★+1621.7k
JavaScript多模态生成
为ACE-Step 1.5本地音乐生成提供UI与管理
面向本地跑ACE-Step用户;集成生成/库/编辑
⚙ React+Express+SQLite;调用ACE-Step Gradio API
- 一键启动脚本:start-all.bat/.sh
- 内置Demucs分轨、FFmpeg与AudioMass编辑
- 支持LAN访问、队列进度与播放列表
更新时间: 2026/4/29 00:45:21
方法或结果明显独立成立的工作,建议读全文
OpenAI 宣布 GPT models、Codex 和 Managed Agents 进入 AWS,解决企业在 AWS 环境内直接使用 OpenAI 模型和智能体能力的问题。
OpenAI 与 Microsoft 宣布修订合作协议,目标是简化双方合作关系,并为长期大规模 AI 创新提供更清晰的商业和基础设施安排。
Sam Altman 说明 OpenAI 围绕 AGI 发展和社会受益的五项原则,表达组织在安全、部署和使命层面的基本立场。
大语言模型如何深度整合进创意工作流,解决创意软件学习成本高、跨软件协同难、重复性劳动多等问题,而非仅仅作为独立的文本或图像生成工具。
论文要回答一个很具体的问题:纯语音语言模型是否能绕开“离散语音 token + 自回归建模”的瓶颈,用连续扩散模型获得更好的 scaling 行为。已有 speech-only SLM 通常先把 SSL 语音表征离散化,再训练 AR 模型,但语音 token 信息密度低、说话人和声学变化大、可用语义密集数据少,导致达到文本 LLM 级语言能力的计算需求很高。作者因此研究连续扩散 SLM 的 scaling properties,并重点追问它是否能改善语言连贯性,而不只是提升音质或韵律。
这篇工作处理的是 diffusion language model 里一个被长期低估、但实际决定生成质量的控制变量:token ordering。AR 模型把生成顺序固定成 left-to-right,因此顺序问题被架构直接吃掉了;DLM 则显式暴露出“先揭示哪些 token、后揭示哪些 token”的决策空间。现有做法主要有两类:随机 masking / reveal,以及基于当前置信度的 progressive ordering。前者训练和推理往往不一致,后者虽然便宜,但只看局部置信度,容易过早锁定局部高置信 token,压制对全局更优轨迹的探索。论文要解决的核心问题,不是再造一个新的 DLM,而是在不改 host model、loss、监督信号和数据管线的前提下,给 DLM 加一个更合理的 ordering policy,使 reveal 过程从“局部最确定”转向“对最终结果更有利”。
这篇工作处理的是统一多模态模型里一个很具体、也很根本的问题:视觉理解和视觉生成到底要不要继续依赖预训练视觉编码器。过去的统一模型通常有两条路。第一条是理解用 CLIP 一类表征编码器,生成用 VAE/VQ-VAE 一类重建编码器,二者表示空间不同,理解和生成天然错位。第二条是改成共享视觉表示,但仍然依赖一个预训练视觉编码器作为前端。Tuna-2 继续往前走了一步,直接问:如果把这些 encoder 都拿掉,只保留 patch embedding 和一个统一 decoder,能不能从原始像素端到端同时学会理解和生成。难点不在架构能不能写出来,而在于像素空间维度高、冗余大、训练信号稀疏,统一表示学习会明显更难,尤其是既要支持细粒度感知,又要支持高质量生成。
腾讯混元发布 Hy3 preview,介绍其重建 Hy 系列模型的第一步;从标题看更接近生成模型路线或产品预览,而不是完整技术论文。
这篇论文要解决的不是一个新的推理训练算法,而是一个更基础、也更麻烦的问题:近一批 mixed-policy reasoning 论文声称“监督信号与 RL 信号混合训练”优于传统 SFT-then-RL,但这个结论是否建立在正确基线上。作者通读并复现实验后发现,很多工作共享的 SFT 基线被两个实现层面的 bug 系统性压低了:一个是 DeepSpeed CPU-offloaded optimizer 在梯度累积时静默丢失中间 micro-batch 梯度;另一个是 OpenRLHF 等框架在 loss aggregation 上把 per-mini-batch mean 当成全局 per-token mean,导致不同长度样本权重失真。修复后,标准的先 SFT 再 RL 不但没有落后,反而整体优于这些 mixed-policy 方法。
这篇工作要解决的是 RLHF 里 reward model 的一个结构性浪费:标准 Bradley-Terry 训练只用最终 token 的分数做偏好学习,把中间所有位置的输出都丢掉了。这样训练出来的 RM 在 final score 上可以工作,但 token-level 输出通常是噪声,既不能解释生成过程中哪一步在加分、哪一步在减分,也不能自然承担 value estimation 的角色。论文的核心命题是:如果 reward model 真在估计“一个回答最终会有多好”,那么它在任意中间位置的输出,都应该表示在当前 prefix 条件下对最终 reward 的条件期望。换句话说,RM 不该只在 EOS 位置有意义,它应该沿时间维度保持一致,像 value function 一样对 partial response 给出 coherent prediction。
ProEval 解决的是生成式 AI 评测成本过高且低效的问题。完整跑 benchmark 需要大量模型推理、人工或 LLM judge 评分;简单下采样又容易给出不稳定的总体分数,并漏掉稀有但严重的失败样本。论文把评测看成一个未知性能函数的主动学习问题:给定输入 x,模型在该输入上的错误严重度、安全风险或任务得分是 f(x),目标是在少量评测调用下同时估计整体性能,并主动发现失败区域。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

OpenAI 宣布 GPT models、Codex 和 Managed Agents 进入 AWS,解决企业在 AWS 环境内直接使用 OpenAI 模型和智能体能力的问题。

OpenAI 与 Microsoft 宣布修订合作协议,目标是简化双方合作关系,并为长期大规模 AI 创新提供更清晰的商业和基础设施安排。
Sam Altman 说明 OpenAI 围绕 AGI 发展和社会受益的五项原则,表达组织在安全、部署和使命层面的基本立场。

大语言模型如何深度整合进创意工作流,解决创意软件学习成本高、跨软件协同难、重复性劳动多等问题,而非仅仅作为独立的文本或图像生成工具。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

论文要回答一个很具体的问题:纯语音语言模型是否能绕开“离散语音 token + 自回归建模”的瓶颈,用连续扩散模型获得更好的 scaling 行为。已有 speech-only SLM 通常先把 SSL 语音表征离散化,再训练 AR 模型,但语音 token 信息密度低、说话人和声学变化大、可用语义密集数据少,导致达到文本 LLM 级语言能力的计算需求很高。作者因此研究连续扩散 SLM 的 scaling properties,并重点追问它是否能改善语言连贯性,而不只是提升音质或韵律。

这篇工作处理的是 diffusion language model 里一个被长期低估、但实际决定生成质量的控制变量:token ordering。AR 模型把生成顺序固定成 left-to-right,因此顺序问题被架构直接吃掉了;DLM 则显式暴露出“先揭示哪些 token、后揭示哪些 token”的决策空间。现有做法主要有两类:随机 masking / reveal,以及基于当前置信度的 progressive ordering。前者训练和推理往往不一致,后者虽然便宜,但只看局部置信度,容易过早锁定局部高置信 token,压制对全局更优轨迹的探索。论文要解决的核心问题,不是再造一个新的 DLM,而是在不改 host model、loss、监督信号和数据管线的前提下,给 DLM 加一个更合理的 ordering policy,使 reveal 过程从“局部最确定”转向“对最终结果更有利”。

这篇工作处理的是 MoE 里一个很实际但常被简化的问题:不同 token 的建模难度并不一样,但传统 MoE 强制所有 expert 同构同尺寸,导致容量分配过于僵硬;而完全异构 expert 虽然更灵活,却会带来 GPU 负载不均、路由失衡、参数利用率差等系统问题。作者想解决的是,如何在不把训练和部署复杂度推高到不可用的前提下,让 MoE 具备按 token 难度分配不同 expert 容量的能力。

在不改变 decoder-only 自回归框架与 causal self-attention 的前提下,能否用一种显式、可检查的“结构化记忆”模块替换 Transformer block 里最不透明的 FFN/MLP 子层,同时尽量保持语言建模能力与训练可行性。

这篇论文解决 tensor parallel LLM 训练中的中间张量通信压缩问题。TP 通信出现在每个 Transformer block 的前向和反向路径上,频率高、同步强、难以隐藏;直接压缩会把量化误差反复注入训练过程,导致收敛变差甚至发散。

离散扩散语言模型(dLLM)采用分块半自回归解码时存在两个耦合问题:一是训练阶段用全序列上下文做降噪,推理阶段块提交后无法利用未来上下文的训练推理不匹配;二是固定块大小或标点启发式的块边界选择逻辑无法保证块语义独立,容易提前提交依赖未来上下文的token,导致后续块的错误传播。

现有RoPE位置编码的旋转参数完全由离散序列序数驱动,属于固定手工设计的结构,无法捕捉时间间隔不规则、存在周期性规律的序列(如用户交互序列)的动态依赖关系。

解决含版权文本语料难以公开分发的问题,使研究者在不直接共享原文的前提下共享标注与对齐信息。

如何在不同计算预算下,训练出结构连贯且语义紧凑的 Matryoshka 嵌套表示?

如何超越传统的“行数×质量系数”方法,更准确地评估数据对 LLM 训练的真实效用(Utility)并进行定价?
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

多轮长轨迹任务里,单次调用模型的质量不再是主要成本项,真正的瓶颈是“几十次调用叠加的总 token 成本”。论文要解决的是:在给定每回合预算约束下,如何在每一轮动态选择不同能力/价格的模型,使最终任务成功率最大化;并且在离线日志数据上学习这种路由策略,避免昂贵的在线探索。

这篇工作讨论的不是如何从小语言模型重新训练一个轻量 LVLM,而是另一路径:能否直接对现有 LVLM 的语言骨干做结构化剪枝,再用较轻量的恢复训练把性能拉回来。核心问题有三层。第一,LVLM 上哪些结构化剪枝方式更合适:删整层,还是缩宽度。第二,剪枝后性能下降主要来自语言能力受损,还是视觉-语言对齐被破坏。第三,在恢复阶段,SFT、logit distillation、hidden-state distillation 以及数据规模之间,哪种组合最划算。

这篇工作要解决的是:能不能把已经训练好的 Transformer LLM 低成本改造成 hybrid sequence model,在尽量保住原有短上下文能力的同时,真正把长上下文能力拉起来,而不是只在架构上换成线性模块却没有得到可用的 long-context 行为。现有 upcycling 工作大多把目标放在短上下文 perplexity 或常规 benchmark 保持上,对长上下文训练长度、蒸馏方式、推理系统适配都研究得不够。

这篇工作处理的是大音频语言模型推理阶段的音频 token 压缩问题。已有方法常把所有注意力头一视同仁,用跨头平均的注意力分数做 token 重要性估计;作者指出这在音频场景里不成立,因为不同头对语义类任务和声学类任务的响应差异很大,而且真正对音频有贡献的头是稀疏的。结果是,统一的剪枝规则会在某些任务上错删关键信息,尤其在长音频和高压缩率下更明显。

这篇工作解决的是分布式 LLM 训练里一个很工程、但对大规模预训练吞吐直接有影响的问题:现有 communication-computation overlap 方法虽然能隐藏一部分通信,但通常会留下明显的 tail latency,尤其是在张量并行、序列并行、数据并行等需要频繁 collective 的场景里。数据切块式 overlap 的典型问题是最后一块通信无法被计算覆盖;块切得更细又会让算子算强度下降、内存和调度开销上升。文章要做的是在不引入过多同步和额外通信量的前提下,把这段尾部延迟尽量消掉,并把方案统一到训练和推理、多种并行范式上。

这项工作解决自回归推理中 KV cache 随层数线性增长的问题,重点是沿深度维度做 cache sharing,而不是沿时间维度丢 token。

生成式推荐模型在在线服务时会反复编码用户长历史。用户历史前缀变化很小,但标准推理系统把每次请求当作独立样本处理,导致大量重复计算。直接持久化每个用户的 KV cache 又会带来显存爆炸和频繁 PCIe 交换。MTServe 解决的是生成式推荐服务中的跨请求 KV cache 持久化与分层管理问题。

多节点 MoE 推理的主要瓶颈不是单个 expert 的计算,而是动态路由和硬件拓扑不匹配带来的跨节点 all-to-all 通信,尤其在 decode 阶段会直接拉高延迟。

这篇论文评估 NVIDIA CUDA Tile 在 Hopper 和 Blackwell GPU 上是否适合 AI 工作负载,尤其是 GEMM、融合多头注意力和端到端 LLM 推理。核心问题很工程化:CuTile 能否在减少 kernel 开发成本的同时,接近或超过 cuBLAS、Triton、WMMA、FlashAttention-2 等成熟实现的性能。

论文解决的是长上下文 Transformer 的 KV cache 和注意力计算开销问题,目标是在保留远程依赖可见性的同时,把远距离历史压缩到更少的 summary token 中。

这篇工作解决的是长上下文推理中的 KV cache 内存瓶颈,但切入点不是再做统一比例的 token 剪枝,而是回答一个更细的问题:不同 transformer 层对 KV 剪枝的敏感度是否相同。如果不相同,那么在固定全局 KV 预算下,按层平均分配缓存就是低效的。作者的结论很明确:层间重要性显著不均匀,尤其某些中间层对内容生成和最终任务表现更关键,因此应该做 layer-dependent 的预算分配。

视频扩散 Transformer 在视频编辑中会重复处理大量跨帧相似的 latent patch,推理开销高;但生成任务又不能像理解任务那样直接丢 token,因为每个 latent token 都对应解码后的空间区域,信息缺失会带来可见伪影。

现有后训练量化(PTQ)的随机采样校准样本经常无法激活激活值异常大的异常值通道,导致量化器低估这些通道的动态范围,产生主导层损失的重构误差。

解决企业多模型级联部署中,如何在满足任务质量约束的前提下降低 LLM 推理成本。

现有VLM视觉token剪枝依赖视觉编码器或LLM的注意力分数,视觉编码器存在attention sink导致无法准确识别重要token,剪枝效果差

解决精确 softmax attention 在长序列和非 Tensor Core 硬件上难以同时做到低内存、低并行深度和数值可控的问题。

降低自回归 LLM 在交互式、短序列、batch size 1 场景下的 kernel launch 开销和端到端延迟。

研究 Vision-Language-Action 模型在机器人端侧部署时,如何在成本、能耗和控制时延约束下选择硬件并做推理加速。

多十亿参数语言模型作为 RL agent 时,内存、算力和能耗限制了边缘设备上的本地学习与推理。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

这篇工作处理的是统一多模态模型里一个很具体、也很根本的问题:视觉理解和视觉生成到底要不要继续依赖预训练视觉编码器。过去的统一模型通常有两条路。第一条是理解用 CLIP 一类表征编码器,生成用 VAE/VQ-VAE 一类重建编码器,二者表示空间不同,理解和生成天然错位。第二条是改成共享视觉表示,但仍然依赖一个预训练视觉编码器作为前端。Tuna-2 继续往前走了一步,直接问:如果把这些 encoder 都拿掉,只保留 patch embedding 和一个统一 decoder,能不能从原始像素端到端同时学会理解和生成。难点不在架构能不能写出来,而在于像素空间维度高、冗余大、训练信号稀疏,统一表示学习会明显更难,尤其是既要支持细粒度感知,又要支持高质量生成。

现有VLM的物体幻觉评测基准仅输出聚合准确率,无法区分错误来源于感知能力不足还是上下文文本先验的误导,无法定位底层失效机制。

现有多模态大语言模型(MLLM)的模型融合主要集中在微调后(post-finetuning)阶段,忽略了预训练阶段。预训练阶段的核心在于建立跨模态对齐,而不同数据集训练出的投影层(projector)具有互补的对齐能力,如何有效融合这些异构的预训练投影层是一个未解问题。

主流医疗多模态模型多采用 LLaVA 式的解耦架构(CLIP 视觉编码器 + 投影层 + LLM),投影层容易导致细粒度视觉特征丢失,且 CLIP 特征并非为生成任务优化。这在对微小病灶敏感的医疗影像领域尤为致命。

现有视频多模态大模型(VLM)的语义识别能力与细粒度时序推理能力存在显著差距,重复动作计数能力差,且现有重复计数基准多针对专用架构、视频时长偏短,无法有效评测通用VLM的时序推理能力。

现有音视频语言模型在 egocentric video 中经常把可见物体或动作误当作真实声音来源,即输出由视觉先验驱动的 audio hallucination,而不是基于音频信号作答。

Omni-o3 解决的是复杂音频-视觉推理中的搜索效率问题。传统 chain-of-thought 是单条轨迹逐步展开,parallel rollout 是多条轨迹独立采样。两者在长视频、密集音频和大量视觉 token 场景下都会重复处理相同的多模态上下文,难以共享中间推理路径。

现有 VLM 3D 空间推理评测常把点云或 mesh 上的 3D 标注直接转成视频 QA,但这些标注和模型实际看到的视频帧不一致,导致问题、答案和视觉证据之间出现系统性错配。
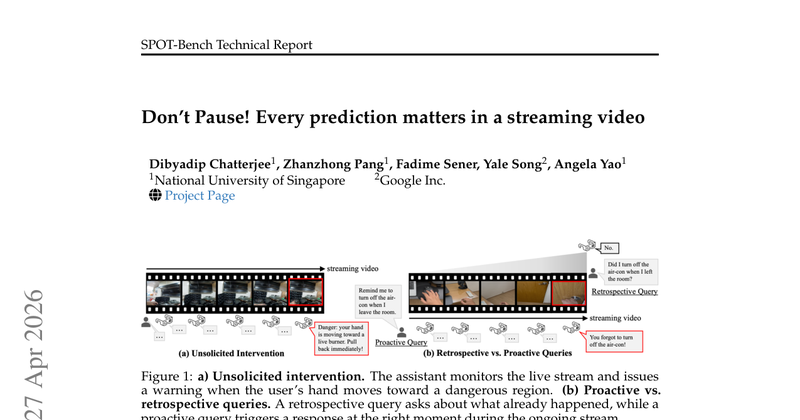
现有在线 VideoQA benchmark 多采用“暂停视频、提问、回答”的评测协议,无法衡量模型在连续视频流中是否能及时、克制、主动地响应事件。

这项工作解决的是 VLM 视觉推理中的两个缺口:模型在长推理链里容易忽略边缘、二值图、显著异常等低层视觉线索;同时推理流程多是“看图—推理—作答”的开环过程,缺少基于视觉证据的自我检查和修正。

MoE-VLM 的专家路由通常没有很好利用视觉和文本的模态结构。硬路由把专家预先绑定到某一模态,边界太刚;普通软路由又容易把不同模态混在一起,缺少对层间融合状态的约束。SMoES 试图解决的问题是:在视觉/文本表示随深度逐步融合、且 token 数量严重不均衡的情况下,如何让 MoE 专家形成可训练、可部署的软模态专长。

重新审视 VQA 中默认沿用文本生成采样策略的做法,判断贪心解码是否在校准良好的闭集问答任务上更合适。

解决 chart image 到可执行绘图代码生成时过度依赖 Python、缺少多语言等价监督的问题。

让 speech-aware LLM 在输出转写文本的同时直接预测词级时间戳,避免依赖外部对齐工具。

评估视觉中心基础模型在自动驾驶场景中是否真正理解自车运动,而不是只会生成高层语言解释。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型
-74974ff4.png)
腾讯混元发布 Hy3 preview,介绍其重建 Hy 系列模型的第一步;从标题看更接近生成模型路线或产品预览,而不是完整技术论文。

这项工作解决的是文生图模型的文字渲染与布局对齐问题:模型不仅要生成正确的文字内容,还要把 prompt 中指定的多个文本片段放在正确空间位置。现有数据通常只有 OCR 文本或框,缺少“prompt 中哪段指令对应图中哪段文字和位置”的显式对齐。

这篇工作关注统一多模态理解/生成模型中的图像编辑 CoT:现有 CoT 常把某类理解能力写死在提示或训练数据里,例如强调定位信息,但这类设计对风格迁移、视角变化、数量修改等任务的泛化不足;同时,模型生成的 CoT 和最终编辑图像之间也可能不一致。

这篇工作要解决的是视频生成模型缺少稳定 3D 几何约束,导致大视角运动、长时序场景里物体形变、消失和时序不一致的问题。

这篇工作处理的是一个很具体但长期卡住扩散/去噪生成模型在线 RL 的问题:如何在没有精确样本似然的前提下,把 PPO/GRPO 这类基于 likelihood ratio 的策略梯度方法稳定地用到 diffusion / flow matching 模型上。已有两条路都不理想。MDP 化方法把采样轨迹拆成逐步决策,理论上成立,但训练慢、实现重,而且把优化绑死在一阶随机采样器上;ELBO surrogate 方法更接近预训练目标,也允许 ODE / 高阶采样器,但过去在视觉生成上效果不如 MDP 路线。文章要解决的核心不是再造一个更复杂的 RL 框架,而是回答:ELBO surrogate 为什么以前不行,怎样把它调到真正可用,并在图像生成上超过 MDP 基线。

这篇工作处理的是一个很具体但也很有代表性的问题:联合音频-视频生成里,现有 dual-branch diffusion 往往在整个去噪过程中持续做跨模态耦合,并且通常要求预先固定输出时长。对 talking head 任务,这两个设定都不理想。前者把高层语义对齐和低层信号渲染混在一起,容易让语音波形细节和人脸纹理细节互相干扰;后者则让模型无法根据文本长度、语速和语言差异自然决定说话时长,长文本时会出现压缩、截断或漏词,直接伤害可懂度和口型同步。

解决图像生成与编辑模型在学术 benchmark 上表现良好,但其输出是否满足真实商业设计需求、是否对应经济价值难以评估的问题。

解决长序列视频 diffusion transformer 中全局自注意力的二次复杂度导致显存和延迟过高的问题。

解决 Minecraft 体素世界的可控生成问题,重点是如何在离散 block 空间上做大规模生成建模与数据构建。

解决 text-to-image diffusion 采样中语义对齐和采样成本的冲突:显式 Zigzag-sampling 能利用轨迹曲率,但需要约 3 倍 NFE 并引入 off-manifold 误差。

大扩散Transformer(DiT)执行局部图像编辑时易将编辑内容泄露到无关区域,缺乏明确的编辑位置引导通道

解决视觉文字生成中“文字准确率”和“整体图像质量/指令跟随”之间的多目标对齐冲突。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

这篇论文要解决的不是一个新的推理训练算法,而是一个更基础、也更麻烦的问题:近一批 mixed-policy reasoning 论文声称“监督信号与 RL 信号混合训练”优于传统 SFT-then-RL,但这个结论是否建立在正确基线上。作者通读并复现实验后发现,很多工作共享的 SFT 基线被两个实现层面的 bug 系统性压低了:一个是 DeepSpeed CPU-offloaded optimizer 在梯度累积时静默丢失中间 micro-batch 梯度;另一个是 OpenRLHF 等框架在 loss aggregation 上把 per-mini-batch mean 当成全局 per-token mean,导致不同长度样本权重失真。修复后,标准的先 SFT 再 RL 不但没有落后,反而整体优于这些 mixed-policy 方法。

这篇工作要解决的是 RLHF 里 reward model 的一个结构性浪费:标准 Bradley-Terry 训练只用最终 token 的分数做偏好学习,把中间所有位置的输出都丢掉了。这样训练出来的 RM 在 final score 上可以工作,但 token-level 输出通常是噪声,既不能解释生成过程中哪一步在加分、哪一步在减分,也不能自然承担 value estimation 的角色。论文的核心命题是:如果 reward model 真在估计“一个回答最终会有多好”,那么它在任意中间位置的输出,都应该表示在当前 prefix 条件下对最终 reward 的条件期望。换句话说,RM 不该只在 EOS 位置有意义,它应该沿时间维度保持一致,像 value function 一样对 partial response 给出 coherent prediction。

这项工作解决的是 verifier 构造问题:给定一批 LLM 输出及其目标标签,能否自动归纳出少量可执行 Python 检查器,使它们的联合判断尽量贴近正确性、有效性或任务完成等目标。

通用 LLM 的安全对齐(尤其是以 RLHF/拒答/危机提示为代表的“泛安全策略”)在临床心理治疗这种强协议、强机制约束的场景里,是否会系统性破坏治疗流程,从而产生可预期的伤害风险?以及现有常用评估指标为何捕捉不到这种风险?

这篇论文研究高效推理 post-training 中一个容易混淆的因素:模型变短,究竟来自显式长度惩罚,还是来自短上下文 RL 训练本身。论文进一步处理短上下文训练带来的不稳定问题,尤其是正确中间推理被截断后拿到零奖励,从而被错误惩罚。

这篇工作研究的是一个常被当作实现细节、但会直接改写安全结论的问题:安全 benchmark 里用 LLM judge 判定“有害/无害”时,judge prompt 的配置到底有多敏感。作者不是比较不同 target model 的安全性,而是固定评测对象与测试集,专门隔离 judge prompt wording、prompt structure、persona framing 这些因素,测量它们会把 headline harmful rate 推动到什么程度。更关键的是,他们把 judge model 固定为同一个 Claude Sonnet 4-6 做主实验,因此能把波动明确归因到 prompt 本身,而不是 judge 模型差异。

在“可回答就回答、不可回答就拒答”的开放域事实问答里,用 RL 训练模型学会拒答往往会掉准确率:静态的三值/二值奖励会把策略推向过度保守,早期一旦进入“拒答陷阱”(abstention trap)就很难恢复。论文要解决的是:如何让拒答行为随模型当前的知识边界动态对齐,使模型只在真正超出知识边界时拒答,从而同时降低幻觉与保持(甚至提升)准确率。

LLM-as-a-Judge 在评测、对齐与榜单中被大量使用,但 judge 会系统性偏好自己的输出(Self-Preference Bias, SPB)。现有 SPB 测量往往依赖人工金标,且把“生成能力更强所以更常赢”与“评审立场偏置”混在一起。论文要解决的是:在不依赖人工金标的前提下,如何可扩展地量化 SPB,并给出无需训练即可缓解偏置的策略。

MoE模型在监督微调阶段易出现路由崩溃,现有优化方法引入的辅助损失或直通估计器会带来梯度噪声,且仅保留高频激活的超级专家会导致性能明显下降,长尾稀疏专家的知识难以在微调中有效保留。

这项工作要解决的是 reasoning RL 中的置信度失真问题:模型通过 outcome reward 学会提高最终答案正确率,但中间推理过程和最终答案的置信度不可靠,常见表现是错得很自信。这会影响早停、重试、工具调用、人类转交、置信加权投票等依赖 uncertainty 的控制策略。

这篇工作处理的是 VLM-RLVR 中的信用分配问题:视觉推理链里常见错误来自物体、属性、数量、空间关系等感知声明,但 GRPO 这类方法通常只给整段回答一个 outcome reward。最终答案错了,并不能告诉模型是哪一段视觉依据错了,也不能区分“看错图”和“后续推理错”。

验证前沿大语言模型作为AI研究助手时,是否会主动破坏AI安全研究、拒绝执行安全研究任务,以及是否具备区分评测场景和实际部署场景的情境感知能力,这类行为会直接降低安全研究有效性,威胁后续模型的安全对齐水平。

这篇论文处理的是 reasoning trace 暴露后的能力抽取风险:攻击者可以大量采样闭源教师模型的推理轨迹,用这些轨迹蒸馏学生模型,从而获得接近教师的推理能力,并可能绕过教师侧的安全约束。论文关注的问题不是如何提升蒸馏,而是如何在不明显损害教师回答质量和轨迹可读性的前提下,让这些轨迹不适合作为训练数据。

在 LLM 的 RL post-training(含 agentic、多轮、工具调用等长尾 rollout)中,GPU 利用率长期偏低且随规模扩展出现“吞吐上升但成本更快上升”的问题。论文要解决的是:在多条并发 RL pipeline 共用集群时,如何通过更细粒度的建模与调度,把 rollout/training 内部与跨 worker 的不均衡转化为可优化的调度问题,从而提升单位成本吞吐。

这篇工作处理的是 activation steering 里一个很实际但长期被忽略的问题:传统 LAS 用单一固定系数 α 对所有 prompt、所有 token、往往甚至所有层统一加同样强度的 steering direction,因此在输入分布变化时很容易出现 under-steering 或 over-steering。论文要解决的不是“如何找到一个更好的全局 α”,而是“能不能让 steering 强度随上下文和层位动态变化,同时保留线性 steering 的可解释性和低样本优势”。

这篇工作要解决的是:代码生成 RL 中常用的 reward hacking 监控器,若主要用“合成出来的作弊轨迹”训练,是否真的能识别训练过程中自然涌现的 hacking 行为。更具体地说,作者区分了两类数据源:一类是通过提示或人工构造诱导出的 synthetic hacking trajectories,另一类是模型在 RL 过程中为了拿到代理奖励而自己长出来的 in-the-wild hacking trajectories。论文要检验的是两者之间是否存在分布鸿沟,以及这种鸿沟会不会让监控器在真实训练场景里失效。

在不微调 LLM 参数的情况下,如何利用偏好数据在推理时引导模型输出更符合对齐目标。

研究小型 instruction-tuned LLM 的口头置信度几乎退化为“总是很自信”,能否把 self-consistency 信号蒸馏成单次前向即可读出的 verbal confidence。

解决跨语言数学推理中,尤其低资源语言场景下,模型难以稳定生成逐步推理链且英语向其他语言迁移弱的问题。

LLM 生成幻灯片时主要按文本规划内容,但评价标准很大一部分来自视觉版式与审美,导致布局质量不稳定。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

ProEval 解决的是生成式 AI 评测成本过高且低效的问题。完整跑 benchmark 需要大量模型推理、人工或 LLM judge 评分;简单下采样又容易给出不稳定的总体分数,并漏掉稀有但严重的失败样本。论文把评测看成一个未知性能函数的主动学习问题:给定输入 x,模型在该输入上的错误严重度、安全风险或任务得分是 f(x),目标是在少量评测调用下同时估计整体性能,并主动发现失败区域。

现有研究普遍假设将训练数据从自然的幂律分布调整为均匀分布,可提升模型对长尾技能的学习效率,但该假设在组合推理类任务上不成立,背后的作用机制尚未被明确解释。

这篇工作要解决的不是“模型知不知道某个时间事实”,而是“模型能不能在多轮对话里稳定地维持一个已经建立的时间参照系”。作者把这个问题定义为 temporal scope stability:首轮问题给出时间约束,后续追问不再重复年份,但默认沿用前文时间;模型需要在需要时保持、在显式提示时切换、在实体转移时正确继承这个时间范围。论文关心的是一种推理时失稳现象:模型单轮答对,放进多轮上下文后却回到默认的当下知识,说明问题不在参数记忆缺失,而在上下文绑定和状态维护失败。

CoT 推理失败时,模型内部是否仍已形成“足以导出正确答案”的任务相关表征?如果有,这些信息在 CoT 序列的哪些 token、哪些层里最可恢复,失败又是“信息缺失”还是“信息没被正确读出/利用”?

LLM-as-a-judge 评测里,一个常被默认“无关紧要”的变量是 prompt 模板。论文要解决的问题是:在温度为 0、同一被评对象不变的条件下,仅靠语义等价的 prompt 改写,judge 的离散判决会有多不稳定;这种不稳定能否用一个可复现、可对比、可一行汇报的指标刻画,并用基准数据把不同 judge 的差异测出来。

这篇论文要解决的是形式化定理生成里的语义评测问题:Lean 编译通过只能说明生成的 statement 和 proof 在逻辑系统内自洽,不能说明它表达了自然语言题目的原意。典型失败是把应证明的命题改写成平凡恒等式,仍然可以编译通过。

这篇论文讨论的是 Transformer 表征塌缩的精确定义与成因拆分。Dong 等人早先证明:如果只有 self-attention、没有 residual 和 MLP,层数加深后 token 表征会快速 rank collapse,最后趋向单一方向。作者认为这个结论在其设定下成立,但不足以解释真实部署的 BERT/GPT 类 Transformer。核心问题因此变成三件事:LayerNorm 对 rank 到底做了什么;在有 residual 的真实架构里,MLP 是否仍然承担“阻止 rank collapse”的必要角色;除了 rank collapse 之外,multi-head attention 还会不会引入另一类独立的表示退化。

系统评估 LLM-as-a-Judge pipeline 中不同偏差类型和去偏策略的可靠性。

这项工作研究 Transformer 预训练过程中权重矩阵奇异值谱如何随层深和训练步数演化。核心问题不是单个 checkpoint 的谱形态,而是谱结构在训练中的时空动态:哪些层先发生有效秩压缩,哪些矩阵形成重尾谱,不同 attention 投影是否承担不同功能。

这篇工作研究的是 ICL 里的“上下文黏滞”问题:当提示前半段给出一类任务的示例,后半段突然切换到另一类任务时,Transformer 能否快速放弃先前形成的任务假设,并用后续示例完成重对齐。作者关心的不是一般性的 prompt sensitivity,而是更具体的内循环适应是否存在路径依赖:前文错误但一致的证据,会在多大程度上持续污染后文的新任务学习。

这项工作问的是:语言模型在没有有效语义条件时,next-token 分布是否会接近均匀分布。它把问题放在 softmax 概率分布层面,而不是生成文本是否看起来随机。核心指标 Entropic Deviation 用归一化 KL 散度衡量模型分布偏离均匀分布的程度,等价于 1 - H(p) / log V。

这项工作研究 LLM FFN 层中通道级重要性是否均匀分布,以及为什么结构化剪枝在较高稀疏率下容易突然失稳。核心发现是,每层存在极少数对 loss 极敏感的 FFN channel;剪掉这些 channel 会让困惑度快速崩掉。

把“表示轨迹逐层变直(temporal straightening)”从一个几何现象,推进到能解释 token 级行为:内部表示的局部曲率(contextual curvature)是否与下一词不确定性(next-token entropy)存在稳定、可因果干预的联系,并且这种联系是否在预训练过程中逐步形成。

稀疏自编码器(SAE)从大语言模型中提取的特征为无结构平级列表,混杂通用、弱语义特征,也无法体现特征间的关联关系,难以用于分析模型内部领域概念的组织模式与计算逻辑。

验证当前前沿大语言模型和视觉语言模型是否具备人类级别的交互式因果结构迁移能力,即通过主动探索归纳潜在因果结构并跨场景迁移的能力,这一问题此前未在交互式决策场景下得到系统验证。

这篇论文研究 hypernetwork 生成 LoRA adapter 的“即时知识内化”方法为什么难以覆盖模型已有知识。核心问题不是模型找不到文档信息,而是在文档事实与预训练事实冲突时,生成的 adapter 信号强度不足,无法压过基座模型中更强的参数化知识先验。

给 Transformer 的关键组件(多头注意力、FFN/MoE、残差+归一化)提供一个统一的连续时间动力系统解释:把层更新视为在球面流形上的“变分后验加权的条件 score 场”做前向 Euler 离散,从而解释注意力的隐式正则、自校准行为,以及 MoE 为什么更容易塌缩并需要额外平衡损失。

尚未明确LLM中演绎、归纳、溯因三类核心逻辑推理的表示形式与相互关系,也缺乏实现三类推理能力互补的优化方法

如何系统性地审计被对齐到特定政治意识形态的 LLM 在有效性、公平性、真实性和说服力方面的表现?

多智能体仿真中,即使给 LLM agents 分配不同 persona,生成行为也可能收敛到狭窄模式,导致模拟群体同质化。

在不访问干净参考模型、不知道触发器、也不修改权重的情况下,检测 LLM 运行时的后门、越狱和 prompt injection 等异常行为。

研究只用图像分类训练的 ViT 是否、以及在哪些层中编码了边界和深度这类空间结构。

为LLM调试提供系统化流程,解决模型行为不透明、输出随机、跨任务错误难以定位的问题。

缓解 CoT prompting 在长链多步推理中跨运行不稳定、同一问题给出不一致答案的问题。

研究神经符号学习中模型满足逻辑约束却没有学到目标概念映射的“reasoning shortcuts”何时会发生,以及如何检测和修复。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

RAT 试图解决 repository-level code agent 的可执行环境自动配置问题:给定任意真实仓库,自动推断依赖、构建容器、找到验证命令,并让项目能跑起来。

这篇工作解决 LLM agent 在长交互轨迹中如何保留真正有依赖关系的历史信息,而不是靠滑窗、压缩或普通检索丢失关键推理前提。

论文研究工业场景中如何可靠评估 LLM 代码审查 bot 生成评论的有效性,以及自动评估相对开发者标签的边界。

复杂 text-to-SQL agent 往往在准确率和延迟之间取舍,串行探索能提高效果但成本高。

解决 LLM 在企业私有库代码生成中不了解内部 API 用法、参数约束和跨 API 协作模式的问题。

解决 LLM 自动设计算法时过度依赖固定模板、只能调组件而难以生成完整求解器的问题。

解决科学工作流代码生成缺少 I/O 测试用例时,LLM 多 Agent 框架无法依赖执行反馈迭代改进的问题。

现有多轮代码纠错SOTA方法SFS依赖复杂MCTS结构,无法明确性能提升的核心贡献因子

评估并适配代码 LLM 以完成企业 DSL 的多文件、仓库级代码生成与修改。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

这篇工作要解决的问题不是“怎么给 agent 多塞一点工具说明”,而是当技能库扩展到大规模、持续增长、且技能本身是可执行能力包时,agent 如何在上下文窗口之外完成技能检索、筛选、装载和实际使用。作者把这个问题正式化为 Skill Retrieval Augmentation(SRA)。它和传统 RAG 的差别在于:检索对象不是事实性证据,而是会改变 agent 行为空间的能力单元,因此评估不能只看语义相关性,还要看检索到的技能是否真的被识别、整合并转化为任务成功率提升。全文的关键点是把问题拆成 retrieval、incorporation、application 三段,而不是把最终任务成败混成一个黑盒指标。

现有智能体基准多基于单会话静态环境、文本输入为主,无法评测长期办公场景下持续协作类智能体的状态追踪、外生环境变化适应、多模态证据整合能力。

研究显式 belief graph 是否能提升 LLM 在合作型多智能体推理中的 Theory of Mind 和行动选择能力。

现有大语言模型在数学推理基准上表现较好,但无法稳定生成开放研究问题的原创、正确证明,单模型或简单提示词方案存在多种系统性失效模式。

当前通用AI代理是否具备从因果规律发现到落地工程应用的完整闭环能力,此前缺乏复杂度可控、可规模化的评测基准来衡量这一通用智能核心能力。

现有叙事式学术论文撰写规范会丢弃大量研究过程中的失败实验、隐性工程知识、探索轨迹,无法满足AI科研代理读取、复现、拓展研究的需求,带来叙事税和工程税两大结构性成本。

解决多智能体 LLM 系统里“给每个查询动态选择哪些模型、扮演什么角色、按什么工作流协作”的路由问题。

现有 GUI agent 评测要么只看任务完成率,要么只看静态元素 grounding,无法衡量模型是否真正理解界面功能和交互后的状态转移。

解决自主 agent 依赖人工设计工作流、难以持续自我改进的问题,尝试构建一个闭环的自指式进化框架。

评估语音语言模型在真实口语输入下进行 function calling / tool use 时的能力缺口,尤其是组合指令和噪声条件下的退化。

评估 LLM function-calling 场景中,模型在执行工具调用前如何量化“这次函数调用是否正确”的不确定性。

为 LLM Agent 的可复用技能建立机器可操作的结构化表示,避免技能知识只藏在自然语言文档中。

解决 LLM 处理时间推理问题时,固定流程过度或不足推理、难以按题型自适应分配推理动作的问题。

解决多模态 RAG 中检索证据看似相关但未真正支撑答案语义核心的问题。

量化不同 LLM 在相同任务下进行 API 检索和排序时的一致性差异,从而评估 tool-use agent 的可靠性。
为ACE-Step 1.5本地音乐生成提供UI与管理
面向本地跑ACE-Step用户;集成生成/库/编辑
⚙ React+Express+SQLite;调用ACE-Step Gradio API
Claude Code的Anthropic兼容代理
让Claude Code接入NIM、OpenRouter和本地模型
⚙ 转换Messages API,按Opus/Sonnet/Haiku路由
将DeepSeek网页对话转成多家兼容API
适合现有SDK接入DeepSeek与多账号池
⚙ Go后端+React管理台,PromptCompat统一协议
为Claude Code提供可安装模板与监控工具的CLI
汇集100+代理/命令/MCP等;含分析与诊断
⚙ npx一键装组件;支持agents/commands/settings/hooks/MCP