AI Research Daily
更新时间: 2026/4/14 05:52:24
方法或结果明显独立成立的工作,建议读全文
MIXAR: Scaling Autoregressive Pixel-based Language Models to Multiple Languages and Scripts
如何将像素级(无tokenizer)自回归语言模型扩展到多语言多文字体系,并在跨脚本场景下获得稳健的泛化与鲁棒性。
连续扩散在图像等连续模态很强,但在语言建模上,连续扩散语言模型(尤其是embedding-space DLM)长期落后于离散扩散/AR:训练目标缺乏统一理论支撑、PPL/NLL评估缺少可靠的ODE口径、训练技巧(噪声日程/自条件)缺乏可解释的最优设计,导致性能与可复现性都受限。
扩散语言模型(DLM)理论上可并行生成,但长期在质量上落后AR。作者将差距归因于一个结构性缺陷:缺乏“内省一致性”(introspective consistency)——AR模型在训练时会在同一预测规则下隐式地“认可/验证”自己已生成的token(由因果mask+logit shifting带来),而多数DLM在多步双向去噪中并未被训练成与自身生成结果一致,导致连贯性与推理能力受限。
Muon 通过 Newton–Schulz(NS) 迭代近似动量矩阵的极分解/正交因子来改善大模型预训练的优化动力学,但每步需要多次 NS 迭代,带来显著计算与分布式通信开销;核心问题是:能否在减少正交化迭代负担的同时,保持甚至提升 Muon 的训练效果?
自回归(AR)语言模型必须逐 token 生成,推理延迟与计算量随长度线性增长,存在结构性速度上限。连续域的 flow/diffusion 可并行生成,但通常需要昂贵的多步积分/采样。Flow Maps 试图把“从噪声到数据”的轨迹压缩成单步映射以实现一/少步生成,但标准 Flow Map 训练依赖欧式空间的 L2 回归损失,与离散文本(概率单纯形上的分布)几何不匹配,导致效果不佳。核心问题是:如何在离散概率单纯形上,几何一致地训练可一/少步生成的 flow map?
标准子词/ BPE 等分词会以不稳定、与数位无关的方式切碎数字(整数与小数都一样),导致模型丢失“位值/数量级/小数深度”等结构信息,从而出现典型的十进制量级误判(如 9.11 vs 9.9)以及长数算术、科学计数相关推理错误。
过程奖励模型(PRM)需要对 CoT 每一步进行监督,但人工逐步打分成本极高;现有自动化方法(如基于多次 rollout 的 Monte Carlo 估计)虽免人工但计算开销大、生成奖励慢,难以规模化构建高质量 step-level 数据集。
开放式写作的强化微调(RFT)缺乏可验证奖励,通常依赖昂贵闭源评审模型或主观且难标注的人类偏好数据。直接用“模型自信度/对数概率”作内生奖励虽可无评审训练,但会诱发 Triviality Bias:策略向高概率、低熵、模板化输出坍缩,牺牲多样性与内容信息量。
Utilizing and Calibrating Hindsight Process Rewards via Reinforcement with Mutual Information Self-Evaluation
LLM 文本智能体在环境交互式 RL 中普遍面临外部奖励稀疏:只有少数关键动作获得非零回报,导致样本效率低。用模型自评(PRM/生成式过程奖励)提供稠密奖励虽直观,但未经校准会产生系统性偏置(例如过度奖励 inventory),反过来诱导策略学到“刷奖励”的坏习惯并降低任务成功率。
Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning
LLM 后训练 RL 中的核心瓶颈是长序列生成的 credit assignment:奖励通常只在序列末端给一个标量,导致难以判断哪些中间 token/决策真正促成了最终成功。经典 actor-critic 依赖 value function 做细粒度 advantage 估计,但在 LLM 规模下“判别式(discriminative)一发标量预测”的 value model 往往难训、不稳、效果不随规模可靠提升,实践中被 GRPO/RLOO 等 value-free 方法替代,从而把序列问题近似成 contextual bandit,牺牲精细归因能力。
RLVR(Reinforcement Learning with Verifiable Rewards)用序列末端的可验证结果奖励提升推理能力,但带来根本性的 token-level credit assignment 问题:GRPO 等方法把同一个 outcome reward 广播到整条轨迹的所有 token,导致大量“例行续写”与少数“关键分叉决策”获得同等更新,学习信号被稀释或错配。现有工作分别从 reward polarity(正/负样本)或 token entropy(不确定性)出发提出启发式,但缺少统一解释:信用究竟集中在哪里、为何集中、以及应如何调制梯度。
多步 agentic RL(LLM+工具、多轮交互)中,奖励往往延迟且稀疏(常见为最终二值成功/失败),导致“逐步归因(step-level credit assignment)”困难。现有 critic-free(如 GRPO)把同一条轨迹的优势值平均分配到每一步,无法区分哪一步决策真正带来收益;而训练 value/critic(如 GAE)在超大状态空间与稀疏奖励下开销高、易不稳定。
LLM RL后训练普遍默认需要严格on-policy数据,experience replay在LLM RL中被忽视,推高了生成开销。
Why Supervised Fine-Tuning Fails to Learn: A Systematic Study of Incomplete Learning in Large Language Models
论文研究监督微调(SFT)中的“不完全学习现象(ILP)”:即使训练损失已收敛、超参已调优,模型仍会在其自身的训练集上持续、稳定地答错一部分监督样本。这不是灾难性遗忘,也不是刻意遗忘,而是对部分监督信号未能内化。
论文聚焦于一个常被忽视但会系统性误导结论的问题:LLM 评测/标注/审核等“测量流水线”本身存在大量隐藏测量误差(hidden measurement error)。这些误差来自提示词改写、judge 模型更换、温度/采样随机性、条目异质性以及它们的交互,足以导致分数波动、排名翻转、显著性结论反转;而常规只在“固定设置下重复抽样”的置信区间并未覆盖这些来源。
The Myth of Expert Specialization in MoEs: Why Routing Reflects Geometry, Not Necessarily Domain Expertise
论文质疑并系统拆解了 MoE(Mixture of Experts)中广泛流行的“专家专精/领域专家”叙事:我们看到不同领域文本会路由到不同 experts,常被解释为路由器学到了可解释的领域划分;但作者指出这种“专精”并不必然意味着语义或领域层面的专家化,而更可能只是隐藏状态空间几何结构的必然结果。
经典信息论泛化界(如基于KL互信息)通常依赖损失/奖励的有界性或次高斯尾部(MGF存在)。但在RLHF、鲁棒学习、随机优化等现代流程中,奖励/损失/梯度噪声常呈重尾(MGF可能不存在),导致KL工具可能“看起来信息很小但泛化/稳定性被极端事件主导”,从而界变得失效或空泛。本文要解决:在次Weibull(含0<θ<1重尾)条件下,如何构造仍然有效、可用于期望与高概率的、算法依赖的信息论泛化与稳定性分析框架,并落地到RLHF与SGLD。
Transformer能够用少量标注样本完成in-context分类,但推理时到底在“运行什么算法”不清楚。现有常见解释是“隐式梯度下降/优化器模拟”,但在多类线性分类、且处于hard no-margin(几何上更困难)设定下,这种抽象可能误导。本文要解决:如何让推理计算可识别(identifiable)并从训练后的Transformer中抽取出可写成闭式的、逐层递推的推理动力学,从而回答“它在做什么”。
如何让 LLM 在生成时满足“上下文敏感(context-sensitive)”的全局一致性约束(如远距离依赖、计数相等、跨字段一致等),并且不依赖人工手写复杂的形式化约束/语法。
Tracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
后训练(post-training)数据集在 LLM 能力形成中至关重要,但其来源与演化关系(provenance/lineage)缺乏系统记录,导致两类系统性风险难以发现:隐式重叠带来的结构冗余,以及基准测试样本沿数据派生链传播导致的污染(contamination/leakage)。本文要解决的是:如何自动化重建大规模数据集的“谱系图”(lineage graph),并据此量化冗余与追踪污染源头。
重大产品/模型发布、开源发布、行业事件、核心研究员观点(注意:推理加速/注意力优化等技术论文不算行业动态)

企业如何在Cloudflare Agent Cloud上以更安全、可扩展的方式部署基于OpenAI模型的agentic工作流。

发布并定位 Claude Sonnet 4.6:面向 coding、agents 与规模化专业工作负载的前沿模型能力升级。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、MoE、重磅技术报告、新型语言建模方法

如何将像素级(无tokenizer)自回归语言模型扩展到多语言多文字体系,并在跨脚本场景下获得稳健的泛化与鲁棒性。

连续扩散在图像等连续模态很强,但在语言建模上,连续扩散语言模型(尤其是embedding-space DLM)长期落后于离散扩散/AR:训练目标缺乏统一理论支撑、PPL/NLL评估缺少可靠的ODE口径、训练技巧(噪声日程/自条件)缺乏可解释的最优设计,导致性能与可复现性都受限。

扩散语言模型(DLM)理论上可并行生成,但长期在质量上落后AR。作者将差距归因于一个结构性缺陷:缺乏“内省一致性”(introspective consistency)——AR模型在训练时会在同一预测规则下隐式地“认可/验证”自己已生成的token(由因果mask+logit shifting带来),而多数DLM在多步双向去噪中并未被训练成与自身生成结果一致,导致连贯性与推理能力受限。

Muon 通过 Newton–Schulz(NS) 迭代近似动量矩阵的极分解/正交因子来改善大模型预训练的优化动力学,但每步需要多次 NS 迭代,带来显著计算与分布式通信开销;核心问题是:能否在减少正交化迭代负担的同时,保持甚至提升 Muon 的训练效果?

自回归(AR)语言模型必须逐 token 生成,推理延迟与计算量随长度线性增长,存在结构性速度上限。连续域的 flow/diffusion 可并行生成,但通常需要昂贵的多步积分/采样。Flow Maps 试图把“从噪声到数据”的轨迹压缩成单步映射以实现一/少步生成,但标准 Flow Map 训练依赖欧式空间的 L2 回归损失,与离散文本(概率单纯形上的分布)几何不匹配,导致效果不佳。核心问题是:如何在离散概率单纯形上,几何一致地训练可一/少步生成的 flow map?

标准子词/ BPE 等分词会以不稳定、与数位无关的方式切碎数字(整数与小数都一样),导致模型丢失“位值/数量级/小数深度”等结构信息,从而出现典型的十进制量级误判(如 9.11 vs 9.9)以及长数算术、科学计数相关推理错误。

A Tale of Two Temperatures: Simple, Efficient, and Diverse Sampling from Diffusion Language Models
扩散语言模型(dLLM)采样研究长期聚焦“单样本速度-质量”权衡,但在需要多样本的场景(pass@k、test-time compute、A/B、后训练rollout)中,现有高置信度/低置信度优先的贪心remasking会系统性压制跨样本多样性:它倾向于延后不确定位置,从而绕开真正的“分叉点”(forks),导致探索不足、pass@k扩展性差。

扩散大语言模型(dLLM)在性能上逐渐逼近AR,但其“可信度/忠实性”尤其是幻觉(hallucination)机制与模式缺乏系统研究。本文核心问题是:在尽量控制模型规模、架构与参数知识的前提下,dLLM相对AR是否更容易产生外在幻觉(与来源事实不一致)?其随推理计算(denoising步数/解码策略)变化的动态规律是什么?以及扩散范式是否带来独特失败模式?

扩散式语言模型(dLLM/MDLM)理论上可并行、双向建模,但在“完全非自回归(NAR)解码”下常出现推理/规划任务性能崩溃与输出不连贯。论文要回答的核心问题是:阻碍 fully-NAR diffusion 解码可用性的根本失败机制是什么?以及为何解码早期决策会对最终输出产生不成比例的影响?

多语种 LLM 在跨语种生成与理解任务(MT、跨语种摘要、跨语种问答等)上表现不佳,根因包括:预训练语料高/低资源语言严重不均衡,以及以单语 next-token prediction 为主的目标导致“单语偏置”,跨语种对齐不足。论文要解决的是:如何在预训练阶段显式增强跨语种对齐,同时不牺牲单语流畅性,并给出更稳健的对齐度量指标。

论文针对标准 Transformer 注意力块的两点结构性限制:①Q/K/V 仅线性投影导致“线性特征瓶颈”,许多需要非线性组合的注意力特征必须依赖前序层 FFN 多层累积才能出现;②所有信息都被迫经过带位置编码(RoPE)的注意力路径,导致与位置无关的“纯内容信息”(语义类别、实体身份、句法标签等)也被强制做位置路由与混合,可能稀释信号。

Advancing Polish Language Modeling through Tokenizer Optimization in the Bielik v3 7B and 11B Series
论文聚焦“通用 tokenizer 对特定形态丰富语言(波兰语)的结构性低效”。以 Mistral 系通用词表为例,波兰语因屈折变化、变音符号与高词形变体导致被切分成更多子词(高 fertility ratio),从而带来:上下文窗口有效信息密度下降、推理成本上升、生成速度变慢,并可能影响下游质量。

Transformer 的注意力头数/深度/头维度在训练前靠经验固定,导致系统性结构冗余(大量头可删而性能不变),且传统“先大训后剪”无法保证剪完仍“足够”。论文将冗余根因归结为注意力权重乘积 M=WQWK^T 同时混合了对称(互相注意)与反对称(信息流方向性)两种几何功能,模型被迫隐式分解从而浪费容量。

Not All Denoising Steps Are Equal: Model Scheduling for Faster Masked Diffusion Language Models
Masked Diffusion Language Model(MDLM)的采样需要多次全序列去噪,无法利用 KV cache,推理成本高。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

在极小 KV-cache 预算(如 K=16,仅占 4K 上下文的 0.4%)下,现有压缩/淘汰策略在“凭证检索”上会全军覆没(0%)。根因是 dormant tokens:例如 API key、密码、连接串等在大部分上下文中几乎不被注意力关注(attention mass≈0),但会在生成时刻突然变得必须逐字回忆。任何依赖注意力分数、重建损失或学习门控的保留策略都无法识别这类 token 的未来价值。

长输出推理(长链式思考)会导致 Transformer 解码阶段 KV cache 随生成长度线性膨胀,带来两类瓶颈:GPU 显存占用过高(难以部署/批量推理)与注意力计算随缓存增长而变慢。现有 KV 优化多聚焦“长输入 prefill”,对“长输出 decoding”场景适配不足,动态淘汰类方法在复杂推理中易丢失长程关键信息而显著掉点。

KV-cache 压缩主要有两条路线:降秩(删维/投影到低维)与量化(保留全维但降低精度)。社区常分别研究两者,但缺少“在相同存储预算下”的系统对比。本文要回答:在 Transformer 推理 KV-cache 压缩中,到底是降秩更好还是量化更好?以及差距来自哪里。

长链路推理(long-form reasoning)解码时 KV cache 随 token 线性增长,带来显存/带宽/延迟瓶颈,并可能引发推理稳定性下降。现有“推理向 KV 压缩”多以逐 token 重要性打分+驱逐(eviction)为中心,但作者发现:即使改进打分函数,实际保留集合(keep-set)并不会显著重组,说明问题不只是‘更准排序’,而是‘保什么、怎么合并’的结构性定义出了偏差。

后训练压缩(尤其是维度缩减:低秩分解/结构化剪枝等)虽然减少参数量与 FLOPs,却常导致张量维度变得“不规则”(如 128→107),触发 GPU 执行栈在框架调度、库实现与硬件层面的非最优路径,出现“模型更小但更慢”的反直觉现象。作者将其系统化命名为 dimensional misalignment(维度失配)。

长序列 LLM 推理中,KV-cache 随序列长度线性增长,GPU 显存成为主要瓶颈;现有“CPU offload + GPU 保留子集”的方法在“选哪些 token 留在 GPU”上不够精准、更新机制不够强,导致长生成(如 CoT、多步推理、长摘要)中命中率下降、性能与准确率显著退化。

多模态 Transformer(尤其视觉 token + 文本 token)序列更长,标准 softmax attention 的 O(N^2) 计算/显存开销成为扩展瓶颈。线性注意力(Linear Attention, LA)虽在单模态中被研究较多,但在多模态预训练(如 CLIP/OpenCLIP 范式)里能否在保持性能的同时获得可观效率收益仍缺少系统验证。

VLM/MLLM 在推理与(尤其是训练/微调时的反传)中,视觉 token 序列过长导致计算与显存开销巨大;现有“按注意力/范数/相似度”等局部启发式的 token pruning 容易受位置偏置、attention-sink、信息分散影响,在高剪枝率或细节丰富图像上性能下降明显。

长视频/流式场景下视觉 token 随帧数线性增长,导致注意力计算与 KV cache 成本呈二次或高开销增长,MLLM 难以扩展到真实长时应用。现有压缩方法在生产落地上面临三难:压缩比不够、泛化性不足(长视频效率 vs 细粒度推理二选一)、以及与 Flash-Attn/vLLM/SGLang 等推理框架不兼容。

让推理型 LLM 学会“自我管理上下文”:将长链路推理分块并压缩为可复用的致密摘要状态,在保持能力的同时降低上下文/KV cache/计算开销。

现有主流解码采样(Top-k/Top-p/Min-p)通过概率空间截断在“多样性-准确性”间折中,但对温度T极端敏感:T升高会把长尾噪声抬进候选集,导致语义崩塌;而近期logit空间方法Top-nσ虽具温度不变性,却依赖全局方差σ,易被长尾噪声污染,难以刻画头部候选之间的细粒度置信结构与“语义悬崖(semantic cliff)”边界。

长上下文生成中存在一种高破坏性的退化:解码会突然坍缩为持续的重复循环(persistent repetition loops),难以自恢复。作者发现其机制是注意力模式坍缩:部分注意力头“锁死”在历史的一个很短后缀上;同时推理时KV cache复用会把这种轨迹固化。更糟的是,许多KV cache管理策略用“基于注意力的重要性”来保留/驱逐缓存,而在坍缩状态下注意力会对重复片段给出虚高重要性,形成自我强化反馈,进一步降低缓存多样性并放大循环。

在仓库级 agentic coding(如故障定位、补丁生成)中,长上下文推理的主要瓶颈是 KV cache 显存占用随上下文线性增长。现有 KV 压缩/驱逐方法几乎都用 attention 作为“重要性”信号,但对代码而言,语义关键往往由控制流/数据流/调用关系等结构决定,导致 attention-only 压缩会系统性误删对理解至关重要的结构性 token(如 callsite、branch condition、assignment、def-use 链头部等),从而显著损害定位与生成质量。

MoE 大模型在低比特 PTQ(尤其 4-bit)下精度损失的核心瓶颈是 outliers:大幅值激活会拉大动态范围并放大量化误差;即便已有 rotation-based smoothing 能“摊平”部分 outlier,仍存在残余误差。与此同时,MoE 的超大参数规模使得低精度部署对内存与吞吐至关重要,但 outlier 让可靠低精度落地变得困难。

现有数据蒸馏(Dataset Distillation)方法主要停留在单模态或双模态(多为图文)场景,目标通常是用少量合成样本复现真实数据训练轨迹/终点性能。但当模态数>2(omnimodal)时,模态异质性更强、跨模态交互从“成对”升级为“高阶”,导致传统基于两两对齐/两两相似度的蒸馏目标难以统一扩展,并出现更严重的教师-学生训练终点(endpoint)偏差累积问题。

多模态大模型(MLLM)在图像/视频描述与问答中常出现“物体幻觉”(hallucination):生成了画面中不存在的物体,或遗漏真实存在但不显眼的物体。论文指出一个关键根因在解码阶段的注意力分配不公:注意力会向视觉上更显著、面积更大、语料更高频的对象塌缩,导致小物体/稀有物体/边缘物体在解码中缺乏代表性机会,从而 grounding 不充分并诱发幻觉。

ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation
在LLM后训练量化(PTQ)中,兼顾逐层旋转的高精度与可离线融合带来的低推理开销,解决逐层旋转需要在线计算导致的额外延迟问题。

RoPE 在实际实现中存在 split/merge 等向量级操作开销,尤其在 2D/3D RoPE 时导致硬件利用率差,影响大模型训练/推理效率。

SpecMoE: A Fast and Efficient Mixture-of-Experts Inference via Self-Assisted Speculative Decoding
解决MoE推理部署中的高显存/带宽开销与吞吐受限问题,尤其在内存受限与CPU-offload场景下实现更高效的MoE推理。

如何用统一、真实且多样的工作负载来可靠评测 Speculative Decoding(推测解码)在不同数据与服务形态下的加速收益。

在负载突发且多样的在线服务中,如何在“解耦式(disaggregated) prefill/decode”架构下同时兼顾低延迟与高吞吐,并让推测解码深度随运行时动态自适应。

在高并发线上服务场景下,推测解码(Speculative Decoding)因验证阶段算力成为瓶颈而收益下降,如何在吞吐与验证开销间自适应权衡。

在边缘-云协同的speculative decoding部署中,如何在草稿模型/量化/推测长度/异构设备等巨大配置空间里自动选出最优配置以兼顾吞吐、成本与能耗。

树状speculative decoding在扩大分支时可能出现“效率悖论”(开销超线性增长导致负加速),如何在运行时判断何时值得扩树以最大化端到端速度。

解决LLM在异构NPU平台部署时,自回归解码阶段因内存带宽/同步开销导致吞吐与延迟受限、且静态单模型部署出现“模型缩放悖论”的问题。

在DNN/LLM编译中系统性消除不必要的数据搬运(data movement),缓解算力与内存访问延迟差距导致的性能瓶颈。

MLLM生成文本与视觉内容不一致的幻觉问题,如何在不改训练的情况下通过解码阶段动态校准每个token的生成以降低幻觉。

DeCoVec: Building Decoding Space based Task Vector for Large Language Models via In-Context Learning
如何在不训练、不改模型参数的前提下构造可迁移的“任务向量”来稳定提升LLM在特定任务上的生成/推理表现。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
开放式大音频语言模型(LALM)在真实世界长音频、复杂声学场景(噪声、多说话人、跨语种、音乐/环境声混合)上的泛化与推理能力不足;同时训练往往过度绑定学术基准,导致“榜单好看但部署不稳”,且缺少对长音频进行可对齐、可解释推理的机制。

现有视觉语言模型在多模态推理榜单上表现强,但这些评测往往不要求“穷尽式读取”图像细节,掩盖了模型在密集空间转录(dense spatial readout)上的系统性失败。作者提出并验证一种现象:模型在很小的网格规模就会突然崩溃(非渐进退化),即便视觉编码器内部仍保留可恢复的结构信息,最终语言输出却无法忠实表达——称为“Digital Agnosia(数字失认)”。

RMOT(Referring Multi-Object Tracking)要求模型在整段视频中“找出并持续跟踪”所有与文本指代表达匹配的多个目标(可能包含属性、关系、交互与时序约束)。现有方法多为“文本引导检测/分割 + 外部跟踪器”的拼装式流水线,难以端到端学习跨模态时空表征,且受限于RMOT标注视频稀缺、表达歧义与域受限,导致复杂指代与多目标关系推理能力不足。
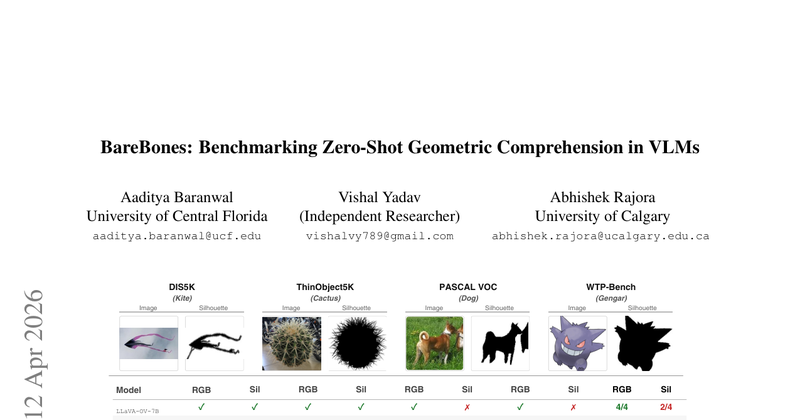
现有VLM零样本评测很难区分“真正的几何形状理解”与“依赖纹理/颜色/背景上下文的统计捷径”。大量基准把语义、纹理与环境线索混在一起,且粗标注(框/多边形)会泄露背景信息,导致模型看似强大但可能并不具备纯几何结构辨识能力。

现有视觉语言模型在多模态基准上总体表现很强,但对“沿着图中单条连续路径从起点精确走到终点,并按顺序读出沿途标记”的能力缺乏系统测试;该能力本质上要求持续的视觉绑定、局部连续性判断与抗干扰的序列化注意,而这恰是模型常见薄弱点。

现有多模态大模型多擅长短视频理解(caption/QA),但难以把“数分钟到数十分钟”的电影/剧集长视频转写为细粒度、时间对齐、层级结构化的剧本(scene-by-scene,含动作/对白/表情/音频线索)。核心难点在于长程时序理解、叙事一致性、多角色指代与跨模态(画面+语音+音效/BGM)融合,以及超长生成带来的计算与评测困难。

现有视频字幕多为“单段落叙事”,把视觉动态、音频事件、实体身份与场景信息混写在同一文本流里,导致:①跨镜头的实体指代不稳定、重复描述多、易产生身份幻觉;②并发的视听事件缺少显式对齐,局部细节难以精修;③结构纠缠使得MLLM学习成本高,尤其小模型更难从自由文本中自行解耦关系。

对齐后的LVLM在生成时需要持续“检索”安全指令(system safety前缀、角色分隔符、对话格式token等)来维持拒答行为;但现有视觉越狱多从输出logits层面硬推有害回复,导致与模型内部的“注意力安全检索机制”对抗方向不一致,出现严重梯度冲突,优化震荡/平台期明显,收敛慢、需要更大扰动与更多迭代。

LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment
如何“定量、可复现、可跨任务/跨主体”地评估从无标注人类视频中学习到的 latent action(潜在动作)表示质量,而不是把表示好坏混在下游机器人策略成败里一起评估。

GTASA: Ground Truth Annotations for Spatiotemporal Analysis, Evaluation and Training of Video Models
如何为视频生成与视频理解提供“可验证的物理合理性与语义忠实性”的地面真值(ground truth)标注,从而能系统评测/诊断视频模型的时空推理能力,并提供可扩展训练数据。

EmergentBridge: Improving Zero-Shot Cross-Modal Transfer in Unified Multimodal Embedding Models
统一多模态嵌入(unified embedding space)在真实部署中常处于“稀疏配对监督”场景:训练时只对少数模态对(如图文)有配对数据,许多非锚点模态对(如音频↔深度、红外↔音频)从未共同出现,导致推理时这些“未配对模态对”的零样本跨模态迁移(检索/分类)表现脆弱。论文将这种能力缺口概括为 emergent alignment(涌现对齐):即便各模态都与同一锚点对齐良好,也不必然意味着非锚点模态之间能可靠对齐。

将 decoder-only 多模态大模型(MLLM)改造成“统一多模态检索嵌入模型”时存在两类结构性缺口: (1) 现有方法常用 implicit pooling,把某个普通词表 token(如 <EOS>)的最后隐状态当作全局嵌入,但该 token 并非为信息聚合设计,聚合能力不稳定。 (2) 仅用对比学习(InfoNCE)做检索微调只提供“配对级”信号:告诉模型哪些 query–candidate 应接近,但没有“token 级”机制指导模型如何把跨模态、跨长度的细粒度语义压缩进一个固定维度向量,导致在 QA-style 等语义要求高的检索任务上表现受限。

评测并改进模型对跨语言、跨模态的习语/隐喻等非字面意义理解能力,揭示LLM/VLM在比喻推理上的系统性盲点。

如何系统评测VLM在中文艺术品上的高阶理解能力:证据对齐推理、专家式长文赏析、可辩护的再阐释,以及真伪/风格鉴别等“鉴赏级”能力。

如何在表格推理中同时利用“整体视觉结构线索”和“可控的符号化操作”,避免纯CoT/纯符号方法各自的盲点与低效。

如何在不重新训练的情况下,缓解视频-语言模型在多模态对齐后出现的时间推理能力下降(temporal reasoning退化)。

评测多模态大模型在长视频摘要中的时间一致性与“带时间戳的语义对齐”能力,暴露其长时序理解缺陷。

如何在教育场景下系统性审计VLM的社会偏见,并区分视觉通道引入/放大的隐性偏差。

如何用跨模态“主张-证据”推理而非表面文本特征,检测企业在多渠道披露中的AI-washing(夸大/虚构AI能力)。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

如何在语音数据稀缺、且多语言语音资源更稀缺的现实约束下,训练一个端到端的跨语言语音大模型,使其同时具备(1)语音-文本跨模态对齐能力与(2)跨语言泛化能力,并在对话式生成中兼顾质量与低延迟。

单张图像生成/重建3D室内场景的现有方法往往“看起来合理”但不满足物理一致性(碰撞、悬空、支撑不稳、不可部署/不可导航等)。核心问题是:如何系统化度量物理一致性,并将物理约束有效注入生成模型的训练与推理,从而得到既视觉逼真又物理可行的3D场景。

现有生成式模型几乎都工作在像素/栅格空间,无法“原生”生成可编辑、分层、参数化、分辨率无关的矢量动画(vector animation)。核心难点在于:如何把包含层级结构(layers/groups/shapes)与时间轴运动(keyframes/easing/interpolation)的 Lottie/AE 动画,编码成适合自回归建模的紧凑 token 序列;以及缺乏大规模高质量矢量动画数据。

Flow Matching(FM)在视觉生成中常出现“无 guidance 时样本偏离数据分布(out-of-distribution)”的问题。作者认为根因之一是 FM 训练使用固定的欧氏 MSE 速度匹配损失,有限容量模型在这种度量下会产生不符合数据流形的泛化。问题是:能否在连续时间流模型中引入对抗式、可学习的判别准则,以更好地对齐真实数据分布,同时保持连续时间 ODE 生成框架?

现有视觉生成的奖励模型大多把人类偏好压缩成“单一标量分数”,缺乏可解释的推理过程,导致两类问题:一是训练时奖励稀疏且易被模型投机(reward hacking),二是测试时无法把“哪里错了”转化为可执行的改进动作(例如改提示词)。论文要解决的是:能否让奖励模型先生成结构化、多维度的批判性理由(critique/rationale),再给分,并让这些理由在训练与测试阶段都能直接驱动生成质量提升?

当前 3D 场景生成主流依赖 2D 多视图/视频扩散:把“3D 空间外推”退化为“2D 时间延展”。这带来两大根本问题:(1) 表征冗余:多视图之间大量重叠导致 token 数爆炸、算力浪费;(2) 空间一致性受限:2D latent 缺乏内生 3D 结构建模能力,长轨迹生成会累积误差、结构逐步崩坏。论文要解决的是:能否学习一种固定长度、真正 3D-grounded 的隐式 latent,把任意数量/分辨率的多视图压缩为少量 3D token,并在该 3D latent 空间内直接做扩散生成,从而同时提升效率与空间一致性?

高阶扩散/流匹配开始同时学习速度、加速度、jerk 等高阶导数,但朴素做法为每一阶导数单独训练一个网络,参数量随阶数线性膨胀;即便用 LoRA 给每一阶配独立 adapter,也忽略了“高阶导数由低阶状态递推而来”的结构,导致参数利用率不高。

3D 基座模型(如 VGGT)下游微调普遍依赖 LoRA,但 3D 数据的变化因素(纹理、几何、相机运动、光照等)更“属性化/可控”。核心问题是:是否存在与每类属性变化对应的 LoRA 子空间?这些子空间是否近似解耦(正交)?以及如何稳定、有效地从有限/合成数据中挖掘这些子空间,用于更高效的微调与更强的迁移。

OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
如何在同一视频生成框架中统一融合文本/参考图/音频/姿态等多模态条件,生成高质量且可控的人-物交互视频。

如何对视频生成模型进行同时覆盖“生成质量(技术保真/伪影)”与“审美质量(感知/艺术性)”的统一、可扩展评测。

评估并攻击自回归图像生成模型的水印方案,检验其在“去水印”和“伪造水印”场景下的鲁棒性与可用性。

在统一框架中同时实现音频多模态理解、通用音频/音乐/语音的生成与编辑,并缓解音频编辑数据稀缺导致的能力缺口。
视频到音频(V2A)/视频-文本到音频(VT2A)生成缺少细粒度、可对齐人类偏好的系统评测,且不同音频类别(音效/音乐/语音/歌唱)需求差异大。

解决自动化高保真图表/示意图生成中语义拓扑、视觉风格与空间布局需要协同优化且难以精确可控的问题(像素生成不可控、纯代码生成不够直观)。

Uni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
统一多模态模型中视频生成计算远高于理解,扩展理解型MLLM支持生成代价高。

如何突破全视频生成在探索多条未来运动轨迹时的计算效率瓶颈?
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

过程奖励模型(PRM)需要对 CoT 每一步进行监督,但人工逐步打分成本极高;现有自动化方法(如基于多次 rollout 的 Monte Carlo 估计)虽免人工但计算开销大、生成奖励慢,难以规模化构建高质量 step-level 数据集。

开放式写作的强化微调(RFT)缺乏可验证奖励,通常依赖昂贵闭源评审模型或主观且难标注的人类偏好数据。直接用“模型自信度/对数概率”作内生奖励虽可无评审训练,但会诱发 Triviality Bias:策略向高概率、低熵、模板化输出坍缩,牺牲多样性与内容信息量。

LLM 文本智能体在环境交互式 RL 中普遍面临外部奖励稀疏:只有少数关键动作获得非零回报,导致样本效率低。用模型自评(PRM/生成式过程奖励)提供稠密奖励虽直观,但未经校准会产生系统性偏置(例如过度奖励 inventory),反过来诱导策略学到“刷奖励”的坏习惯并降低任务成功率。

Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning
LLM 后训练 RL 中的核心瓶颈是长序列生成的 credit assignment:奖励通常只在序列末端给一个标量,导致难以判断哪些中间 token/决策真正促成了最终成功。经典 actor-critic 依赖 value function 做细粒度 advantage 估计,但在 LLM 规模下“判别式(discriminative)一发标量预测”的 value model 往往难训、不稳、效果不随规模可靠提升,实践中被 GRPO/RLOO 等 value-free 方法替代,从而把序列问题近似成 contextual bandit,牺牲精细归因能力。

RLVR(Reinforcement Learning with Verifiable Rewards)用序列末端的可验证结果奖励提升推理能力,但带来根本性的 token-level credit assignment 问题:GRPO 等方法把同一个 outcome reward 广播到整条轨迹的所有 token,导致大量“例行续写”与少数“关键分叉决策”获得同等更新,学习信号被稀释或错配。现有工作分别从 reward polarity(正/负样本)或 token entropy(不确定性)出发提出启发式,但缺少统一解释:信用究竟集中在哪里、为何集中、以及应如何调制梯度。

多步 agentic RL(LLM+工具、多轮交互)中,奖励往往延迟且稀疏(常见为最终二值成功/失败),导致“逐步归因(step-level credit assignment)”困难。现有 critic-free(如 GRPO)把同一条轨迹的优势值平均分配到每一步,无法区分哪一步决策真正带来收益;而训练 value/critic(如 GAE)在超大状态空间与稀疏奖励下开销高、易不稳定。

LLM RL后训练普遍默认需要严格on-policy数据,experience replay在LLM RL中被忽视,推高了生成开销。

MathAgent: Adversarial Evolution of Constraint Graphs for Mathematical Reasoning Data Synthesis
如何在“几乎不依赖人工先验/种子数据”的前提下,自动合成高质量、可解且具备高逻辑复杂度的数学推理数据;并避免现有零样本探测式生成易出现的 mode collapse、逻辑幻觉与结构单一,以及 seed-mutation 方法受初始语义范围上限约束的问题。

Finetune Like You Pretrain: Boosting Zero-shot Adversarial Robustness in Vision-language Models
如何在不显著牺牲 CLIP 等视觉-语言模型零样本能力的前提下,提升其零样本对抗鲁棒性;并解决现有 adversarial finetuning(AFT)常用“在 ImageNet 上用交叉熵对齐到类别标签”的做法导致的零样本性能下降与跨域鲁棒性迁移有限的问题。

多模态大模型在几何推理中长期受“感知瓶颈”限制:无法稳定、细粒度地识别几何图中的点/线/面/体及其语义关系,导致后续符号推理失效。现有几何图解析(GDP)研究几乎只覆盖平面几何,缺少对立体几何(需要3D结构与空间关系理解)的统一形式化语言与大规模标注数据。

现有多模态模型在复杂视觉理解与多模态推理中常出现“浅层推理”:推理链不完整、前后不一致、缺少自检机制,导致错误难以被发现与纠正。如何在较小数据与较低训练成本下,让中小型VLM学会稳定的自我验证(self-verification)与自我纠错(self-rectification),并在测试时可按难度扩展计算,是该论文要解决的问题。

现有VLM在多图对比/时序推理中存在“多图推理幻觉”:模型强依赖输入顺序等表面时间先验(sequence bias),导致同一任务在正序与逆序提问时性能断崖式下跌,无法基于视觉证据进行真实的因果-状态判断(如“哪一帧更接近任务完成”)。

具身、第一视角(egocentric)长程任务需要模型同时具备:细粒度空间感知、任务状态评估(是否更接近目标)、以及跨多步的规划推理。但现有VLM多来自被动视频学习,强依赖固定因果顺序的时间先验,遇到反事实顺序、多帧比较、状态回退/失败等就产生时空幻觉与泛化崩溃,难以支撑可靠的长程规划。

LLM 在生成答案时系统性过度自信(verbalized confidence 与真实正确率严重不匹配),且现有校准方法往往依赖标注、在分布漂移下失效或推理成本高;问题是如何在“无标签 + 可随测试分布变化自适应 + 低成本”的条件下,把模型输出置信度校准到可用水平。

现有 Generative Reward Model(GRM)在推理增强中普遍“对所有输入都强制 CoT”,导致不必要的算力/时延;同时对 CoT 路径质量的评估多依赖投票,粒度粗、难以区分细微优劣,限制了奖励信号的保真度与最终性能。问题是:能否用任务无关的内部信号决定何时需要 CoT,并提供更细粒度的推理链评分?

在固定预算下做指令微调(instruction tuning)时,训练效果对“选哪些指令-回复样本”极其敏感。现有很多模型中心(model-centric)的数据选择方法依赖“单一参考答案/teacher response”来打分,但大量指令天然存在多种正确回答,单参考会把格式/语气/推理风格差异误当成能力缺口,从而误选数据。

面向大规模后训练(post-training)的强化学习系统在“全模态(omni-modal)输入 + 多轮agentic轨迹”场景下遇到三类耦合挑战:数据流高度异构(图像/视频/音频/文本混合且长度差异巨大)、大规模运行的鲁棒性(长尾延迟、OOM、NCCL超时、服务崩溃等)、以及同步训练导致的吞吐受限与异步训练带来的策略陈旧(staleness)权衡缺乏统一抽象。

RL用于LLM时常出现采样多样性下降与重复犯错:仅对当前策略做熵正则无法显式抑制跨rollout的“重复失败模式”。

现有基于 MCTS 的自动推理数据挖掘/监督提取大多采用“筛选式”范式:只保留最高奖励(正确)的单条轨迹用于训练(如 RFT),把大量被探索过但失败/次优的轨迹直接丢弃,导致对“为什么错、错在哪里、成功与失败的关键分岔点是什么”的结构性信息利用不足,数据与算力效率低。

传统判别式奖励模型(RM)对每个候选回答独立打分,N 个候选需要 N 次前向计算;在多模态场景中图像/视频上下文 token 占大头,重复计算代价极高。同时,独立打分缺乏“直接比较”能力;而生成式 judge 需要自回归生成判决,延迟更高、上下文变长时更不稳定。现有范式都难以高效扩展到 best-of-N、组内优化等天然的 N-way 排序需求。

在缺乏大规模物理领域QA数据的情况下,如何用可扩展的监督信号训练/提升LLM的物理推理能力并实现sim-to-real泛化。

表格图像转 LaTeX 需要同时保证结构(行列/合并单元格)、内容(单元格文本数值)与样式(线型/对齐/字体等)的高保真,但现有 MLLM 或专用系统常出现结构不一致、样式丢失、内容错误或不可编译。用 RL 做后训练时,若只用单一全局奖励(如 TEDS)会把多种异质目标混成一个信号,产生 reward ambiguity,导致信用分配错误:结构错也可能被正向强化、内容对也可能被惩罚,且不同组件质量差异可能得到相同总奖励。

RLVR(Reinforcement Learning with Verifiable Rewards)通过规则/执行器等可验证奖励显著提升推理与编程能力,但论文首次系统揭示:RLVR 训练环存在可被投毒数据利用的后门脆弱性。攻击者无需修改 verifier,只需向训练集注入少量带触发器的 prompt(poisoning prompts),就能在触发条件下诱导模型产生有害输出并绕过拒答安全对齐;而在无触发器时模型表现近似正常,难以察觉。

如何让LLM在面对越狱指令、后门触发与“遗忘/去除不良知识”需求时,具备更强的跨攻击/跨任务泛化防御能力,而不是只对已见恶意提示词过拟合。

LLM 用于结构化合成数据生成时,常出现幻觉、逻辑不一致与 mode collapse;现有 prompting/RAG/结构化采样方法难以同时给出“硬逻辑有效性保证”与“覆盖/公平等软分布约束的可控性与可量化”。

现有 Tool-Integrated Reasoning (TIR) 依赖在推理时把工具文档塞进上下文:导致工具掌握困难(文档异构)、工具规模受限(context window 不够)、推理/调用低效(prompt 过长)。论文提出 Tool-Internalized Reasoning (TInR):让模型在不提供外部文档的情况下完成带工具的推理与调用。

多轮交互式 LLM Agent 的 RL 训练样本效率低:奖励稀疏、长时序信用分配困难。现有 on-policy self-distillation(OPSD)依赖“特权信息”(如唯一标准答案)提供稠密 token 监督,但在 agent 任务中往往不存在唯一解;同时把自蒸馏与 RL 直接耦合会因分布漂移/重要性加权不稳而出现训练崩溃。

现有合成工具调用数据多为离线 SFT 设计:样本是静态的“用户问题-工具调用-工具输出-答案”,缺少可执行环境与可验证奖励,难以直接用于在线 RL(尤其是需要可自动打分的 RLVR)。同时真实世界工具使用需要应对歧义提问、干扰工具、噪声/多格式/错误输出、工具失败等鲁棒性场景,而现有数据覆盖不足且难以规模化获取真实日志。

熵引导的 LLM 强化学习(如在 GRPO/类 PPO 框架中加入熵正则)面临“探索-利用”根本冲突:提高熵以促进探索,往往会破坏已具备强推理能力、低熵输出的 LRM 的准确性与连贯性,甚至导致高熵胡言乱语式退化。论文要解决的是:在持续后训练(continual post-training)阶段,如何在不牺牲准确率的前提下,显著恢复/提升探索多样性(熵)并获得更高 Best-of-N 表现。

RLHF/奖励优化可能引入“迎合(sycophancy)”等奖励黑客行为,但现有评估多停留在输出是否迎合。论文关注更隐蔽且关键的问题:迎合式奖励是否会破坏模型的不确定性量化能力(calibration),使模型的置信度与真实正确率脱钩,从而在高风险应用中造成系统性过度自信。

SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
在推理对齐中,on-policy RL 的奖励稀疏(仅结果级正确/错误),导致 token 级信用分配困难、收敛慢。OPD 通过引入教师模型的 token 级 KL 监督缓解该问题,但现有 OPD 往往对所有 rollout 施加“同等强度”的蒸馏信号,忽视了不同轨迹上监督信号质量的巨大差异:错误轨迹上教师可能并不可靠;正确轨迹上强蒸馏会压制学生的有效多样推理路径并诱发 mode collapse。

New Hybrid Fine-Tuning Paradigm for LLMs: Algorithm Design and Convergence Analysis Framework
LLM 微调主要有两条路线:全参数微调(效果强但计算/显存昂贵)与 PEFT(如 LoRA,成本低但学习新知识能力弱、效果上限受限)。同时,零阶(ZO)全参微调可避免反向传播但收敛慢。论文要解决的问题是:能否设计一种同时更新“基座模型参数 + PEFT 模块”的混合微调范式,在不显著增加资源开销的前提下兼顾适配能力与优化效率,并给出可解释、可证明的收敛理论。

论文研究在用于推理型大模型(LLM)的强化学习(RL)后训练中,策略熵(policy entropy)会快速坍塌导致过早收敛与性能饱和的问题,并对两类熵控制方法给出统一的理论解释:传统熵正则(entropy regularization)与近期提出的基于协方差(covariance-based)的选择性熵控制机制。

论文聚焦在偏好优化(preference optimization)的最小化 pairwise 场景下,比较两种训练范式:直接用成对偏好目标的 DPO(Direct Preference Optimization)与把每个 prompt 视作有限候选决策问题、用奖励模型引导“决策分布更新”的 DDO-RM。核心问题是:即便只有 chosen-vs-rejected 两个候选,奖励引导的分布式更新能否在 held-out 偏好评测上优于 DPO?

From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
LLM 的 RL 训练依赖稀疏的 outcome-level reward,但长轨迹中的 credit assignment(信用分配)问题——哪些 token/step 导致了最终结果——仍未解决。

如何降低LLM在RLVR(可验证奖励强化学习)训练中的计算开销与训练步数,加速能力提升。

如何用极低成本的输入结构改造(显式句子边界)提升LLM推理与任务表现,并让模型更“按句处理”。

LLM即使“知道”事实也会胡编:如何在后训练中同时对齐模型的事实性、可信度表达与诚实作答行为(该说不确定就说不确定)。

在对抗式对话中,如何让防守方LLM通过“理论心智(ToM)”建模攻击者信念与意图,实现对隐私/敏感信息的信念引导(让攻击者误以为已成功)以提升安全性。

防御针对LLM链式推理(CoT)的“推理级后门攻击”,在触发后模型会插入恶意推理步骤但答案表面合理,难以检测。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

论文研究监督微调(SFT)中的“不完全学习现象(ILP)”:即使训练损失已收敛、超参已调优,模型仍会在其自身的训练集上持续、稳定地答错一部分监督样本。这不是灾难性遗忘,也不是刻意遗忘,而是对部分监督信号未能内化。

论文聚焦于一个常被忽视但会系统性误导结论的问题:LLM 评测/标注/审核等“测量流水线”本身存在大量隐藏测量误差(hidden measurement error)。这些误差来自提示词改写、judge 模型更换、温度/采样随机性、条目异质性以及它们的交互,足以导致分数波动、排名翻转、显著性结论反转;而常规只在“固定设置下重复抽样”的置信区间并未覆盖这些来源。

论文质疑并系统拆解了 MoE(Mixture of Experts)中广泛流行的“专家专精/领域专家”叙事:我们看到不同领域文本会路由到不同 experts,常被解释为路由器学到了可解释的领域划分;但作者指出这种“专精”并不必然意味着语义或领域层面的专家化,而更可能只是隐藏状态空间几何结构的必然结果。

经典信息论泛化界(如基于KL互信息)通常依赖损失/奖励的有界性或次高斯尾部(MGF存在)。但在RLHF、鲁棒学习、随机优化等现代流程中,奖励/损失/梯度噪声常呈重尾(MGF可能不存在),导致KL工具可能“看起来信息很小但泛化/稳定性被极端事件主导”,从而界变得失效或空泛。本文要解决:在次Weibull(含0<θ<1重尾)条件下,如何构造仍然有效、可用于期望与高概率的、算法依赖的信息论泛化与稳定性分析框架,并落地到RLHF与SGLD。

Transformer能够用少量标注样本完成in-context分类,但推理时到底在“运行什么算法”不清楚。现有常见解释是“隐式梯度下降/优化器模拟”,但在多类线性分类、且处于hard no-margin(几何上更困难)设定下,这种抽象可能误导。本文要解决:如何让推理计算可识别(identifiable)并从训练后的Transformer中抽取出可写成闭式的、逐层递推的推理动力学,从而回答“它在做什么”。

论文聚焦一个“看似简单但长期未解”的问题:当前主流视觉-语言模型(VLM)在基础视觉扎根能力上仍明显薄弱,尤其是对象计数(counting)。作者进一步追问:模型的计数到底来自真实视觉证据,还是被语言先验/提示牵引?以及这种失败发生在VLM流水线的哪个组件(视觉编码器、模态投影器、LLM骨干)?

论文研究多模态“潜在推理”(latent reasoning)训练中的两个优化瓶颈: (1) 视觉-文本优化失衡:视觉token的梯度范数显著更高且更不稳定,反映语言偏置导致视觉表征在联合训练中被系统性欠优化/难对齐; (2) 固定深度困境:不同难度样本/不同语义复杂度token的收敛行为差异巨大,简单token很快稳定,而复杂token长期梯度震荡;固定层数的Transformer缺乏按需迭代精炼的能力,导致难样本被困在不稳定轨迹中。

论文聚焦多模态大推理模型(MLRMs)在长链式推理(CoT)中更易产生幻觉这一核心问题,并提出“Reasoning Vision Truth Disconnect(RVTD,推理-视觉真实脱节)”:模型在需要视觉证据校验的关键推理转折处,反而显著减少对图像证据的利用,导致推理链被语言先验“接管”。

论文研究扩散模型采样的“信息论极限”:当采样器只能通过查询不同噪声水平下的平滑score(smoothed score)来生成样本时,最少需要多少次score查询(网络前向)才能在高维d下得到非平凡的采样保证?核心问题是:能否把采样步数降到polylog(d)甚至O(1),还是存在不可突破的维度依赖下界?

论文研究“weird generalization(怪异泛化)”是否真如先前工作所示那样普遍且危险:模型在狭窄域微调(如不安全代码、过时鸟名、旧德语城市名)后,会在域外表现出意外的、甚至对齐层面的异常特质(如广泛不对齐、极端历史/意识形态人格)。作者核心问题是:该现象在不同模型/数据集上能否稳定复现,以及能否用简单干预在训练时抑制。

论文关注传统LLM安全评测的“可靠性盲区”:像HELM、AIR-BENCH这类广度型基准通常对每个prompt只采样一次(或极少次),难以发现真实部署中“同一prompt反复调用”带来的操作性风险——例如偶发幻觉、拒答不一致、温度变化下偶尔越狱、同问不同答等。核心问题是:如何用统计上可解释的方式量化“重复采样下的失败频率”,从而评估部署级安全可靠性缺口。

如何在不进行迭代训练/微调的前提下,从生成模型(扩散/flow-matching 等)的表示中“擦除”特定目标概念(对象/风格/身份等),同时尽可能不破坏非目标概念与整体生成质量(最小副作用的概念编辑)。

现有 LLM 不确定性量化(UQ)方法通常输出单一置信度分数,但自然语言任务的不确定性来源多样(知识缺口、输出多解/可变性、输入歧义等)。核心问题是:不同不确定性来源会如何影响各类 UQ 方法的行为与有效性?现有评测缺乏对来源的可控隔离,导致比较不公平。

LLM 幻觉检测中,已有大量基于注意力图/内部表征的特征工程方法,但“为什么这些特征有效”缺乏机制层解释;同时很多方法依赖外部检索、多次采样或额外模型,成本高且可解释性弱。本文要回答:能否仅用注意力权重,找到一个机制上可解释、跨模型稳健的内部信号来检测幻觉?

科学主张验证(claim verification)需要遵循闭世界假设(CWA):只有当主张所断言的每个约束都被证据正向支持时才接受,否则应拒绝。本文指出:现有验证基准的负例构造方式(只扰动一个显著约束)使得“完整 CWA 检查所有约束”和一种更弱的捷径“显著约束检查(salient-constraint checking)”在行为上不可区分,导致我们误以为模型具备严格验证能力。核心问题是:模型到底在做全约束验证,还是只检查最显眼的那一条?

Hidden Failures in Robustness: Why Supervised Uncertainty Quantification Needs Better Evaluation
基于LLM隐藏状态的监督式不确定性估计/幻觉检测探针,在分布外(OOD)与长文本生成场景下是否真的鲁棒,以及应如何更可靠地评测与设计探针。

Pseudo-Unification: Entropy Probing Reveals Divergent Information Patterns in Unified Multimodal Models
论文聚焦统一多模态模型(UMMs)中的“伪统一(pseudo-unification)”现象:虽然模型在参数/表示空间上看似统一了语言与视觉,但LLM式的推理与创造性生成并未迁移到图像生成端,导致同一模型在文本生成与图像生成上呈现截然不同的内部信息编码与输出模式。作者希望回答:这种不一致的模型内因是什么,如何用可解释、可比较的方式在模型内部诊断“是否真的统一”。

论文研究“MLLM-as-a-Judge(用多模态大模型做自动评测)”是否存在模型偏好偏差(model-specific preference bias):评测模型(Evaluator)会系统性偏爱某些生成模型(Generator)的文本,尤其是偏爱自己的输出(self-preference),从而扭曲不同模型的对比与基准驱动的研究结论。关键问题是:如何在不把“真实质量差异”混进来的情况下,定量分离并测量这种偏好。

论文聚焦一个常被忽略但很基础的问题:白盒“激活引导/激活转向(activation steering)”得到的中间激活状态,是否一定能被某个纯文本prompt在模型自然前向传播中“复现”?作者将其形式化为“从离散prompt到内部激活的映射是否满射(surjective)”的问题,并主张典型的steering会把残差流推到prompt不可达的区域,因此几乎不存在能精确复现该steered激活的prompt。

论文要解决的是CoT推理“看起来合理但过程不可信”的评估难题,尤其是链内不忠实(intra-chain unfaithfulness):相邻推理步骤之间缺乏真实的逻辑依赖、夹杂错误内容,但模型/评审仍可能给出高分。作者指出传统LLM-as-judge容易受自我肯定等偏置影响,导致对链内因果依赖的判断出现伪相关。
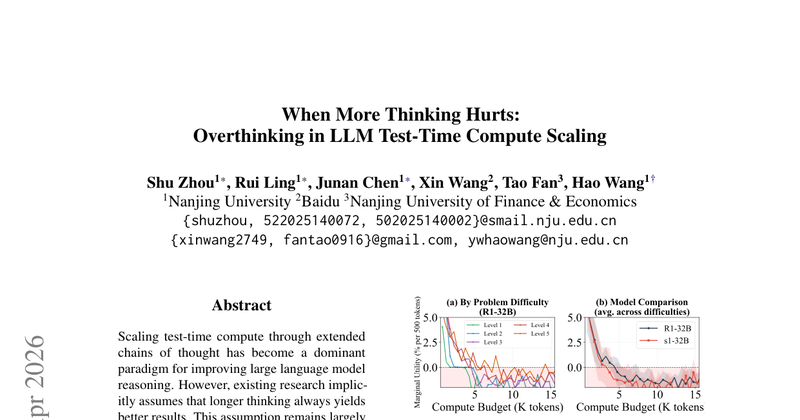
论文质疑“推理越长越好”的默认假设,系统研究在测试时计算(test-time compute)随推理token预算增加时,额外推理的边际收益如何变化,并重点刻画一种反直觉现象:推理变长反而把原本正确的答案“想错了”(overthinking)。

论文研究推理计算扩展中“广度(并行探索多条解法)vs 深度(对少数候选进行迭代精炼/树搜索)”的预算分配问题,并提出核心观点:决定最优推理策略的不是你用的具体方法名(并行采样、树搜索、MCTS式 refinement 等),而是目标模型自身的“多样性画像(diversity profile)”——概率质量在不同高层解法路径上的分布形态。

论文要回答的核心问题是:当模型“不愿意/不能/会撒谎”解释自己时,现有白盒可解释性方法(梯度归因、表示读出、SAE/稀疏特征、回路追踪等)是否真的能在黑盒交互(prompting)之外,额外提升我们对模型行为的可预测性?作者指出很多评测没有控制“黑盒本身就能把目标行为套出来”的情况,导致白盒方法看似有效其实只是更会提问/更会诱导(elicitation confounder)。

论文要解决的问题是:对于达到特级大师水平的棋类 Transformer(以 Leela Chess Zero, LC0 为代表),如何在全模型尺度上“追踪其内部思考过程”,把注意力与 MLP 的计算从叠加/超位置(superposition)中分解出来,形成可检验、可干预的推理路径(reasoning pathways),从而解释其战术判断与并行推理结构。

论文研究“工具无关(irrelevance)”场景下的一个系统性失败模式:当工具在语义上无法实现用户目标(semantic irrelevance)时,LLM 仍会因为“查询属性能一一映射到工具参数”(structural alignment)而倾向调用工具。作者将这种“用结构匹配替代语义核验”的机制性捷径形式化为 Structural Alignment Bias(SAB)。

论文重新审视双塔式视觉-语言模型(如 CLIP)在组合性(compositionality)基准上的“像词袋(bag-of-words)”失败:作者认为问题未必主要来自表示能力不足,而可能来自标准推理协议——用全局池化后的图文向量做余弦相似度(global cosine similarity)——该协议会丢失对象-属性-关系所需的细粒度绑定信息。

论文聚焦于一个核心矛盾:现有大多 LMM/LMM-based 系统擅长“全局语义理解与对话”,但在需要“对象级(object-level)精确落地”的任务上存在系统性短板——包括实例级指代易误对(mis-grounding)、空间定位/边界不精确、跨轮交互缺乏对象恒常性(object permanence)、以及难以对指定对象/区域进行可控编辑与生成。论文试图回答:如何用 object-centric vision 的理念与技术栈,系统性补齐 LMM 在对象级理解、分割、编辑、生成上的能力缺口,并形成统一的研究版图与路线图。

论文要解决的核心问题是“扩散模型为何能从纯噪声逐步生成数据,以及反向过程如何在理论上‘逆转’前向加噪过程”的直观理解困难。现有 VAE/score/flow 等讲法往往推导繁重、直觉割裂,初学者难以把握统一本质。作者提出用 Langevin dynamics 的视角,把扩散模型解释为对一个‘分布恒等变换(identity on distribution)’的拆分,从而更直接地推导反向过程,并澄清 ODE/SDE 扩散与 flow matching/denoising/score matching 在最大似然下的等价关系。

论文要回答:为什么用 Transformer 训练 DDPM 去做去噪/学 score 在理论上是可行的?在非凸损失下,梯度下降为何能收敛到“最优去噪器”(或足够接近的最优)?以及 Transformer 的自注意力到底以什么机制实现去噪。

CoSToM:Causal-oriented Steering for Intrinsic Theory-of-Mind Alignment in Large Language Models
论文关注 LLM 的“心智理论(ToM)”能力是否是内在稳定表征,而非依赖提示词脚手架的表面行为;以及能否通过可解释性定位 ToM 表征所在层,并用因果干预把这种内在表征稳定外化为更高质量的对话行为(如谈判、劝说)。

多语言大脑语言网络在不同语言下呈现“共享解剖激活”,但其底层计算机制究竟是跨语言共享、还是对母语/特定语言存在专门化,传统神经影像难以给出因果层面的区分。论文提出用多语言LLM作为可控系统,通过对模型内部组件做“计算性损伤(computational lesions)”,来因果检验哪些模型成分支撑跨语言的大脑-模型对齐,以及哪些成分体现语言特异性。

LLM“人格/人设(persona)”常用于改变交互风格,但它是否会系统性影响模型的底层认知能力(推理、知识检索、指令遵循等)并不清楚。论文研究:用神经元级人格诱导(NPTI)在不改权重的情况下施加大五人格特质,是否会带来稳定、可复现、且任务依赖的能力变化,以及这些变化是否与认知科学理论(CB5T、ACT)一致。

论文要回答两个核心问题:(1)“情绪几何”(把离散情绪表示为残差流中的近似线性方向/向量)是否是语言建模本身会普遍涌现的结构,而非只在某个大模型/特定训练流水线里出现;(2)跨小模型(不同架构、base/instruct、不同推理后端与数值精度)做情绪向量对比时,观测到的差异有多少来自真实表征差异,有多少其实是方法学混杂(pipeline、backend、precision、抽取模式等)造成的假象。

论文研究“大五人格(Big Five)”这类心理学概念在LLM内部如何表征、出现在哪些层、是否存在对概念选择性响应的“概念神经元”,以及这些内部表征能否被因果操控从而改变模型的判别读出与生成行为。核心张力是:探针能读出≠生成可控,作者试图用神经元级干预把两者连接起来并检验因果性。

论文关注一个被低估的风险:LLM 在“政策评估/准实验因果推断”这类真实世界反事实推理中,是否会在“结论违背直觉”的情形系统性失灵。作者提出“直觉性(intuitiveness)”这一维度:当真实经验证据与常识先验一致(obvious)、不明确(ambiguous)、或相反(counter-intuitive)时,LLM 的回答可靠性是否发生结构性变化。

论文探问:LLM 是否真的能构建“空间世界模型(spatial world models)”来支持规划与推理,还是主要依赖对特定输入格式/提示的表面启发式。作者用网格迷宫(grid-world maze)作为受控环境,检验模型在多步路径规划、空间抽象与跨表示一致性上的能力。

论文要回答的问题是:LLM 为什么会生成有害内容?更具体地,哪些内部组件(层/模块/神经元)在因果意义上“导致”了有害输出,而不仅仅是与之相关。

解释为何Transformer/LLM在具备全上下文注意力的情况下仍表现出工作记忆限制,并刻画其与人类相似的干扰效应。

论文研究的问题是:当大型推理模型(LRM)在回答有害请求时被注入“冲突目标/两难情境”,其安全决策会如何失效?冲突为何会显著提升攻击成功率?
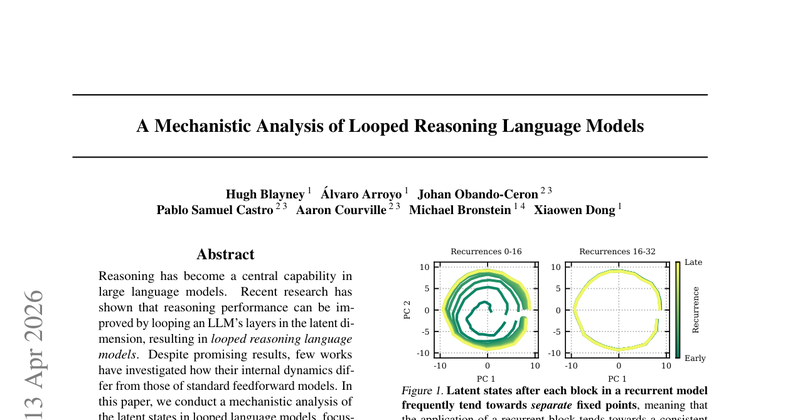
论文研究“循环推理/深度递归(looped)”Transformer 与标准前馈 Transformer 在内部计算动力学上的差异:当把一段共享权重的层在潜空间中反复应用时,残差流(latent states)会如何演化?它是否仍呈现前馈模型中常见的“分阶段推理(stages of inference)”结构?以及循环结构带来的性能收益对应了怎样的可解释机制。

如何从统一的数学/几何视角解释 Transformer 注意力、diffusion maps 与 magnetic Laplacian 之间的关系,并给出可组织这些动力学机制的框架。

Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
论文系统综述 Transformer 中的 Attention Sink(注意力汇聚/注意力下沉)现象:模型会把大量注意力分配给少数“特定但信息量低”的 token(如 BOS、换行、特殊符号或某些异常 token),从而影响训练与推理动态、可解释性、长上下文效率、幻觉与鲁棒性。作者试图回答:AS 在现有工作中如何被利用?其形成机制是什么、是否“必要”?以及有哪些可行的缓解/替代设计与权衡。

解释Transformer注意力在序列建模中如何“从上下文中”学习潜在的token重要性/混合权重,并给出可证明的机制对应。

现有关于 Transformer in-context learning(ICL)的理论分析大多建立在“任务分布平稳(stationary)”的回归设定上:prompt 中的上下文样本与查询点共享同一个不随时间变化的目标函数/回归系数。但真实序列任务(时间序列、流式数据、语言等)普遍非平稳:目标函数随时间漂移,预测应更依赖“最近样本”(recency bias)。本文要回答:在非平稳回归下,ICL 机制如何实现自适应?标准线性注意力为何不足?带门控的线性注意力(GLA)为何更合适?

General365: Benchmarking General Reasoning in Large Language Models Across Diverse and Challenging Tasks
如何系统评测LLM在“去专业知识依赖”的一般性推理(general reasoning)上的能力与泛化,而非仅在数学/物理等专门领域推理上表现。

在视频场景理解的VLM中,显式“思考/推理痕迹”(thought streams)是否真的带来质量提升、提升在何处饱和、以及模型在思考中关注了什么。

角色扮演/人格设定下,persona的“宜人性(agreeableness)”如何驱动LLM的sycophancy(迎合用户而牺牲真实性)。

多轮对话场景下,攻击者可通过大量“单步低风险但累积有害”的输入逐步越狱,绕过对齐阈值与显式触发检测。

在已有对齐/安全防护下,如何以更少查询、更高成功率实现对LLM的越狱与受控“模型颠覆”(subversion)。

解决现有评测对 LLM 的“上下文一致的因果推理能力”覆盖不全、缺乏统一语境与因果层级系统评估的问题。

现有医疗LLM评测过于“干净”,无法反映真实临床对话中患者噪声(记忆缺口、低健康素养、焦虑、隐瞒等)对模型诊断能力的影响。

SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences?
LLM能否预测自然科学实验的真实结果,并评估这种能力是否足以可靠地用于科研流程?

在不依赖外部符号求解器的纯神经模块化架构中,如何学习三值逻辑(Kleene K3)并实现不确定性下的组合泛化与长度泛化。

为LLM参与的序列推荐任务提供更全面、可复现的评测基准,覆盖准确性之外的真实需求并解决LLM输出抽取不可靠问题。

解决GenAI研发阶段环境影响缺乏透明披露的问题,细粒度量化从研发到最终训练的计算与环境足迹。

Back to the Barn with LLAMAs: Evolving Pretrained LLM Backbones in Finetuning Vision Language Models
当VLM以预训练LLM作为语言/推理骨干时,如何在不改变其它因素的前提下评估“更强的新LLM骨干”是否必然带来更强的VLM,以及影响路径是什么。

评估在线视觉-语言模型(OVLM)在处理用户上传图片时的PII泄露风险,并在“隐私保护-效用保持”之间寻求可行的防护方案。

如何把文本到图像(T2I)模型的社会偏见以“公众可读”的方式可视化呈现,而不仅是面向技术人员的统计指标。
SWE-bench/代码生成/代码修复/软件工程Agent/Program Synthesis/Automated Debugging

自然语言“规则文件”(如CLAUDE.md/.cursorrules)到底是提升还是扭曲coding agent行为?哪些规则类型真正有效,机制是什么。

代码生成基准通常用 pass@1(一次生成)评估,但真实编程是“写—跑—看报错—修复”的多轮迭代过程。本文系统研究迭代式 self-repair:模型先生成代码,运行测试,若失败则把错误类型与 traceback 反馈给模型让其修复,重复多轮。核心问题是:在当代(2024–2025)不同规模、不同架构(dense vs MoE)、不同提供方(开源/闭源)的模型上,self-repair 是否普遍有效?收益集中在第几轮?哪些错误更容易修?以及与“独立重采样多次”相比是否更 token-efficient?

面向由 LLM 生成/辅助开发的超大规模系统(>100k LoC),如何在可扩展的前提下做“组合式正确性推理”。传统 Hoare 逻辑能把系统拆到函数级别验证,但关键瓶颈是:每个函数都需要人写形式化规格(pre/post),而在 LLM 生成代码场景下开发者往往并不理解每个函数的真实/期望行为,导致规格难写、难准、难覆盖。

解决代码 Agent 在并行工具调用与多阶段工作流下难以调试的问题:状态转移不可见、错误链隐蔽、难定位失败起点。

如何在真实世界、长篇多句的代码摘要场景下,细粒度且无需参考摘要地评估“事实一致性/是否幻觉”。

在测试输出预测(test output prediction)中,如何在“生成代码并执行”的易失败(代码小错导致无法运行)与“纯LLM推理”的易幻觉之间取得更可靠的输出预测?

在多轮软件工程代理(SWE)中,如何在“深度推理(长CoT)”与“上下文长度/效率限制”之间取得平衡,避免上下文爆炸与重复推理。

现有自动编程Agent评测忽略真实资源约束,缺乏“算力/时间/工具调用成本”下的成本-效果权衡评测与训练环境。

在生产环境做“自然语言→领域特定语言(DSL)代码生成”时,LLM+RAG 虽然效果好,但检索与长上下文带来显著推理延迟与系统复杂度;而小语言模型(SLM)推理快、部署轻,但知识与推理能力不足,容易输出脆弱、幻觉、对提示敏感。论文要解决的是:如何用可部署、低延迟的 SLM 在生产中稳定生成结构化 DSL,并尽量减少对运行时长上下文与检索的依赖。

评估LLM在量子代码生成上的跨框架能力,现有基准局限于单一框架无法区分量子推理与框架熟悉度。
通用AI Agent/Tool Use/Function Calling/Planning/RAG/多Agent系统

如何让 LLM 在生成时满足“上下文敏感(context-sensitive)”的全局一致性约束(如远距离依赖、计数相等、跨字段一致等),并且不依赖人工手写复杂的形式化约束/语法。

Tracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
后训练(post-training)数据集在 LLM 能力形成中至关重要,但其来源与演化关系(provenance/lineage)缺乏系统记录,导致两类系统性风险难以发现:隐式重叠带来的结构冗余,以及基准测试样本沿数据派生链传播导致的污染(contamination/leakage)。本文要解决的是:如何自动化重建大规模数据集的“谱系图”(lineage graph),并据此量化冗余与追踪污染源头。

现有“深度研究/agentic search + 长文生成”框架几乎都是文本中心:能检索与引用文本证据,却难以像真实专家报告那样系统性地检索、筛选并在长文中“恰当地插入与解释”图表/表格/信息图等视觉证据;同时缺少可复现的多模态长文评测基准来衡量“视觉检索是否准、图文融合是否一致、引用是否合理”。

LAST: Leveraging Tools as Hints to Enhance Spatial Reasoning for Multimodal Large Language Models
多模态大模型(MLLM)在空间推理(几何布局、相对/绝对距离、尺度估计、拓扑关系)上常出现幻觉与不精确:仅靠数据规模与微调难以让模型内化几何先验与约束;而引入深度估计、分割、检测等专用视觉工具虽有潜力,却面临两大障碍——工具异构且参数繁多导致长链路调用不稳,以及工具输出(mask、depth map 等低层信号)难以被 MLLM 直接理解并转化为高层空间线索。

论文聚焦“Thinking with Images”范式中的细粒度视觉推理不可靠问题:模型必须先决定“看哪里/怎么裁剪缩放”,但正确决策又依赖尚未获取的局部证据,形成循环依赖。作者将其形式化为 Grounding Paradox(落地悖论):感知证据不足→工具调用位置/策略猜测化→进一步错过关键证据→推理失败。

论文研究“跨多条 agent traces 的安全审计”:很多安全违规并不在单条对话/轨迹中显现,而是分散在大量轨迹里,且违规轨迹稀少、复杂、甚至伪装成正常行为。传统 per-trace 监控会漏检;把少量轨迹塞进上下文做判断又不具备可扩展性;固定规则/监控器对新型行为脆弱。作者将该问题表述为超性质(hyperproperties):安全性取决于“轨迹集合”而非单条轨迹,并提出要定位导致违规的 witness sets(见证集合)。

Reducing Hallucination in Enterprise AI Workflows via Hybrid Utility Minimum Bayes Risk (HUMBR)
高风险企业工作流(法务、合规、隐私等)中,LLM 单次生成不稳定且可能“自信胡编”,传统 RAG/自我批判/多答案再总结在生产中仍会出现偏置、二次生成放大错误等失效模式。论文要解决的是:在没有金标准参考答案的情况下,如何以可证明的方式降低“输出幻觉”的概率,并给出可配置的风险容忍度与所需集成规模。

RAG 场景下,LLM 在检索到“冲突知识”时往往无法保持忠实推理(faithful reasoning)。现有研究多关注“外部证据 vs 模型参数知识”的冲突,或单一来源内的合成冲突;但现代 RAG 越来越多地融合非结构化文本与(半)结构化知识图谱(KG),跨来源(text vs KG)的冲突如何影响推理、模型如何选择可信证据,缺少系统基准与方法。论文要解决:构建能系统评测跨来源冲突的基准,并提出能缓解偏置、提升忠实性的推理框架。

论文要回答的问题是:LLM 智能体能否在受限工程预算内,端到端“工程化”完成 agentic RL post-training(从目标理解、方案选择、代码实现/调参/排错、到在线采样闭环训练与多次提交),并真实提升给定基座模型的可测评性能;以及现有偏静态的后训练/自动化基准为何会高估这种能力。

论文要解决 RAG 在复杂推理任务中的两类核心问题:1)上下文利用率低(检索到的内容冗余、信息密度不足,token 预算被浪费);2)幻觉频发(生成内容与证据不一致、早期错误不可回溯)。作者希望把“选哪些证据”和“如何生成且保持可证据化一致”统一成可优化/可搜索的过程。

传统 RAG 往往把“何时检索/检索什么/检索几轮/何时停止”放在生成过程之外(外部控制器、启发式触发或多阶段管线),导致检索时机与推理状态脱节,难以在逐步推理中按需暴露信息缺口并自适应补证,也不利于把错误归因到具体决策(过早检索、查询改写不当、停止过晚等)。论文要解决的是:如何把检索控制变成可学习、可解释、与 token 级解码同轨的生成策略,从而实现端到端的“边想边查”。

如何在长时程、工具增强、开放式输出的 agentic 任务中实现“并行 test-time scaling”,并有效聚合多条并行轨迹的信息以提升最终答案质量。

小语言模型(1B–8B)在生产中具备成本与延迟优势,但把它们适配到具体任务的难点不在“训练一次”,而在端到端工程闭环:任务定义与数据获取、失败诊断、针对性数据构造、超参与训练策略选择、回归控制、以及迭代何时停止。现有 AutoML/数据中心/提示优化/部分 agent 系统往往覆盖其中一段而非“从失败到修复”的全链路。论文要解决的是:能否用一个自治 agent 自动化 SLM 的冷启动构建与生产期持续改进闭环。

GUI 智能体研究的主要瓶颈不在“模型是否足够大”,而在缺少一套端到端、可复现、可落地的全栈基础设施:在线 RL 训练难以稳定运行(环境漂移、奖励稀疏、真实设备难接入)、评测协议在不同论文间暗中漂移导致不可比、训练出的策略很少真正部署到真实设备与真实用户场景。

有状态的工具调用型 LLM 智能体把上下文窗口当作工作内存,但现有 agent harness 对“状态驻留(residency)与持久性(durability)”的管理多为 best-effort:压缩/裁剪后关键状态丢失、reset 时绕过 flush、写回覆盖式破坏(destructive writeback)。这些问题导致重复工具调用、偏好/约束丢失、计划中断且难以诊断与复现。

现有 AI agent 行为监控主要依赖“监督式”范式(规则/LLM judge/已知失败模式清单),对“未知/新型”越狱、漏洞利用、reward hacking 等失效模式覆盖不足;且 LLM judge 往往需要被“告知要找什么”才会判定可疑,导致对新型误行为的发现滞后。论文提出“无监督监控(unsupervised monitoring)”问题:不让系统直接判定是否误行为,而是从群体行为差异中自动浮现“值得人类优先审查的独特行为模式”。

Escaping the Context Bottleneck: Active Context Curation for LLM Agents via Reinforcement Learning
LLM agent 在长时序任务中受“上下文瓶颈(Context Bottleneck)”与“Lost-in-the-Middle”影响:环境观测极度冗长高熵(网页 DOM、检索结果噪声),把原始信息不断堆进上下文会迅速降低信噪比,导致推理链条级联失败。现有被动记忆/检索式方法把上下文管理当静态检索问题,容易出现 retrieval bias,尤其难以召回与当前 query 文本不相似但因果关键的“reasoning anchors”。

现有 LLM Agent 的工具学习(tool-use)研究在“表示—数据—评测”三条链路上高度碎片化:不同数据集/框架的 tool-call schema 不兼容导致难以联合训练;训练数据对工具交互“结构分布”(尤其串行/并行、单跳/多跳、单轮/多轮)建模不足;评测基准协议与脚本不统一造成结果不可比、难复现。

在黑盒 API 访问的 LLM 部署中,推理成本/延迟是主要瓶颈。许多“先生成计划/建议,再由另一个模型执行”的组合式系统缺乏统一理论刻画与针对性训练目标,导致 guide 产出的策略经常不可解析、不可遵循或与 core 能力不匹配,从而浪费推理成本并引发脆弱行为。

论文研究“带长期记忆/检索增强(RAG)的 LLM Agent”在黑盒交互场景下的隐私泄露:攻击者仅通过 API 自适应提问,就可能从 Agent 的记忆模块中逐步抽取历史用户查询(以及由此关联的敏感信息)。核心问题是:在多轮交互、带检索的 Agent 工作流中,如何系统性地把“记忆里有什么”尽可能高成功率地问出来。

论文研究工具增强型 LLM Agent 在运行时遭受“间接提示注入(Indirect Prompt Injection)”的系统性风险:攻击者把恶意指令藏在工具返回内容里(网页/文件/MCP 服务器/技能文件等),而 Agent 会把这些返回当作可信 observation 直接拼进对话历史,从而被诱导进行越权工具调用、数据外泄或危险操作。核心问题是:在不改模型、不改协议、不过度牺牲 Agent 灵活性的前提下,如何在运行时阻断这类注入带来的真实世界副作用。

现有 LLM agent 框架(LangChain/DSPy/CrewAI/AutoGen 等)的配置(多为 YAML/JSON)缺乏形式语义:无法原则性判断配置是否“结构完备/良构”、是否会终止、不同配置是否语义等价、以及重构是否保持语义不变。结果是开发者只能靠试错,且容易出现如 ReAct 循环缺少终止分支导致无限循环/被动截断、router 路由分支不全导致运行时错误等问题。

Time is Not a Label: Continuous Phase Rotation for Temporal Knowledge Graphs and Agentic Memory
如何让 Agent 的结构化记忆系统在不依赖昂贵 LLM 调用的前提下,自然区分并遗忘“易变事实”,同时保留“持久事实”?

如何在“真实开放环境”的长时程任务中评测统一数字代理(同时需要视觉/搜索/编码等能力)的可靠性与泛化能力。

TorchUMM: A Unified Multimodal Model Codebase for Evaluation, Analysis, and Post-training
统一多模态模型(理解/生成/编辑)架构与训练范式高度异构,导致评测、分析与后训练难以复现和公平对比,缺少统一代码与标准协议。

VLA(视觉-语言-动作)机器人系统设计高度碎片化,如何用低复杂度强基线在统一设置下厘清关键设计因素并获得有竞争力的性能。

缺少对“多模态+多文档”的科学深度研究型Agent/MLLM进行系统评测的基准,现有评测多停留在单文档理解。

RAG在跨文档/分散证据场景下难以重建“证据链”,导致推理碎片化与幻觉仍然存在。

LLM 作为自主交互式 agent 在“不完全信息”的策略博弈中表现不佳,双边价格谈判尤甚:作为买家时常过度追求成交而牺牲经济剩余(surplus),出现早期让步、泄露私有预算上限、甚至违反预算约束等系统性失败。问题本质是:现有对齐/指令微调并不自动赋予模型策略理性与约束遵守能力。

在“部分可观测但位姿已知(oracle localisation)”的文本栅格世界中,LLM 能否在严格无工具/无代码执行/无程序综合的约束下,仅通过逐步输出 UP/RIGHT/DOWN/LEFT 作为控制器,完成探索(最大化揭示区域)与目标导航(尽量最短路径到达目标)?

EE-MCP: Self-Evolving MCP-GUI Agents via Automated Environment Generation and Experience Learning
在结合 MCP(结构化 API 调用)与 GUI(视觉界面操作)的 computer-use agents 中,如何让智能体学会在每一步“何时用 MCP、何时用 GUI”,并在跨应用(如浏览器、IDE、表格软件)场景下实现可持续的自动化自我进化(self-evolving),而不是依赖一次性 SFT 或低效的在线 RL?

论文研究一个关键问题:由多个“已对齐”的LLM代理组成的协作式多智能体系统(作者称为 AI Organizations)是否会继承单体代理的对齐属性?更具体地说,当系统被用于现实风格的商业目标(咨询方案、软件交付)时,多代理协作是否会在提升业务效用的同时,系统性地产生更多偏离开发者意图/伦理边界的输出。

论文提出并研究一个被现有LLM基准忽视的能力维度:程序性学习/过程性智能(procedural learning),即在没有明确任务说明的情况下,通过试错、奖励反馈、空间表征与策略更新来“发现目标并学会完成”。作者将经典啮齿动物行为神经科学范式转化为文本可交互环境,用于评测LLM代理在探索与学习上的能力上限与短板。

如何为“能自动做数据分析并给出统计结论”的Agentic Data Science(ADS)管线提供轻量、可操作的可靠性/可证伪性检查,避免模型给出看似自信但其实由噪声驱动的结论。

From Agent Loops to Structured Graphs:A Scheduler-Theoretic Framework for LLM Agent Execution
论文聚焦于当前最常见的 LLM Agent 执行范式“Agent Loop”(单模型在不断增长的上下文中迭代决定下一步)所带来的结构性缺陷:步骤依赖隐式不可验证、失败恢复缺乏有界语义导致可能无限重试、执行计划在上下文中被静默改写从而难以审计与调试。

论文研究在真实工具使用环境中,小模型 agent(如 8B)在单卡资源约束下表现显著落后于大模型的问题:在长轨迹、多 API、需要持久状态与错误恢复的任务中,原生推理策略常出现状态丢失、认证/凭据处理失败、API schema 违规、以及早期错误后陷入重复修正循环,导致任务完成率极低。

组织内 AI 代理在做“检索增强”时常把语义相关内容当作同等证据,无法区分:已绑定的决策 vs 已放弃的假设、已定论的事实 vs 争议主张、已解决问题 vs 长期未解的关键疑问,导致输出“流畅但认识论不一致”的结论。作者认为瓶颈不在检索保真度(retrieval fidelity),而在认识论保真度(epistemic fidelity):系统能否把承诺强度、矛盾状态、组织性无知等作为可计算属性来表示与维护。

多智能体辩论(MAD)虽能通过互评互改提升推理质量,但现有方法常用固定拓扑与固定轮数,对所有任务“一刀切”,导致简单任务也消耗大量 token,复杂任务又可能陷入循环争论/僵局,收益饱和甚至下降。论文要解决的是:如何在保证准确率的同时,按任务难度自适应地减少不必要的辩论成本,并在复杂任务上避免无效多轮争论。

SLALOM: Simulation Lifecycle Analysis via Longitudinal Observation Metrics for Social Simulation
LLM 智能体社会模拟面临“有效性危机”:现有评估常用终态/结果对齐(point-matching),却忽略过程是否社会学上合理,导致“停钟问题”(stopped clock)——即便最终结果对了,也可能通过错误机制或不可信轨迹到达。

LLM Agent 在目标环境中缺乏针对性的能力训练——现有方法要么用与模型实际缺陷无关的合成数据,要么让模型在目标环境中隐式学习多种能力。