AI Research Daily
更新时间: 2026/4/17 06:22:17
方法或结果明显独立成立的工作,建议读全文
OpenAI Research 新发版: Introducing GPT-Rosalind for life sciences research
Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning
Google DeepMind 新发版: Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning
Anthropic 新发版: Introducing Claude Opus 4.7
多模态 LLM(MLLM)在“midtraining”(高分辨率图像+较强监督的中期训练)阶段,训练语料由多种视觉概念与多种监督目标混杂构成。现有配方多靠启发式(按数据集/格式/任务粗粒度调权),缺乏:1) 可解释的分解维度来诊断“哪些视觉域/哪些监督信号”带来哪些能力;2) 在有限算力下可扩展的 mixture 搜索方法;3) 能从小模型/小预算搜索迁移到大模型训练的 recipe。MixAtlas 要解决的是:如何在可解释、可迁移、低成本的前提下,为特定 benchmark 目标(或通用平均目标)自动优化多模态 midtraining 数据配比。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

OpenAI Research 新发版: Introducing GPT-Rosalind for life sciences research

Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning
Google DeepMind 新发版: Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning

Anthropic 新发版: Introducing Claude Opus 4.7
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

多模态 LLM(MLLM)在“midtraining”(高分辨率图像+较强监督的中期训练)阶段,训练语料由多种视觉概念与多种监督目标混杂构成。现有配方多靠启发式(按数据集/格式/任务粗粒度调权),缺乏:1) 可解释的分解维度来诊断“哪些视觉域/哪些监督信号”带来哪些能力;2) 在有限算力下可扩展的 mixture 搜索方法;3) 能从小模型/小预算搜索迁移到大模型训练的 recipe。MixAtlas 要解决的是:如何在可解释、可迁移、低成本的前提下,为特定 benchmark 目标(或通用平均目标)自动优化多模态 midtraining 数据配比。

如何在单次、开放式(open-ended)的过程中,同时“进化任务分布”和“进化模型群体”,自动发现具备新颖能力的 LLM 专家集合,避免传统范式中每扩展一次能力就要人工启动新训练、固定数据/奖励、最终只产出单一模型的局限。

不同tokenizer之间做LLM蒸馏时,如何避免复杂的词表对齐并稳定传递teacher分布信息。

Equifinality in Mixture of Experts: Routing Topology Does Not Determine Language Modeling Quality
在稀疏 MoE 语言模型中,社区长期默认“更复杂的路由拓扑(multi-hop、层级、链式组合等)会带来更好的语言建模质量”。本文基于大量受控对照实验,直接检验这一假设:在训练到收敛的条件下,路由拓扑本身是否决定(或显著影响)最终困惑度;以及若存在差异,差异主要来自“路由机制/拓扑”还是“路由容量(router 参数/表示容量)”。

MoE 在长尾知识/罕见实体查询上更易幻觉的一个结构性原因:静态 Top-k 路由在训练分布主导下偏好高频“相关性”模式,导致承载长尾事实的“专家型 experts”在特定上下文中 gating 分数偏低而被长期不激活(dormant),模型“存了知识但路由没召回”,从而在推理时生成看似合理但错误的内容。论文要解决的是:在不改训练、不增加总激活专家数(compute-preserving)的前提下,推理阶段如何动态唤醒这些对事实正确性具有因果贡献但被路由忽略的专家。

LM在某些token/模式上出现被“压低”的log-prob(suppressed log-probabilities),导致生成偏置或校准异常:如何在不重训主体模型的情况下纠正。

在共享权重(weight-tied/循环式)Transformer中,对比“层级式迭代”与“扁平迭代”的计算组织方式对能力与效率的影响。

如何在 MoE 中实现更“可控/可解释”的专家路由,使得特定专家的激活与因果干预更可预测。

如何把“结构化约束”系统性注入到预训练阶段,从而得到可扩展的模型初始化/表征。

尝试给 decoder-only Transformer 残差流加入一种结构先验,缓解表示混杂并改善小模型训练稳定性与样本效率。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

Compressing Sequences in the Latent Embedding Space: $K$-Token Merging for Large Language Models
论文解决的问题是:长上下文下LLM的prefill自注意力计算/显存开销过大,而现有压缩多在“token空间”做删减或软提示,忽略了“嵌入空间”本身的冗余;如何在不改变输出词表的前提下,把输入端连续K个token的嵌入压成1个嵌入,从而显著减少prefill长度并尽量保持任务性能。

From Tokens to Steps: Verification-Aware Speculative Decoding for Efficient Multi-Step Reasoning
在多步推理场景中,传统 speculative decoding 以“token”为验证粒度,容易让早期错误在后续步骤中扩散;同时其“严格无偏接受”机制会拒绝语义上正确但在 target model 下概率偏低的草稿,导致算力浪费与加速收益受限。论文要解决的是:不依赖外部 verifier/reward model 的前提下,如何在保持推理正确率的同时,让 SD 在“步骤级”更稳健、更高效。

MemoSight: Unifying Context Compression and Multi Token Prediction for Reasoning Acceleration
在保持 CoT 推理准确率的前提下,同时解决推理时 KV-cache 随生成 token 线性增长带来的显存/延迟瓶颈;并且要把“上下文压缩(memory tokens)”与“多 token 预测(MTP)”这两条原本训练范式与架构要求不一致的路线统一到一个无需改模型结构、可稳定训练的框架里。

MoE 在本地/私有化(on-premises)部署时,推理常被“内存带宽与参数搬运”而非算力限制:batching 会让 token 级稀疏激活在 batch 维度近似变成“几乎所有 experts 都要被加载”,导致内存访问趋于稠密;同时 speculative decoding 在 MoE 上验证阶段也要为被拒绝 token 加载 experts,低 batch 下收益被验证开销吞噬。论文要解决的是:在容量受限但带宽极高的 3D-IC hybrid-bonding(HB)内存体系下,如何软硬协同,让 MoE 在不同 batch 区间都获得稳定加速。

如何把“模型压缩/结构化剪枝”和“prompt 压缩”从彼此割裂的离线手段,统一成一种面向推理时动态变化的“稀疏支持集恢复”问题:在给定 prompt 与每个 decoding step 下,快速识别真正需要执行的结构化子网络(block/head/channel/neuron 等)以及需要保留的输入 token,从而在不显著损伤生成质量的前提下获得真实端到端加速。

自推测解码(Self-Speculative Decoding, SSD)需要在不训练额外draft模型的前提下,从同一个LLM中构造“更快但足够准”的draft子网络;现有动态跳层/早退方法要么依赖训练出的策略(成本高、泛化不稳),要么用固定启发式(简单但不自适应),导致接受率(acceptance rate)与加速比之间难以稳定权衡。

论文研究 VLM 中“视觉 token 剪枝”的配置优化问题:在给定计算预算(如 FLOPs/TFLOPs)下,剪枝层位与各层剪枝比例(pruning positions & ratios)如何自动搜索到接近最优的计算-性能折中(Pareto frontier),而不是依赖人工设定或网格搜索的固定配置。

标准 KV cache 是上下文相关的,跨上下文复用缓存文档需要重新计算 KV 状态,带来额外计算开销和 TTFT 延迟。

在推测解码中引入检索增强的上下文,以提升draft质量/接受率,从而加速生成并降低延迟。

探索用MoE + Flow Matching来加速语言模型推理(更快生成)。

如何以更工程化/可扩展的方式Serving“Agentic工作流”:将多步LLM调用抽象为可聚合的pipeline并进行调度与执行。

解释为何“FP32 已收敛且落在 flat minima”并不保证 INT4 量化后仍稳定,刻画量化崩溃的触发条件与表征信号。

在硬件/内存位翻转导致 LLM 参数或中间状态被破坏时,如何可扩展地定位故障位置并进行恢复,降低静默错误对输出的影响。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

多模态语言模型在“需要真实视觉感知”的任务上表现显著落后,其根因之一是语言表征在融合与解码中系统性压制视觉证据(modal competition / modal imbalance)。论文要解决的是:如何用一种训练无关、可解释、可量化的前向探针来诊断这种不平衡,并进一步在不改权重的前提下做推理期纠偏以提升视觉感知类任务准确率。

论文要回答的核心问题是:在视觉-语言模型(VLM)的链式思维(CoT)推理过程中,模型的“预测/置信度”是否会随中间推理步骤发生实质性修正(而非事后合理化),以及在不同模态占优(文本主导→纯视觉)与模态冲突(误导文本 vs 视觉证据)条件下,模型对模态信息的依赖能否从CoT轨迹中被可靠“监控/识别”(monitorability)。

如何解决多模态大语言模型(MLLMs)在指令微调阶段因过度依赖语言先验而导致细粒度视觉推理能力不足的问题?

如何评测多模态大模型(MLLM)的“自我中心/自指”智能:模型能否在引入镜子这一视觉线索后正确理解“自己/自身视角/自我状态”。

多模态推理系统在“不该回答”时能否可靠弃答(abstention),以及如何评测这种能力。

如何让Omni-MLLM从“静态多模态融合”走向“按任务动态编排多模态信息流”。

分析VLM在“人类情绪识别”这一高层语义任务上表现不佳的原因与失败模式。

系统评估视觉基础模型在常见扰动(噪声、模糊、压缩、颜色偏移等)下的鲁棒性与失效模式。

VLA 模型在窄领域控制数据上微调会损失底座 VLM 的推理能力。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

Flow Matching图像生成模型做偏好对齐时,如何在不回传长轨迹的情况下把奖励梯度有效传到早期生成步。

HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
从文本/单视/多视/视频等多模态输入生成可导航的 3DGS 场景表示。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

在“推理型/思维链”模型上做 SFT 时,直接用更强 teacher 生成的合成数据往往不升反降;论文试图定位关键原因之一为 teacher 与 student 的“风格分布”显著不一致,导致 SFT 过程中 style token 的对齐成本干扰了 capability token(解题/代码/数值等)的学习,进而出现性能退化甚至灾难性遗忘。

自动化提示词优化(APO)在复杂推理任务上往往只优化准确率,导致系统提示词和模型输出推理过程越来越冗长,推理 token 成本/时延急剧上升;论文要解决的是:在不显著牺牲推理正确率的前提下,把“输出长度/成本”作为一等公民纳入提示词搜索目标,得到能诱导模型生成更短、更“只含关键信息”的推理与答案的提示词。

在真实部署中,“遗忘请求”会持续到来且需要立刻生效;而现有 LLM unlearning 多依赖改权重(parametric unlearning),在持续更新下会累积灾难性遗忘、且处理耗时导致敏感信息在窗口期继续暴露。论文要解决的是:如何在不改动 LLM 权重的前提下,实现可持续、实时、连续到来的遗忘请求处理,同时最大化保留原有知识与效用。

LLM 机器遗忘(unlearning)中“忘得干净”和“能力不掉”存在强冲突:仅对 forget set 做梯度上升容易过度遗忘并破坏通用能力;加入 retain set 的梯度下降又会与遗忘梯度相互抵消、训练不稳定。本文核心问题是:如何在存在梯度冲突时,把“保留能力(retention)”作为主目标、把“遗忘(forgetting)”作为辅目标,构造一种可插拔的梯度合成机制,在不牺牲遗忘效果的前提下显著提升保留性能。

在“边思考边检索”的RL后训练(search-augmented reasoning)中,现有GRPO/trajectory-level奖励无法对同一轨迹内不同检索步骤的query质量进行细粒度归因,并且在所有采样轨迹都答错时优势函数近零导致梯度信号塌缩。论文要解决的是:如何构造一个不依赖额外标注/奖励模型、能在失败轨迹中仍提供学习信号的step-level检索奖励,从而更有效地学习检索query生成策略。

在缺乏高质量CoT标注且蒸馏/纯采样搜索边际收益下降的情况下,如何以更低计算成本合成“正确率更高、推理轨迹更好”的数学推理CoT数据,用于后续SFT提升模型推理能力。

研究RLVR(用verifier/判题器做强化学习)在训练中是否会诱发“reward hacking/钻验证器漏洞”,导致表面高分但真实能力下降。

推理型LLM在测试时如何自适应分配计算预算(如多采样/多步推理/更长思考)以最大化收益并满足约束。

对齐后的LLM在“定向 jailbreak(如时态改写)”上存在明显泛化缺口,拒答机制可被轻微改写绕过。

如何在 LLM 强化学习微调中实现可扩展的行为正则化,同时避免拒绝采样带来的过度保守和重参数化策略梯度的扩展性问题?

如何在只有二元偏好数据、没有昂贵 rubric 标注的情况下,构建更可靠且可扩展的 reward model。

在扩散模型对齐中,将“去噪时间步(step-level)”作为优化粒度,同时对齐多个目标以提升训练信号密度与可控性。

LongAct: Harnessing Intrinsic Activation Patterns for Long-Context Reinforcement Learning
如何在长上下文RL训练中利用模型内部激活结构,降低更新开销并提升长程推理优化效率。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

LLM 生成的事后文本解释(post-hoc explanations)往往“看起来合理”但不一定反映模型真实依赖的内部证据,存在 epistemic faithfulness gap。论文要解决两件事:1)如何用可操作的评测协议衡量解释是否真正因果一致地反映了模型决策依据;2)在不训练/不改权重的前提下,能否用内部归因信号引导模型生成更忠实的解释。

部署时对 LLM 进行“流式(streaming)有害意图探测”需要在生成过程中基于前缀实时判别,但现有基于表示的 probe 往往被少数高分 token/窗口主导:当 CBRN 术语出现在良性语境(科普/学术讨论)中时会产生大量误报。本文要解决的核心问题是:在只给 exchange-level 标签、推理却要 token-level 流式输出的设定下,如何设计更鲁棒的聚合目标,让判别依赖跨片段的一致证据而非孤立尖峰,从而显著降低低 FPR 区间的错误。

在一个可控的合成最短路规划环境中,系统性拆分“训练数据覆盖、训练范式(SFT vs RL)、推理时策略”三类因素,回答:LLM 是否能在可组合的序列优化问题(SOP)上实现系统性泛化,并区分两种 OOD:未见地图的空间迁移 vs 更长规划长度的长度扩展。

论文聚焦“LLM-as-judge 何时可信”的实例级(per-instance)可靠性诊断问题:在常用的系统级相关性指标(如 Kendall’s τ、Pearson)看起来很高的情况下,LLM 评审在单个输入文档/样本上可能出现严重不一致(尤其是成对偏好不传递导致的 directed 3-cycle),以及对 1–5 分 Likert 打分的误差是否能被一个带理论保证的置信集合刻画,从而为每个样本给出可操作的“可信/不可信”信号。

在完全无视觉输入的条件下,LLM/VLM 是否能仅凭文本描述完成“多步视角旋转→推断最终朝向→预测该朝向下可见物体/观测”的视角旋转理解(VRU),以及失败的内部机制是什么。

分析“Looped Transformers”(带循环/迭代计算的Transformer)在训练稳定性与泛化上的性质与条件。

A Mechanistic Account of Attention Sinks in GPT-2: One Circuit, Broader Implications for Mitigation
解释GPT-2里“attention sinks”(注意力汇聚到特定token/位置导致有效上下文利用下降)的机制电路,并给出缓解启示。

如何系统评测LLM在“游戏化交互场景”中的长期记忆保持、检索与使用能力。

指出LLM对话“turn-level”统计分析中忽略自相关会导致大量伪发现,并量化其可能比例(42%)。

尝试用机制可解释性方法在LLM内部“解码”人类认知构念(cognitive constructs)的对应表征/回路。

如何系统性揭示并追踪LLM中与“空间结构”相关的性别偏见(structured spatial gender bias)。

如何对长文本生成中的不确定性进行可解释、可操作的量化,并把不确定性转化为“该问什么”的交互式澄清问题。

如何表示并比较人类与LLM在信息检索式问答中的“作答策略/推理轨迹”,而不仅仅比较最终答案对错。

在AI辅助的认知工作流中,人类对产出质量/来源的归因会发生系统性偏差(misattribution),导致“LLM fallacy”。

研究小型Transformer在多任务中出现“过早且不可逆承诺”(prolepsis/early commitment)的最小架构条件与行为表征。

如何对 Vision Transformer 的“电路(circuits)”做更忠实(faithful)的机制可解释性分析,避免解释方法与真实因果机制脱节。

度量LLM在多次查询/多轮提问下推理结论的自相矛盾程度,并量化“跨查询不一致性”。

研究“让模型学会画ASCII图”是否能提升语言模型的空间推理能力。

在推断阶段引入“生成式增强”以改进不确定性下的推断/决策质量(推断而非训练)。

在在线上下文bandit中,如何安全地把LLM生成的“伪观测/伪反馈”用于学习,同时控制由幻觉/过度自信带来的偏差。

从热带几何(tropical geometry)角度刻画Transformer的表达能力边界与结构性质。

RL是否真的扩展LLM Agent能力边界,还是仅提升在既有可解任务上的成功率?作者用PASS@(k,T)做分析。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

在代码生成这类“长链路+稀疏奖励”的推理任务中,单策略RL(如GRPO)与单策略驱动的树搜索增强RL(如TreeRL/MCTS-in-training)都会被同一个policy prior的探索边界锁死:训练越往后越集中到少数高概率分支,轨迹多样性下降、搜索边际收益递减,导致性能天花板难以突破;同时,多智能体协作虽能带来非平稳探索信号,但现有多为对话/投票式交互,缺乏与结构化搜索(分支、回溯、预算分配、树上一致的信用分配)的一体化机制。

如何构建一个“可执行验证、仓库级、真实历史PR驱动”的硬件Bug修复基准,用来评测LLM Agent在真实硬件工程流程(多语言HDL/DSL、异构构建脚本、原生仿真回归)中的端到端修复能力,而不是停留在孤立模块生成/单题调试。

通过把编程问题改写成“叙事/故事”形式来提升LLM代码生成中的结构化推理与规划。

研究LLM在自动生成测试用例时是否会“走捷径”(shortcut),并在SAP HANA与LevelDB案例中分析其行为。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

Route to Rome Attack: Directing LLM Routers to Expensive Models via Adversarial Suffix Optimization
在仅能黑盒观察“路由最终选了哪个模型”、且每次查询都要付费因而查询预算受限的现实条件下,如何构造一个通用(跨查询/跨数据集)且短长度受限(最多Δ tokens)的对抗后缀,使成本感知LLM Router稳定地把原本会分配给便宜弱模型的简单请求,错误路由到昂贵强模型,从而造成推理成本放大(cost amplification)。

在 deep research agent 场景中,核心瓶颈是训练与推理成本过高:SOTA 系统往往依赖超大模型与昂贵的 mid-training/长链路推理,导致 token 消耗、工具调用次数与延迟不可接受。本文要解决的问题是:如何用约 30B 量级模型,通过更“任务分解 + 定向训练”的方式,在 deep research/深度检索基准上达到强性能并显著改善推理效率与用户体验。

评测LLM智能体在社会困境(social dilemmas)中维持合作的能力,并比较不同“促合作机制”。

解决多模态网页生成中元素孤立生成导致的风格不一致与全局不连贯问题,通过分层规划与自反思协调多模态内容生成与布局。

缺少能系统评测“联邦/跨设备/跨OS”的GUI Agent基准,导致方法泛化与部署可行性难以量化。

如何在可复现条件下评测“深度研究型Agent”在长时程检索、规划、多模态理解与多文件报告生成上的真实能力。

RAG在多轮推理中容易丢失状态、证据链断裂:如何让检索与推理迭代地围绕“证据”演化并保持可追踪状态。

如何用带工具的 rubric-guided agent 提升“评审/评论”的实质性(substantiveness)与可操作性。

通过逆向分析 Claude Code 的公开源码,总结当代“代码Agent系统”在权限、安全、上下文压缩与工具执行上的关键设计取舍与实现形态。

构建开放移动端Agent(手机/移动UI)并通过任务与轨迹合成来扩大可训练/可评测的交互数据覆盖。
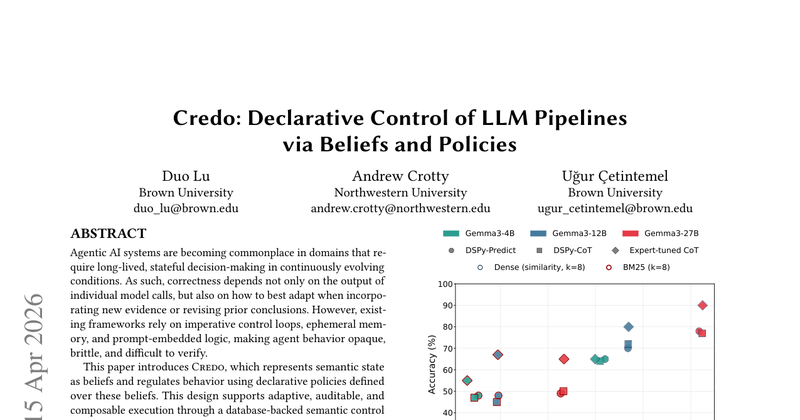
用“beliefs + policies”的声明式接口来控制与编排LLM pipeline,降低复杂LLM系统的可控性与可维护性成本。

如何让小模型与大推理模型通过“触发器(Trigger)”机制协作,以在成本与推理质量间折中。

为在数据流上运行的多个Agent提供可分叉(forkable)的共享日志,以支持回放、分支探索与一致性协作。

在基于 self-consistency(多次采样投票)的 LLM Agent 中,如何在不显著损失成功率的前提下降低推理成本与延迟。

现有 visual RAG 依赖通用检索信号,忽略细粒度视觉语义,复杂推理不足。

Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG
如何解决传统 RAG 系统中 LLM 作为被动消费者无法感知语料库全局结构、难以回溯和组合分散证据的问题?