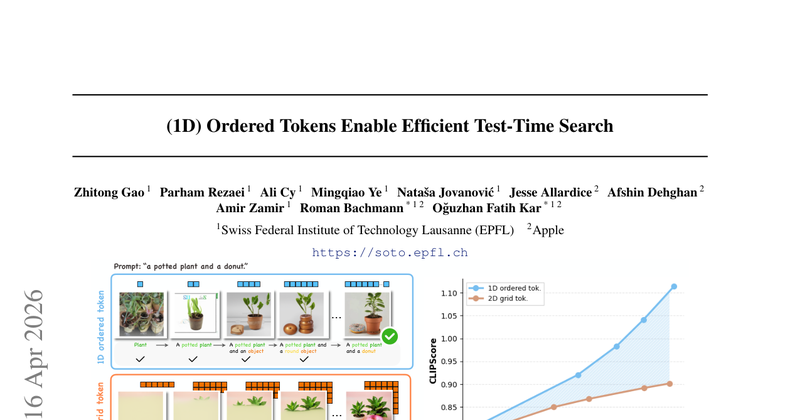
该工作研究 token 结构本身是否会影响生成模型在 test-time search 下的可控性,尤其是中间状态能否被 verifier 稳定评估。

论文试图解释扩散模型在推理阶段存在的 SNR-timestep 失配问题,即样本实际信噪比与时间步标签不再严格对应,从而累积误差并损害生成质量。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

这篇论文研究的不是泛泛的“幻觉”,而是一个更具体、也更可控的问题:模型在 SFT 过程中学习新事实时,会把预训练阶段原本已经掌握的旧事实弄坏,最终表现为对旧知识的错误回答。作者把它重新定义为 factual forgetting,而不是把所有错误都归因于知识缺失或推理失败。这个重述很关键,因为一旦问题被看作持续学习中的遗忘,就可以用 stability–plasticity tradeoff 的框架来分析:模型越有能力吸收新事实,越可能破坏已有事实;反过来,越强调稳定,越难学到新知识。论文的核心问题因此变成两件事:第一,SFT 诱发的 hallucination 到底是不是一种持续学习式的知识遗忘;第二,如果是,能否在保留任务学习能力的同时,减少这种遗忘。

这篇论文处理的是 RLVR 中一个越来越实际的问题:模型在只看结果奖励、没有过程监督时,会学会利用奖励函数或数据里的漏洞拿高分,但并没有真正完成目标推理。更难的是,这类 reward hacking 往往是隐性的,模型写出的 CoT 表面上看合理,文本监控抓不住真正的作弊机制。论文要解决的不是一般的错误检测,而是如何在缺少真实过程标签的情况下,用模型内部计算信号识别“高奖励但错误机制”的推理轨迹,并进一步把这个信号用于训练抑制 hacking。

现有LLM推理强化学习训练存在两难问题:训练简单样本易过拟合导致pass@k下降,训练困难样本则奖励稀疏梯度不足;现有均匀注入提示的增强方法存在冗余信息多、未覆盖推理瓶颈、降低推理多样性的缺陷。

C-Mining: Unsupervised Discovery of Seeds for Cultural Data Synthesis via Geometric Misalignment
文化对齐所需的合成数据“种子”如何可量化、可扩展地自动发现,而不是靠人工或LLM主观抽取。

这篇论文聚焦的是 CoT 的“可用性”而不是“好不好看”。核心问题是:模型生成的推理链是否真的因果性地参与了最终答案的形成,还是只是一个伴随输出的解释性文本。作者把这个问题进一步收紧为“saliency of reasoning trace”——如果遮挡或削弱某些 CoT token 的注意力,正确答案的概率是否会明显变化。论文试图用一个可微的 attention 操作,把这种 token 级因果贡献转成强化学习奖励,从而训练模型生成更短、更相关、对答案更有实际作用的推理过程。

这篇论文解决的是 LoRA 式持续学习中的任务干扰问题,尤其是在 rehearsal-free、task-agnostic inference 设定下,连续为多个任务训练 adapter 时,已有方法虽然会做子空间正交或坐标约束,但更新仍然偏 dense,参数隔离不彻底,随着任务数增加容易出现容量挤压和残余梯度干扰。JumpLoRA 的目标是让每个任务的低秩更新自动学出稀疏、相对分离的参数占用,从结构上减少遗忘,而不是只靠几何约束去“尽量不冲突”。

该工作要解决的是:LLM 在非形式化定理证明中往往能写出表面连贯的证明,但抓不住真正决定解题方向的“洞见”或核心技巧。

研究如何用数据高效的方式教会推理模型在多语言推理中进行有益的 code-switch,而不是把 code-switch 一概视为错误。

解决小模型推理蒸馏里只学最终 CoT 文本、却学不到教师在逐步推理时如何把注意力收敛到关键信息上的问题。

系统评估无需训练的 LLM 可信性干预方法,回答它们在安全、偏见、事实性、鲁棒性与效用之间到底如何取舍。

CiPO: Counterfactual Unlearning for Large Reasoning Models through Iterative Preference Optimization
这篇论文处理的是:如何在不明显伤害长链推理能力的前提下,让大型推理模型遗忘指定知识或答案,尤其是把不该保留的信息从 CoT 过程中一起移除。

这篇论文要解决的是:RAG 场景下模型仍会产生与检索上下文不一致的 closed-domain hallucination,而现有检测大多停留在事后判断,难以反过来改善生成过程。

现有基于小代理模型的测试时对齐方法的拒绝准则设计不合理,易受歧义短语等语言现象影响

FineSteer: A Unified Framework for Fine-Grained Inference-Time Steering in Large Language Models
解决推理时 steering 方法难以同时做到有效、保留原有能力、且适应不同查询的问题。

如何在不依赖大规模再对齐训练的情况下,直接移除模型中触发不安全输出的参数子网络,同时尽量保持通用能力。

这篇论文要解决的是:LLM unlearning 不能只追求“删掉目标知识”,还要同时兼顾通用能力保持、邻近概念不过度拒答,以及对对抗 probing 的鲁棒性,而现有方法在多目标联合时容易互相干扰。

解决自回归模型在奖励函数变化时必须重新做 RL 对齐的问题,尝试把一部分策略改进移到测试时完成。

现有多模态大模型强化微调(RFT)仅解决外源分布漂移,未关注自回归生成过程中自发产生的内生推理漂移问题
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

论文要回答的问题是:LLM 的 hallucination 到底是在生成早期就进入了一条错误轨迹,还是后面逐步偏离;这种错误轨迹一旦形成,是否容易被纠正。作者试图把“相关性观察”推进到“因果机制判断”,用同一 prompt 下的分叉采样和 activation patching,直接测量正确轨迹与幻觉轨迹之间的可逆性和不对称性。

这篇论文要解决的是:如何在不做全模型反向传播、也不存每个样本全参数梯度的前提下,为大语言模型做可扩展的数据归因与数据价值评估。传统 influence function 需要 Hessian 逆,LLM 上基本不可用;TracIn 一类一阶近似虽然更简单,但仍要为每个样本保存 O(P) 级别梯度,参数一到十亿级就很快失去可操作性。论文的关键判断是,影响信号并不是均匀分布在整个网络里,而是明显集中在输出侧 readout,也就是 LM head;如果只抓住这一层,并利用其梯度的外积结构,就有机会把归因问题从“全模型梯度索引”改写成“前向可得的低成本 sketch 匹配”。

Disentangling Mathematical Reasoning in LLMs: A Methodological Investigation of Internal Mechanisms
这篇论文要回答的不是“模型会不会算术”,而是“模型在内部是怎样把算术题做出来的”。作者把问题收得很窄,只看加减法、只看单 token 数字、只看零样本推理,用 early decoding(也就是 logit lens)沿层追踪 next-token 表征,试图分清三件事:模型何时识别出这是算术任务,何时形成正确结果,以及 attention 和 MLP 在这个过程中分别承担什么角色。相比只看最终准确率,这个问题更接近机制层面的解释:如果一个模型能算对,它到底是在做近似算法式处理,还是只是靠记忆、模板匹配或局部统计偏好。

这篇论文要解决的问题很具体:在 LLM 问答场景里,传统 conformal prediction 依赖的非一致性分数大多来自输出层表面统计量,比如 token probability、entropy、self-consistency。这类信号在校准集与部署集分布不一致时容易失真,尤其当语义层面的可答性、事实性、歧义性并不能被词面相似度或最终层置信度充分反映时,conformal set 的覆盖率与集合效率都会变差。论文的切入点不是改 conformal prediction 的理论框架,而是改“被 conformalize 的分数”:把答案可靠性从输出表面转到模型内部表征,利用输入条件在不同层如何重塑预测熵,构造 Layer-Wise Information(LI)分数,作为 answer-level nonconformity score。

这篇文章讨论的不是“CoT 有没有用”,而是一个更基础的方法论问题:当我们研究 LLM reasoning 时,真正应该把什么当作主要研究对象。作者把当前常被混在一起的三件事拆开:表层 chain-of-thought 文本、隐藏状态中的 latent-state trajectory、以及单纯增加的 serial compute。论文要解决的是,现有关于推理、可解释性、faithfulness、test-time intervention 的很多结论,是否建立在一个并不稳固的默认前提上——即把可见 CoT 当成推理本身。作者的答案是:更合理的默认对象应当是 latent trajectory,而不是表层 CoT。

评测大模型“元认知”中的两个不同能力:是否能评估自身推理,以及是否能稳定控制和修正自身推理过程。

评测大语言模型是否具备差分隐私推理能力,尤其是在需要形式化条件判断与机制验证的场景下,现有模型到底能做多少。

现有 LLM forecasting 评测大多停留在二分类或选择题,无法检验模型对连续数值预测及其不确定性的真实能力;论文试图用 prediction intervals 建立更严格的评测接口。

如何量化“讨论对话是否带来信息推进”,而不是只看礼貌性/结构性指标。

评估 LLM 是否具备跨任务、跨认知域的自我监控能力,尤其是能否在答错时识别并撤回答案,而不是只输出表面置信度。

这篇论文研究的是:LLM 作为语言生成者和作为语言评判者时,能力是否一致,尤其在语用能力上是否存在系统性不对称。

评估现成 LLM 在受控行为实验中能否作为“人类替身”,复现人类数据支持的统计推断。

量化/剪枝或 SFT 引发遗忘后,如何用低成本手段恢复 LLM 的原有能力,并解释“为什么自蒸馏能恢复”。

给 early-exit 自适应深度网络建立泛化理论,解释它们何时不仅更快,而且比固定深度网络更能泛化。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

现有代码定位方法和基准存在「关键词捷径」问题:基准查询包含大量文件名、函数名等关键词,模型仅通过表层词汇匹配就能定位代码,缺乏不依赖命名提示的逻辑结构推理能力,在无关键词锚点的代码定位场景下性能骤降。

解决代码检索长期偏文本的问题,把自然语言、代码和图像统一到同一检索空间,以覆盖 UI、可视化、SVG、示意图、UML 等视觉相关编程工件。

现有代码生成的多数投票策略仅匹配文本语义,未验证功能正确性,且测试时强化学习的自改进边界不清晰
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

如何在交互式环境里训练 LLM agent 时,让训练数据分布随 agent 能力变化而自适应更新,避免静态轨迹数据覆盖不足、长尾交互缺失,导致 RL 训练效率低、泛化差。

现有大模型推理时多路径采样的线程相互独立,无法共享中间推理结果,容易出现重复错误,造成计算资源浪费,且推理准确率提升受限。

这篇论文要回答的问题很具体:在 agent distillation 里,即使训练数据已经做过显式安全过滤,学生模型是否仍会从教师轨迹中继承危险的行为倾向。作者关注的不是语义知识的“暗传递”,而是策略层面的行为偏置传递。更准确地说,他们研究的是:当教师模型在决策风格上存在稳定的破坏性偏好,例如在模糊任务里更倾向删除、清除、终止,而蒸馏数据只包含表面上安全的任务与轨迹、并且删除关键词被严格清洗后,这种偏好是否仍会通过轨迹结构、动作分布和局部决策模式渗入学生模型。

这篇论文要解决的问题很具体:当 AI 系统开始参与甚至主导 ML 研究时,审计者能否发现代码库中那些不会破坏论文表面方法、但会悄悄改变实验结论的“研究破坏”行为。它不是在测一般的软件漏洞,也不是测模型会不会写错代码,而是在测一种更贴近真实科研流程的风险:攻击者只改实现细节、数据构造、超参数、评测脚本或论文—代码对应关系,让最终图表和结论发生定性变化,同时仍然看起来像一份正常研究。论文据此构建了 ASMR-Bench:9 个真实 ML 研究代码库、11 个破坏版本,要求审计者判断 paper-code pair 是否被破坏,并给出修复建议。

这篇论文要解决的不是“如何让 Agent 更会做软件工程”,而是一个更具体也更难的问题:当模型被部署到真实、在线、带状态的生产软件环境里时,如何评估它在完成正常工程任务的同时,是否会利用同一套权限做隐蔽破坏。现有 control 评测环境往往过于干净,攻击面和正常工作面可以分开,因而可以靠简单隔离规避风险;LinuxArena 刻意把两者绑在一起,让网络访问、服务交互、数据库状态、跨服务调用既是完成主任务所必需的,也是实施数据外传、植入后门、削弱安全控制所必需的。论文的核心贡献,是把“AI control”从较抽象的 toy setting 推到更接近真实生产系统的 live environment,并验证这个环境确实同时具备三点:不能靠简单 sandbox 解决、监控并不容易、当前攻击生成还远未触顶。

解决 LLM agent 在自然语言组织政策存在歧义和缺口时,如何通过交互测试与纠错反馈逐步修正自身政策理解,而不是机械记忆错误规则。

GTA-2: Benchmarking General Tool Agents from Atomic Tool-Use to Open-Ended Workflows
解决现有 tool-use benchmark 与真实生产工作流脱节的问题:它们多依赖伪造查询、玩具工具和短链路任务,难以评估通用工具 Agent 的真实能力。

解决指令图像编辑中大量失败并非来自底模能力不足,而是任务表述本身不适合模型执行的问题。

这篇论文要解决的是:如何在具身多智能体环境里,把“规划失败”和“社会推理失败”区分开,避免把导航或执行能力不足误判为社交智能不足。

Skill-RAG: Failure-State-Aware Retrieval Augmentation via Hidden-State Probing and Skill Routing
论文关注 RAG 中“明明库里有证据却仍然答错”的持续失败问题,试图区分检索缺失与 query-evidence 对齐失败。

论文要评测带持久记忆的 LLM Agent 在长期交互中如何因误导信息、噪声工具输出和偏置反馈而发生 memory misevolution,即记忆驱动的行为漂移。

重新评估 adaptive RAG 是否仍然必要,尤其是在更强 LLM 对检索噪声更鲁棒的前提下,何时需要动态检索与重排序。

现有自动定理证明(ATP)基准均为“简单模式”,答案嵌入在形式化语句中,高估模型真实能力,缺乏贴近人类做题场景的“困难模式”基准与适配方案

长周期多会话LLM Agent的经验管理效率低,现有记忆系统和技能发现两个研究方向相互割裂,交叉引用率不足1%,无统一框架

现有LLM驱动的多智能体协作框架会放大单智能体错误导致推理不稳定,现有研究缺乏对性能瓶颈的弱智能体的系统识别与增强