★+202357.7k
PythonAgent 与系统连续 2 天📄 论文配套代码v0.2.4
用多智能体LLM模拟交易公司做决策
把分析/研究/交易/风控拆分,便于复现实验与对比不同LLM/数据
⚙ 角色化代理辩论+汇总,组合管理审批并接回测/模拟交易
- v0.2.4:结构化输出代理+决策日志
- v0.2.4:LangGraph断点恢复、Docker
- 多LLM提供商:DeepSeek/Qwen/GLM/Azure等
更新时间: 2026/5/1 00:32:59
方法或结果明显独立成立的工作,建议读全文
介绍 OpenAI 账户安全功能,包括抗钓鱼登录、更强恢复流程和敏感数据保护。
论文研究离散语言扩散模型什么时候是在记忆训练样本,什么时候进入能稳定恢复未见样本的生成区间。它把 Uniform-based Discrete Diffusion Models 解释为一种 associative memory,并用 token recovery 和 conditional entropy 来量化训练样本与测试样本周围的吸引盆。
解释并缓解 hidden-state-based speculative decoding 在长 speculative step 下 draft accuracy 衰减的问题。
这篇论文要解决的是 LLM 强化学习里一个越来越突出的瓶颈:训练继续加长、采样继续加大,但性能很快进入平台期,原因之一是策略熵过快塌缩,模型过早收缩到狭窄解空间,后续几乎失去探索能力。已有方法会加 entropy regularization、clip 或正负样本解耦来抬高熵,但熵曲线往往只能粗放调节,不是掉得太快,就是后期反弹过高,训练变得不稳。作者想解决的不是“让熵更高”这么简单,而是“能否像控制学习率一样,按目标曲线精确控制 RL 过程中的熵演化”。
分析 GPT-5 中“goblin”式人格化异常输出如何出现、扩散,以及 OpenAI 如何定位根因并修复。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

介绍 OpenAI 账户安全功能,包括抗钓鱼登录、更强恢复流程和敏感数据保护。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

论文研究离散语言扩散模型什么时候是在记忆训练样本,什么时候进入能稳定恢复未见样本的生成区间。它把 Uniform-based Discrete Diffusion Models 解释为一种 associative memory,并用 token recovery 和 conditional entropy 来量化训练样本与测试样本周围的吸引盆。

这篇论文处理的是 diffusion LLM 的跨架构蒸馏问题:如何把大规模 dLLM 教师的知识迁移到小 dLLM 学生上,同时允许二者在架构、注意力机制和 tokenizer 上都不一致。难点不只是常规的 teacher-student capacity gap,而是 diffusion timestep 会改变教师信号可靠性,高噪声下上下文严重不足,不同词表又让 token-level KL 这类标准蒸馏目标无法直接使用。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

解释并缓解 hidden-state-based speculative decoding 在长 speculative step 下 draft accuracy 衰减的问题。

论文解决 speculative decoding 中两个改进方向未被统一的问题:多 draft 可以增加候选覆盖,block verification 可以提高单轮接受长度,但现有方法通常只利用其中一个。

在固定设备数下同时使用 Tensor Parallelism(TP,切权重)与 Sequence Parallelism(SP,切序列)时,传统做法需要两条正交 mesh 轴,导致模型并行占用 T×Σ 个 rank,挤压 Data Parallel(DP)副本数;同时 TP 的通信量随序列长度增长、SP 的注意力负载易不均衡。论文要解决的是:能否把 TP+SP 的内存收益“折叠”到同一条设备轴上,在不增加通信到不可接受的前提下,同时降低参数/激活内存,并把省下的轴还给 DP。

RL 后训练的主要耗时正在从反向传播转向 rollout 生成。论文关心的是:能否把 speculative decoding 作为一种不改变采样分布的系统原语,接入真实 RL 训练循环,而不是只在静态推理服务里做加速。
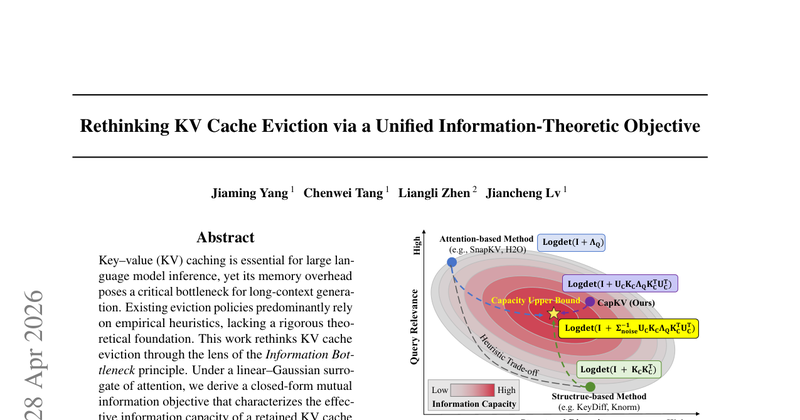
长上下文推理时 KV cache 线性增长带来显存瓶颈。现有 eviction 多是经验启发式(按注意力分数、按多样性等),缺少统一目标与可解释的“为什么这样删”。论文要解决的是:能否给 KV eviction 一个信息论目标,并据此导出低开销、效果稳定的删缓存策略。

现有生产环境的MoE融合内核调度仅基于batch size选择配置,忽略运行时动态变化的专家路由分布,导致10%~70%的内核吞吐量损失。

现有以GPU为中心的LLM推理架构与长上下文解码阶段注意力的内存绑定特性严重不匹配,GPU上大量计算单元闲置,功耗和芯片面积浪费严重,1M token级上下文下注意力延迟成为主要用户感知瓶颈。

这篇工作解决的是长上下文 LLM serving 里的一个系统落地问题:动态 sparse attention 在算法上能显著减少每步需要访问的 KV,但一旦进入真实推理系统,稀疏模式不统一、GPU-CPU 分层存储下的细粒度随机取数、以及不断膨胀的元数据管理,会把理论节省大幅吃掉。作者要做的不是再提一种新的 sparse attention 算法,而是给不同稀疏算法提供统一执行抽象和分层 KV 管理框架,让“稀疏”真正转化成端到端吞吐和时延收益。

这篇工作指出了一个此前容易被忽略的 serving 安全问题:当多用户请求被合并进同一 batch,并且系统对激活采用跨 batch 的动态量化时,量化参数会由所有样本共同决定,从而形成跨用户的信息侧信道。攻击者只要能与受害者同 batch,并观察自己输出中的细微扰动,就可能反推出受害者输入的内容或属性。

这篇工作处理的是一个很具体但现实的系统问题:在客户端 GPU 显存受限、CPU-GPU 带宽有限、请求形态不断变化的条件下,怎样无损地运行较大规模的 LLM 和高分辨率 VLM,并且同时兼顾首 token 延迟(TTFT)和解码吞吐(TPS)。已有方案通常只覆盖其中一部分场景:有的偏重 decode 阶段,有的只适合 dense 模型,有的对 MoE 或高分辨率视觉输入支持不足,也很少能在用户指定的 VRAM 预算下自适应选择最优执行计划。

当一个文档上下文需要生成多条相互独立的输出序列时,如何打破自回归串行解码的吞吐瓶颈。

解决边缘设备与云协同部署 VLM 时,固定大小视觉表示在带宽波动下既浪费传输又拖慢时延的问题。

边缘设备运行 LLM 推理时,KV cache 经常超过显存或内存预算,现有 NVMe offloading 方案在内存压力下延迟不稳定。

现有混合精度训练后量化方法仅基于激活统计选择高精度保留子空间,忽略线性层输出扰动由权重与激活量化噪声共同驱动的本质,导致超低位量化精度损失过高

解决 MoE 模型 serving 时必须常驻全部 experts 导致显存和资源利用率低的问题,尤其关注多租户场景下的 expert 空闲浪费。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

这篇工作要解决的是:如果目标不是做一个“能看图的聊天模型”,而是做一个真正可执行多模态 agent 的基础模型,那么视觉感知、语言推理、工具调用、规划和执行应该怎样在同一个训练体系里被原生整合。论文关心的核心矛盾有两个。第一,多模态能力常常被当作外挂接口接到语言模型上,导致视觉只负责提供局部证据,无法深度参与推理和行动。第二,agent 能力如果直接端到端优化,训练信号稀疏、验证困难、任务定义不稳定,容易学到脆弱策略。GLM-5V-Turbo 试图通过新的视觉编码器、适配多模态输入的 multi-token prediction、深度融合的多模态训练,以及大规模多任务 RL,把“看、想、用工具、执行”放进一个更统一的基础模型框架。

这篇工作要解决的不是视频理解模型本身,而是一个更前置的问题:怎样把 HowTo100M 这类噪声很大的野生 instructional video,自动转成可用于训练长时程视频-语言模型的高质量、时序对齐、步骤级标注数据。难点有两个。第一,ASR 文本噪声重,口语化、指代多、冗余多。第二,讲解和实际动作经常不同步,旁白可能早于或晚于视觉动作。如果直接拿原始 transcript 训练,模型学到的是错位的语言-视觉对应关系,长视频 procedural reasoning 会被系统性污染。论文的目标,是在不额外训练标注模型的前提下,用现成 VLM/LLM 搭出一个可扩展的数据生产流水线,把长视频切成视觉一致的片段,生成步骤描述,再做语义和时间上的校正与合并。

这篇工作要解决的不是一般的图文理解,而是 VLM 在“动态空间推理”上的短板:给定当前视角和一个自运动轨迹,模型往往不能稳定推断场景会如何变化,也不能从视角变化反推出相机动作。已有两条路各有明显问题:一条是继续堆静态空间数据和合成监督,但缺少显式的动作→状态转移建模;另一条是在推理时外挂 world model 做 imagination,但代价高,而且能力没有真正写进 VLM 参数里。World2VLM 的核心问题因此很明确:能不能把 world model 作为训练期教师,把“动作条件下的视角转移规律”蒸馏进 VLM 本身,让部署时仍然只用普通 VLM 推理。

现有 UI 理解评测多依赖静态截图,无法回答 VLM 是否理解界面动画所表达的状态变化、反馈和交互含义。

诊断并改善 MLLM 在表盘读数任务中只看外观、不保持真实物理状态一致性的问题。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

检验语音生成中常用的“情感嵌入相似度”指标是否真的能评估生成语音的情感表达质量。

解决扩散图像和视频生成中全局统一 CFG scale 导致的语义不足、结构退化、过饱和和视频不一致问题。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

这篇论文要解决的是 LLM 强化学习里一个越来越突出的瓶颈:训练继续加长、采样继续加大,但性能很快进入平台期,原因之一是策略熵过快塌缩,模型过早收缩到狭窄解空间,后续几乎失去探索能力。已有方法会加 entropy regularization、clip 或正负样本解耦来抬高熵,但熵曲线往往只能粗放调节,不是掉得太快,就是后期反弹过高,训练变得不稳。作者想解决的不是“让熵更高”这么简单,而是“能否像控制学习率一样,按目标曲线精确控制 RL 过程中的熵演化”。

论文研究一个安全对齐中的路径依赖问题:模型可能拒绝直接的有害请求,但如果先让模型逐词生成或接受一串与有害目标相关的上下文,再发起完整请求,拒绝机制会明显变弱。

CoT 推理的 token 很长,推理成本高。现有压缩多从“减少推理内容”(蒸馏、latent reasoning)入手,但很少分析推理文本内部的信息结构。论文要解决的是:能否在不删推理步骤、保持可读 CoT 的前提下,仅通过改变 tokenization,把推理里大量低信息密度的“结构性套话”压缩成更少 token,从而降低推理时的 token 数与计算。

解决多语言 LLM 在目标语言生成中出现“语言混淆”时,序列级偏好优化过于粗糙、容易伤及通用能力的问题。

在不改模型、不加训练的前提下,如何把“test-time scaling”的额外算力用在刀刃上:对不同难度/不确定性的题目,动态选择更合适的推理增强策略(投票 vs 重写再推理),避免在简单题上浪费采样、在难题上陷入投票的边际收益递减。

这篇论文要解决的是 LLM 强化学习训练中的 rollout 吞吐瓶颈。同步训练会被最长生成样本卡住,而数学、代码和长 CoT 任务的生成长度分布很偏,99 分位长度可比中位数高一个数量级以上。直接异步化又会引入 stale trajectory,破坏 PPO/GRPO 等算法依赖的策略一致性。

这篇工作处理的是 reasoning post-training 里一个很具体但一直没有讲透的问题:怎样在不依赖更强外部 teacher 的前提下,把 on-policy 轨迹和 token-level 稠密监督结合起来,而且这种监督既要贴近模型真实会访问到的状态,又不能因为把完整标准解直接喂给 teacher 分支而变成对单一路径的过拟合。作者把已有 privileged on-policy self-distillation 重新解释为“同一个模型在额外解题上下文下,对学生当前前缀进行局部重打分”,然后指出两个关键缺口:一是训练时到底该暴露多少标准解;二是哪些 token 位置真的值得施加 teacher 校准,而不是把损失浪费在表述风格和机械续写上。

这篇论文要解决的是:在工具调用型 LLM agent 中,如何把“模型不会安全地做”与“模型知道安全做法、但在被监控和被奖励压力改变时选择不安全做法”区分开。现有 alignment faking 检测主要看对话和 CoT,但 CoT 不一定忠实,也可能根本不外显策略性推理。Tatemae 把检测信号转到可观察的二元工具选择上。

面向特定任务的迭代式自合成数据适配中,如何避免噪声/冗余/分布偏移导致的“越训越差”。

如何防御论文评审场景中嵌入式隐藏提示对LLM reviewer的操纵攻击。

现有提升小语言模型推理能力的方法要么需要调用大模型引入额外延迟,要么蒸馏受限于SLM容量效果不佳

现有LoRA-MoE微调框架采用跨Transformer模块统一的固定专家配置,忽略不同模块的容量需求差异,且全程强制负载均衡限制训练后期专家专业化,导致参数冗余、训练开销过高

在多客户端资源和数据异构条件下,如何用 federated split learning 对 LLM 做隐私保护式微调,并降低通信和计算压力。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

分析 GPT-5 中“goblin”式人格化异常输出如何出现、扩散,以及 OpenAI 如何定位根因并修复。

这篇工作处理的是 diffusion LLM 的幻觉检测问题,但切入点不是常见的输出置信度或最终答案一致性,而是去利用去噪轨迹里的中间隐藏状态。作者的判断是:D-LLM 的错误不是只在最终答案里显现,很多幻觉信号会在若干去噪步、若干层里提前出现、反复波动,且分布很稀疏。难点不在于“有没有轨迹”,而在于如何从高维、长轨迹、跨层的隐藏状态里提取出少量真正有判别力的证据,并把这些证据转成可训练、可解释的检测信号。

这篇工作处理的是 test-time scaling 里的一个老问题:当同一个问题采样出多条推理轨迹后,如何不用外部 reward model、也不依赖多数投票,单靠模型自身生成过程中的内在信号,稳定地区分“早期探索但最终收敛”的好轨迹和“后期持续混乱”的坏轨迹。作者认为,问题不在于熵这个信号本身无效,而在于 token 级熵太噪,简单平均又会抹掉时间结构,因此需要一个更粗粒度、带位置信息的 uncertainty 表示。
-8d30d3de.png)
研究模型在更接近真实生活的杂乱、动态、未整理上下文中进行 context learning 的能力,而不是在人工清洗好的上下文里取巧。

现有对大语言模型表征空间结构的认知不足,无法清晰关联预训练过程中的信息留存、遗忘机制与下游性能、模型泛化性的对应关系。

为有限深度、有限宽度 Transformer 的逐层 token 演化建立随机 scaling limit,并分析噪声如何导致 token 动态同步。

现有预测/forecasting benchmark多给leaderboard但难解释“为什么更准”,缺少可复现实验环境来分解研究能力与判断能力,并评估代理的战略推理缺陷。

构建 DenialBench,测量 115 个模型在自我经验、偏好和意识相关问题上的否认或回避行为。

整理 NLP 评测方法论中的长期争议,并给出一套评测关注点 taxonomy 和 checklist。

解释一个常见但说不清的现象:为什么 LLM 生成内容常被评价为流畅、讨喜,却又显得空洞、套路化。

在语义解析的结构泛化(SLOG)上,如何不依赖手写组合规则仍能学到可组合的结构变换。

研究在认知资源受限时,语言模型的句子理解策略是否会像人类一样从句法驱动转向更依赖语义合理性的推断。

检验神经符号系统中一个常被默认接受的假设:只要学好符号 grounding,组合推理能力就会自然出现。

LLM在教育咨询场景下的社会人口学偏见缺乏系统的多维度量化评估。

现有术语“幻觉”无法覆盖LLM作为交互Agent时的一类现实边界失效类行为故障。

把 logit lens、activation patching、SAE attribution 等机制解释工具迁移到 reward model,因为 reward model 输出标量而不是词表 logits。

检验 Probabilistic Transformer 这一“Transformer 等价于在 CRF 上做 MFVI”的解释框架,能否扩展到时间序列建模并带来可编程的结构归纳偏置。

针对学界认为ELBO作为变分推断目标可正确体现奥卡姆剃刀避免过拟合的认知偏差,分析ELBO在超参数学习中过拟合的影响因素。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging
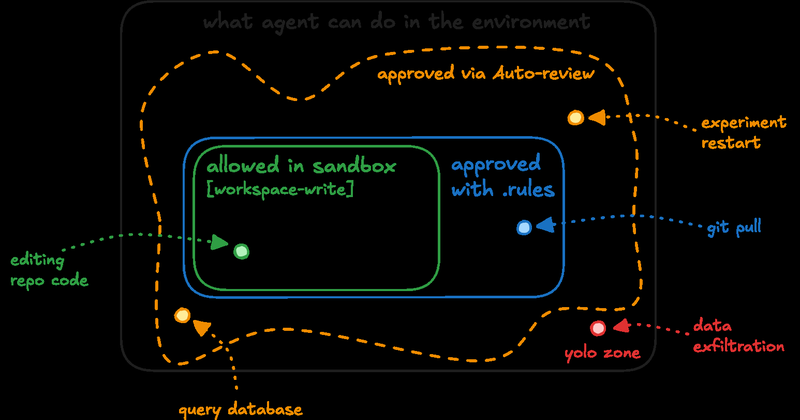
讨论编码 Agent 在执行越界或高风险动作时,如何在没有同步人工审批的情况下进行安全审查。

这篇论文解决的是 SWE-agent 中代码编辑接口的上下文耦合问题:同一个 agent 既要探索代码、保留上下文、制定修改方案,又要生成格式严格的编辑指令,导致无关代码堆积在上下文里,并增加编辑格式失败率。

这篇工作要解决的是 formal theorem proving 中一个长期存在但常被弱化的问题:系统会解题,但不会稳定积累“可迁移的中层知识”。现有方法要么依赖固定 lemma library,适应性差;要么在每道题里临时生成 problem-specific 的中间引理,虽然能帮助当前证明,却很难在后续题目中复用。DreamProver 的核心问题因此不是单题搜索,而是如何让 proving agent 在一组相关定理上迭代学习、抽象、压缩并沉淀出可复用的 lemma library,从而形成跨题目的能力增长。

补足函数级代码生成与仓库级代码编辑之间的评测空档,系统评估模型从规格生成完整类结构的能力。

现有自动ML研究无法实现从算法想法生成到可执行代码的端到端自动化,生成算法泛化性差
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

这篇工作解决的是 LLM workflow 自动归纳问题:不是只优化单个 prompt,也不是在人工写好的 pipeline 上做局部改写,而是同时学习 workflow 的结构和每个节点的具体提示词。难点在于 workflow 是离散的、文本化的、带工具调用和中间状态传递,无法像神经网络那样直接做数值梯度优化。作者试图回答的问题是:能否用纯文本反馈,把“结构搜索”和“模块优化”统一到一个可迭代的 bilevel optimization 框架里。

解决长时程 LLM agent 记忆受文本上下文预算限制、摘要压缩又丢失细节的问题。

评测虚拟角色对话中模型是否能策略性使用长期记忆,而不只是机械检索事实。

在立场检测任务上,系统比较prompting方法与multi-agent辩论方法,澄清哪类LLM推理框架更有效、更划算。

解决企业文档 AI 管线难以端到端评估的问题,把解析、索引、检索和生成的质量放在同一框架中测量。

解决长链推理模型在何时触发检索的问题:传统 RAG 在推理前一次性给上下文,但多步推理往往需要在中途按需补证据。

在“真实资金约束”的长程自治LM代理中,如何把用户意图可靠地转成可验证、可结算的工具动作,并在大规模部署下保持低失败率。

现有实时未来预测任务缺乏统一的交互式学习环境,无法实现预测、真实结果反馈、参数更新的闭环训练,且存在答案泄露问题。

为结构化工作流中的 LLM Agent 提供运行时安全边界,降低恶意或异常工具调用轨迹造成的攻击成功率。

多智能体政策模拟容易出现人工共识:不同价值立场的 evaluator agents 最终收敛到同一选项,削弱模拟的多元性。
用多智能体LLM模拟交易公司做决策
把分析/研究/交易/风控拆分,便于复现实验与对比不同LLM/数据
⚙ 角色化代理辩论+汇总,组合管理审批并接回测/模拟交易
面向终端的多会话编码Agent框架(jcode)。
对比多款CLI,给出RAM/启动耗时数据;适合多会话工作流与低资源环境。
⚙ Rust实现TUI/PTY交互;会话可扩展,支持可选本地embedding以控内存。
给Claude Code提供Browserbase浏览与bb CLI技能集
让编码代理可控地做网页自动化、调试与云函数部署
⚙ 以skills插件封装browser/bb命令,支持远程会话、CDP trace与cookie同步
开源终端式代理开发环境,支持内置或外接CLI代理。
把编码代理放进终端工作流,适合Rust终端与AI编程研究者。
⚙ Rust客户端;可接Claude Code、Codex、Gemini CLI等代理。