AI Research Daily
更新时间: 2026/4/13 15:42:00
方法或结果明显独立成立的工作,建议读全文
论文关注长上下文 LLM 在线解码阶段的核心瓶颈:注意力计算与 KV-cache 访问/搬运成本(尤其在离线 prefill、在线 decode 的“Write-Once, Read-Many”复用场景)。问题是:在极高稀疏率下,如何在不训练/不改模型的前提下做稀疏注意力,同时避免 Query-Key 分布漂移导致的召回下降与质量劣化,并保持 GPU 友好的高吞吐实现?
Transformer 中 FFN/MLP 块占据主要参数与算力,成为长上下文与大模型训练/推理的瓶颈。现有 MoE 通过动态稀疏降低每 token 计算,但依赖额外路由器、负载均衡损失与复杂系统栈。本文要解决的问题是:能否用“无独立路由器、硬路由、结构化可跳过”的树结构 FF 层(FFF)在 GPT 式自回归语言建模中实现高动态稀疏,并在 1B+ 规模保持与稠密 FFN 相当的效果与可扩展性。
大模型预训练受限于算力与显存带宽,低精度训练是关键路径。FP4(4-bit 浮点)可显著提升吞吐与降低带宽,但极低精度带来数值不稳定,尤其是梯度量化在存在 outlier 时会因 block scaling 由最大值主导而产生系统性偏置与大量下溢为 0,破坏反传与优化。本文要解决的问题是:在华为 Ascend NPU 上,HiFloat4(HiF4)这种分层缩放 FP4 格式能否实现端到端大规模 LLM 预训练,并相对 MXFP4 以更少的稳定化“辅助手段”获得更小的 loss gap 与更低的性能开销。
论文研究一个“同样预训练损失但下游泛化不同”的几何本质问题:在多数据源预训练(K个source的加权平均loss)中,优化最终收敛到的参数,是仅仅最小化了总和损失(Sum-of-Minima 型:对每个source各自的最优点可能很远),还是落在各source最优解的“共同区域/交集附近”(Intersection-of-Minima 型:对每个source的最优点都几何接近)。作者提出:这种“任务最小值之间的几何接近度(closeness)”与下游泛化强相关,即使预训练loss完全相同,closeness更高的解也会显著更好地下游表现。
论文解决LLM训练的“内存而非算力”瓶颈,尤其是激活(activations)在大batch/长序列下占据峰值显存的大头。现有低秩方法多压缩权重/梯度/优化器状态,但对激活要么需要改架构,要么用固定投影导致随训练分布漂移而失效。核心问题是:能否在不改变前向计算的前提下,在线追踪并更新一个低维激活子空间,把反向所需的激活以低秩形式存储,从而同时压缩激活、梯度与优化器状态,并保持训练效果?
VLM 在解码器深层持续处理大量 image tokens 代价高,但“是否真的需要在深层持续处理图像 token、视觉表征是否在深层仍显著演化”并不清楚。本文从表征结构演化角度回答:视觉 token 在解码器中何时变得稳定/冗余、能否被截断/替换、这种冗余是否任务相关,以及截断后能否通过微调或推理链补偿。
偏好优化(DPO/KTO)在推理模型对齐中广泛使用,但“偏好对(chosen/rejected)到底通过什么信号带来推理能力提升”缺乏机制性理解。本文聚焦 delta learning:不是绝对质量而是 chosen 与 rejected 的质量差(delta)驱动学习,并进一步追问:delta 的来源(生成器层面 vs 样本层面)分别起什么作用?样本层面的哪些推理维度差异最关键?结果是否依赖最终答案正确性?
SUPERNOVA: Eliciting General Reasoning in LLMs with Reinforcement Learning on Natural Instructions
RLVR(可验证奖励强化学习)在数学/代码等“形式化领域”显著提升推理,但对因果、时间、常识、语用等“通用推理(general reasoning)”提升有限;根因在于缺少覆盖多种推理技能、且可自动验证的高质量训练数据。现有把 RLVR 扩展到更多“知识领域”的做法(如从网页抽取 QA)并不等价于提升通用推理技能,且验证困难、噪声大。
在 RLVR 中,GRPO 这类“仅看最终结果(outcome-only)”的方法稳定有效,但理论上更强的“细粒度 dense reward/advantage(按推理步骤/token)”在实际采样预算下反而更差。论文指出关键原因:用 Monte Carlo(从中间前缀采样多条续写并用最终对错回传)估计早期 token 的 advantage 时方差极高且符号经常出错(sign-inconsistent),导致训练方向不稳定,最终不如直接把 outcome reward 广播给所有 token 的 GRPO。
长链路(长 CoT)推理的 RLVR 场景中,标准 token-level PPO 依赖 token-level critic + GAE 做时序信用分配,但在“超长时域 + 稀疏终局奖励”下会出现结构性不稳定:优势估计高偏差、critic 在序列尾部语义线索上过拟合导致 advantage 在关键位置塌缩(tail effect),训练易震荡/崩溃。与此同时,critic-free 的 GRPO 虽更稳,但需要每个 prompt 多采样 N>1 来构造组内基线,吞吐受限、计算开销大。
LLM 的 RL 后训练(PPO/GRPO 等)普遍采用“尽量 on-policy”的 generate-then-discard:rollout 生成一次只用一次就丢弃。但在实际系统中生成(推理)成本极高,常占总 GPU 小时的 80%+,导致整体训练计算效率极差。社区普遍认为 replay 会因 off-policy(staleness)带来性能下降,因此很少系统研究在 LLM RL 中如何安全复用轨迹。
重大发布/开源/推理优化/部署/核心研究员观点

论文关注长上下文 LLM 在线解码阶段的核心瓶颈:注意力计算与 KV-cache 访问/搬运成本(尤其在离线 prefill、在线 decode 的“Write-Once, Read-Many”复用场景)。问题是:在极高稀疏率下,如何在不训练/不改模型的前提下做稀疏注意力,同时避免 Query-Key 分布漂移导致的召回下降与质量劣化,并保持 GPU 友好的高吞吐实现?

Introducing the OpenAI Safety Fellowship

论文聚焦于 PyTorch 编译器 torch.compile 中“正确性静默错误(correctness bugs)”:编译后的深度学习模型产生错误输出,但不抛异常、不崩溃、无告警,因而难以及时发现与定位。作者指出该类问题在 PyTorch 社区高优先级 issue 中占比高(约 19.2%),且会直接破坏下游 LLM 训练/推理的可靠性(例如导致训练不收敛)。
文本LLM预训练、架构创新、Scaling Law、数据/Tokenizer、高效训练、MoE、重磅技术报告

Transformer 中 FFN/MLP 块占据主要参数与算力,成为长上下文与大模型训练/推理的瓶颈。现有 MoE 通过动态稀疏降低每 token 计算,但依赖额外路由器、负载均衡损失与复杂系统栈。本文要解决的问题是:能否用“无独立路由器、硬路由、结构化可跳过”的树结构 FF 层(FFF)在 GPT 式自回归语言建模中实现高动态稀疏,并在 1B+ 规模保持与稠密 FFN 相当的效果与可扩展性。

大模型预训练受限于算力与显存带宽,低精度训练是关键路径。FP4(4-bit 浮点)可显著提升吞吐与降低带宽,但极低精度带来数值不稳定,尤其是梯度量化在存在 outlier 时会因 block scaling 由最大值主导而产生系统性偏置与大量下溢为 0,破坏反传与优化。本文要解决的问题是:在华为 Ascend NPU 上,HiFloat4(HiF4)这种分层缩放 FP4 格式能否实现端到端大规模 LLM 预训练,并相对 MXFP4 以更少的稳定化“辅助手段”获得更小的 loss gap 与更低的性能开销。

论文研究一个“同样预训练损失但下游泛化不同”的几何本质问题:在多数据源预训练(K个source的加权平均loss)中,优化最终收敛到的参数,是仅仅最小化了总和损失(Sum-of-Minima 型:对每个source各自的最优点可能很远),还是落在各source最优解的“共同区域/交集附近”(Intersection-of-Minima 型:对每个source的最优点都几何接近)。作者提出:这种“任务最小值之间的几何接近度(closeness)”与下游泛化强相关,即使预训练loss完全相同,closeness更高的解也会显著更好地下游表现。

论文解决LLM训练的“内存而非算力”瓶颈,尤其是激活(activations)在大batch/长序列下占据峰值显存的大头。现有低秩方法多压缩权重/梯度/优化器状态,但对激活要么需要改架构,要么用固定投影导致随训练分布漂移而失效。核心问题是:能否在不改变前向计算的前提下,在线追踪并更新一个低维激活子空间,把反向所需的激活以低秩形式存储,从而同时压缩激活、梯度与优化器状态,并保持训练效果?

扩散式语言模型(dLLM)在推理时需要决定“先解哪些 token/按什么顺序解码(permutation / order)”。现有解码顺序多用基于 token 置信度/熵/边际的局部贪心规则,只利用输出分布的局部信息,忽略全局序列结构,且缺乏与“最大化目标序列对数似然”之间的明确理论对应,因此常产生次优解码轨迹与质量损失。

Breaking Block Boundaries: Anchor-based History-stable Decoding for Diffusion Large Language Models
半自回归(Semi-AR)解码是 dLLM 中常用推理框架:把序列分成若干 block,按 block 依次完成解码。但该机制存在“block 边界约束”:必须先完成当前 block 才能开始下一个 block,导致大量其实早已稳定(与最终输出一致且后续保持不变)的跨 block token 被无谓延迟解码(Block-Boundary Delay),浪费迭代步数并抑制局部区域的收敛传播(radiative effects)。关键难点变成:如何可靠识别这些跨 block 稳定 token 并提前解锁?

Initialisation Determines the Basin: Efficient Codebook Optimisation for Extreme LLM Quantization
论文聚焦于极低比特(尤其 2-bit / 2 bpp)下的自由形式(free-form)加性量化(additive quantization, AQLM 系列)为何经常“灾难性失败”。作者指出关键瓶颈并非搜索预算(beam width、校准集大小、层内迭代次数)或后续微调(PV-tuning),而是更早阶段的码本(codebook)初始化:常用的贪心/残差 k-means 顺序初始化会把优化带入糟糕的 basin,后续再多搜索与微调也难以完全逃逸。

论文研究“更多训练数据是否值得其成本”,但刻意把问题缩小到一个可控的微型设置:使用强约束的 attention-only decoder(移除 MLP、冻结 embedding 与输出层)来隔离 dataset size 对性能的影响。核心问题是:在这种 tiny、组件隔离的 Transformer 中,数据规模是否仍呈现类似 Kaplan 等提出的 scaling-law 式平滑提升与边际收益递减?以及达到接近满数据性能需要多少数据?

MoE Transformer 的“条件计算”带来一个核心理论缺口:误差/泛化/缩放到底应当由“每个输入实际激活的参数量(active capacity)”主导,还是由“总参数量 + 路由组合复杂度”主导?现有 dense scaling law 直接用总参数刻画会误配 MoE;而仅看 active 参数又忽略了路由模式数量带来的统计开销。

标准自注意力对任意距离的 token 对一视同仁(scale-blind),既缺乏多尺度结构先验,又在长序列上带来二次复杂度与性能瓶颈。问题是:能否在不只是“稀疏化/近似注意力矩阵”的前提下,引入结构化的多尺度注意力,并给出可解释的近似误差保证?

Watt Counts: Energy-Aware Benchmark for Sustainable LLM Inference on Heterogeneous GPU Architectures
缺少可复现、可对比的能耗评测与数据,导致LLM推理部署难以在异构GPU上做能效最优决策。

降低Transformer注意力中Softmax/Sigmoid等非线性算子的推理延迟瓶颈,探索模拟光电器件实现替代非线性。
VLM、多模态理解、统一模态预训练、多模态对齐、视觉-语言模型

VLM 在解码器深层持续处理大量 image tokens 代价高,但“是否真的需要在深层持续处理图像 token、视觉表征是否在深层仍显著演化”并不清楚。本文从表征结构演化角度回答:视觉 token 在解码器中何时变得稳定/冗余、能否被截断/替换、这种冗余是否任务相关,以及截断后能否通过微调或推理链补偿。

在工业级真实场景中,LLM 需要同时具备强语言能力、强推理能力与视觉理解能力;但 VLM 面临“高分辨率带来海量视觉 token → 计算/吞吐瓶颈”和“压缩视觉 token 又会显著掉点”的矛盾。论文要解决的是:在不牺牲视觉信息密度的前提下,把视觉能力高效、稳定地接入一个已具备双模式(非推理/推理)的 32B 语言底座,并保持可部署的推理效率与多语种能力。

UI-to-Code生成中视觉token极长导致prefill延迟高,现有压缩要么不真正缩短序列、要么与UI信息密度不匹配,难以在保持生成质量的同时显著降token与延迟。

多模态大模型(MLLM)在面对文本 jailbreak 与图像对抗(如排版触发、反事实语义、不可感知扰动)时容易输出有害/违规内容。现有安全方案(提示词、响应过滤、微调)分别存在脆弱、需要重复调用、或成本高的问题。激活(表示)steering 虽然灵活,但现有方法要么概念集合太小、要么强度难校准、要么 SAE 特征缺乏语义落地导致难以精确控制某个安全概念而不伤及其他能力。论文要解决的是:在冻结模型参数的前提下,实现“可扩展、可标注、可精细解耦”的多概念安全控制。

RLVR/GRPO 等后训练虽提升了 VLM 的链式推理与可验证正确率,但模型推理过程仍呈“文本主导”:对图像 token 的注意力激活稀疏,且随推理步数增加出现 temporal visual forgetting(视觉证据在后续步骤被逐步遗忘),导致依赖语言先验、视觉不忠实与幻觉/推理错误。

解决VLM在空间理解、视角识别等基础视觉感知技能上的短板,探索“仅给任务关键词”能否自动生成有针对性的合成监督来补齐能力。

现有 Video-LLM 往往把视频理解当作“非结构化 CoT 文本生成”:关键视觉证据被冗长描述淹没,时间维度被退化为零散帧检索,因果关系建模薄弱,导致 reasoning drift、因果推断脆弱;同时在 RL 对齐阶段,结构化事实密度与推理深度/长度预算存在冲突,多目标奖励直接标量化会造成优势估计方向不清、训练不稳定。

现有视频-语言基础模型在教学视频(长、非裁剪、包含多步程序)中对“动作/动词语义”的理解不足:训练时容易被 ASR 文本噪声与弱对齐误导;表征上存在“静态偏置”(更依赖物体/背景等静态线索而非运动线索);同时缺乏对多动作时序结构(步骤顺序、跨步对齐)的建模能力。

视频时序定位(VTG)中,Video LLM/MLLM 需要输出时间边界,但现有方法的“时间输出范式”与骨干网络、数据、训练协议强耦合,导致无法判断性能差异究竟来自输出设计还是其他因素;同时面向边缘/端侧部署时,不同输出范式在参数开销、训练稳定性、推理确定性与算力成本上的系统级权衡缺乏受控分析。

流式视频理解中的“Agent记忆图”(以文本节点为主)会随时间快速膨胀,导致存储成本与检索延迟显著上升;在实时问答场景下,检索变慢会直接破坏可用性。同时,直接压缩记忆又容易丢失长期一致性与关键细节,造成准确率下降。

视频LLM的计算瓶颈主要在LLM侧的长序列自注意力与FFN,视觉token数量直接决定推理成本。现有训练free token pruning两大范式存在关键缺陷:注意力Top-k选择无法覆盖多模态、长尾的注意力分布(且易受attention sink影响);直接基于相似度的聚类会产生空间碎片化簇,池化后对象几何结构被破坏,导致表征失真。

论文研究“独立预训练”的视觉编码器(DINOv2)与文本编码器(MiniLM)在不联合训练、仅靠少量配对锚点(anchors)的情况下,能否通过一种具有几何可解释性的方式实现跨模态对齐;并进一步诊断两种模态表征流形在“内在复杂度”和“谱基方向/取向”上是否一致。

传统ASR以WER为主难以衡量句子级语义正确性,且缺少对“交互式纠错”这一类人机对话式ASR能力的系统研究与评测。

3D环境中的具身多模态代理使用3D-LLM推理时易产生与物体存在/空间布局/几何不一致的幻觉,导致不安全与不落地决策。

如何在跨文本/音频/视频的“蕴含/假设检验”式推断中输出可校准的概率(而非二分类标签),并评估模型的不确定性质量。

解决图像内容审核模型缺乏空间定位与可解释性的问题,构建可用于“敏感行为-参与者-位置关系”解释的场景图基准与训练方案。

PinpointQA: A Dataset and Benchmark for Small Object-Centric Spatial Understanding in Indoor Videos
现有视频多模态模型缺乏对“室内视频中小物体的精确定位与可用空间表达”的直接评测,导致模型空间理解能力难以被诊断与推动。

在复杂3D场景中实现面向开放式问题的“先精确grounding再推理”的零样本/免训练3D grounded reasoning。

缺少支持“专家级、整体穿搭理解”的多模态数据与评测,限制VLM在风格/场合/兼容性等高层语义推理能力上的进展。

面向长时域具身任务的VLM/世界模型训练中,如何获得高质量、低幻觉的长链条“可对齐的思考-行动-空间”标注数据,以减少长视野指令跟随中的跳步、幻觉与物理不一致。

Hidden in Plain Sight: Visual-to-Symbolic Analytical Solution Inference from Field Visualizations
从物理场的可视化图像(及一阶导数等元信息)中恢复可执行的解析符号解(SymPy表达式),实现“视觉到符号”的科学推理。

缓解听觉大模型(ALLMs)在音频理解/音频描述生成中的幻觉,并提供更细粒度的评测而非二分类。

如何让用于推荐系统评测的“用户模拟”型VLM/LLM agent不再只看文本/结构化特征,而是对齐真实用户在UI布局上的个性化注视(gaze)模式,从而提升点击行为模拟的真实性。

在多模态边缘推理中,面对功耗波动与传感器缺失,实现无需部署后微调的模态感知剪枝与更高效注意力。
图像生成、视频生成、语音合成、音乐/3D生成、Diffusion模型

论文关注视觉生成模型在“高质量”与“参数/内存效率”之间的矛盾:传统做法通过堆叠大量不共享参数的 Transformer 层来提升容量,导致参数量与显存占用线性增长、吞吐受“memory wall”限制。作者提出能否用循环/权重共享的 Transformer,在保持生成质量的同时显著减少参数,并且让模型在推理时可按算力预算随时提前退出(Any-Time/Elastic inference)。

扩散模型训练高度依赖大规模图文对数据,但纯扩散生成的合成数据常出现几何/语义不一致,并可能在“用生成数据再训练生成模型”的闭环中触发模型自噬(MAD)导致性能退化。论文要解决的是:如何可扩展地产生高一致性、高可用的合成图文对,用于扩散模型训练/补充真实数据,同时降低MAD风险。

Rectified Flow/Flow Matching虽理论上能“拉直”生成轨迹以减少采样步数,但实践中仍需要较多函数评估。论文指出高曲率的重要原因之一是源分布(通常标准高斯)与数据分布独立、耦合不对齐,导致前向耦合产生大量轨迹交叉,模型学习到的向量场趋向平均方向而变弯。要解决的是:如何通过更好的源-目标耦合/源分布设计,进一步降低轨迹曲率,从而在更少步数下保持或提升生成质量。

一致性模型(Consistency Models, CMs)采样快(1~few steps),但主流“指导(guidance)”能力(如扩散模型中的CFG)通常依赖从扩散模型教师蒸馏而来,导致:1)指导与Consistency Distillation(CD)强绑定,Consistency Training(CT)类预训练CM难以获得后验(post-hoc)指导;2)难以像DM那样在同一模型上仅通过推理时调参评估“指导本身”的收益。本文要解决的问题是:在不依赖DM教师的前提下,如何对一个已预训练的、原本无指导能力的CM进行轻量后处理,使其具备类似CFG的可调指导效果。

扩散/流模型的“奖励微调(reward fine-tuning)”与从Boltzmann/tilted分布采样可统一表述为随机最优控制(Stochastic Optimal Control, SOC)问题:在SDE约束下学习最优控制以最小化代价/最大化回报。近期Adjoint Matching(AM)方法把该问题转成回归式损失并在实践中有效,但原工作主要是启发式、局限于控制仿射+二次代价等特殊设定,缺乏从控制理论一阶条件出发的严格推导,也难以推广到更一般的控制依赖漂移/扩散与更一般代价。本文要解决:为AM建立严格的SMP(随机最大值原理)理论基础,给出可推广的Hamiltonian形式目标,并解释其为何对应有效的“控制改进”步骤。

指令式视频编辑通常需要大量高质量编辑数据,但现实中编辑数据稀缺,如何用更少数据把视频生成模型适配成强视频编辑器。

Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
交互式视频生成作为world model时,难以同时实现长时一致性(带记忆)与高分辨率实时生成,限制真实交互场景落地。

CT-1: Vision-Language-Camera Models Transfer Spatial Reasoning Knowledge to Camera-Controllable Video Generation
在视频生成中实现可控且物理合理的相机运动:解决文本控制不精确与手工轨迹参数成本高的问题。

弥合物理真实的PBR与视觉“照片真实感”(PRR)之间的差距,在可控性/几何一致性与生成逼真度之间取得统一。

缓解物理世界视频/动态场景的“物理一致性”训练数据稀缺问题,并系统评估/提升基础模型在物理现象上的学习与推理能力。

为具身学习合成可用于策略学习的数据:在语言/视觉条件下联合生成“视频+动作轨迹”,避免仅生成世界视频却缺少配对动作的问题。

AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
现有Text-to-Audio-Video(T2AV)生成评测割裂且粗粒度,难以衡量真实提示词下音视频联合语义正确性与可控性,亟需任务驱动、细粒度的统一评测基准。

如何用神经网络自动化近似人类主观听感评价(MOS/SBS),以低成本、可扩展地评测TTS系统质量。

在文本到3D生成中缓解“仅文本条件”带来的可控性不足与纹理歧义,并实现参考图像风格对3D结果的可控迁移。

仅依赖稀疏机器人触觉接触点时,如何在强欠约束条件下重建物体全局3D几何。

解决自回归Transformer生成高质量3D网格时的token序列组织问题:现有坐标排序序列过长、patch启发式破坏边流与结构规律,难以达到艺术家级建模标准。

在不重训扩散模型的情况下,实现对DiT图像生成的概念移除/风格迁移/对象偏置等可控编辑,并尽量保持其余提示词内容与画质。

在不重新训练扩散模型的前提下,于推理阶段实现对指定概念(显式内容/版权角色/风格等)的有效“擦除”且尽量保持提示词语义一致。

在用户指定局部区域的前提下进行图像细节修复/增强,同时严格保持非编辑区域像素不变,解决局部细节塌陷问题。
RL/RLHF/RLVR/DPO/对齐/Instruction Tuning/Safety

偏好优化(DPO/KTO)在推理模型对齐中广泛使用,但“偏好对(chosen/rejected)到底通过什么信号带来推理能力提升”缺乏机制性理解。本文聚焦 delta learning:不是绝对质量而是 chosen 与 rejected 的质量差(delta)驱动学习,并进一步追问:delta 的来源(生成器层面 vs 样本层面)分别起什么作用?样本层面的哪些推理维度差异最关键?结果是否依赖最终答案正确性?

SUPERNOVA: Eliciting General Reasoning in LLMs with Reinforcement Learning on Natural Instructions
RLVR(可验证奖励强化学习)在数学/代码等“形式化领域”显著提升推理,但对因果、时间、常识、语用等“通用推理(general reasoning)”提升有限;根因在于缺少覆盖多种推理技能、且可自动验证的高质量训练数据。现有把 RLVR 扩展到更多“知识领域”的做法(如从网页抽取 QA)并不等价于提升通用推理技能,且验证困难、噪声大。
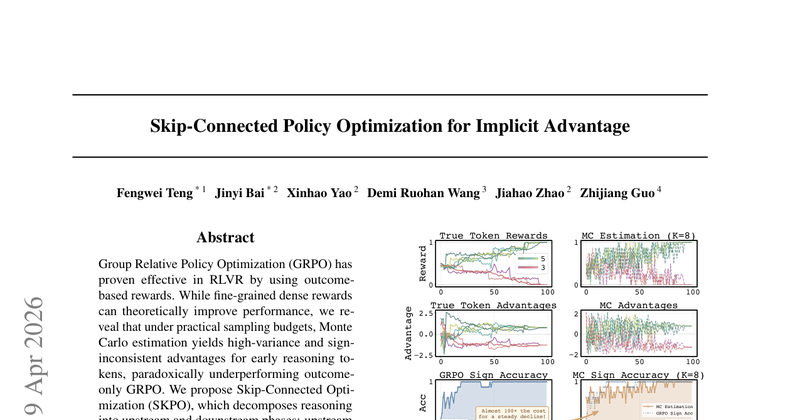
在 RLVR 中,GRPO 这类“仅看最终结果(outcome-only)”的方法稳定有效,但理论上更强的“细粒度 dense reward/advantage(按推理步骤/token)”在实际采样预算下反而更差。论文指出关键原因:用 Monte Carlo(从中间前缀采样多条续写并用最终对错回传)估计早期 token 的 advantage 时方差极高且符号经常出错(sign-inconsistent),导致训练方向不稳定,最终不如直接把 outcome reward 广播给所有 token 的 GRPO。

长链路(长 CoT)推理的 RLVR 场景中,标准 token-level PPO 依赖 token-level critic + GAE 做时序信用分配,但在“超长时域 + 稀疏终局奖励”下会出现结构性不稳定:优势估计高偏差、critic 在序列尾部语义线索上过拟合导致 advantage 在关键位置塌缩(tail effect),训练易震荡/崩溃。与此同时,critic-free 的 GRPO 虽更稳,但需要每个 prompt 多采样 N>1 来构造组内基线,吞吐受限、计算开销大。

LLM 的 RL 后训练(PPO/GRPO 等)普遍采用“尽量 on-policy”的 generate-then-discard:rollout 生成一次只用一次就丢弃。但在实际系统中生成(推理)成本极高,常占总 GPU 小时的 80%+,导致整体训练计算效率极差。社区普遍认为 replay 会因 off-policy(staleness)带来性能下降,因此很少系统研究在 LLM RL 中如何安全复用轨迹。

论文研究扩散语言模型(dLLM)安全对齐的一个“承重假设”:一旦在去噪过程中提交(commit)的 token(尤其是拒答 token)就不可逆、永久固定。作者证明该假设在推理时可被“轨迹级”操控绕过:在模型早期已经提交拒答词后,攻击者将这些已提交位置重新置为 [MASK](re-mask),再注入极短的肯定/服从前缀(prefix),即可把后续去噪轨迹从拒答重定向到合规输出。

论文关注“大模型文化对齐”评估的缺口:现有评测往往默认存在单一正确答案,难以刻画不同语言/文化群体对同一叙事的价值解读差异。作者提出“多语言故事寓意(moral)生成”作为文化扎根的评估任务:给定故事摘要,让模型生成该故事的道德寓意/教训,并与来自对应语言–文化群体的人类寓意分布进行比较,从而衡量模型是否能再现人类的跨文化解释变异。

论文研究“persona prompting(角色/人设提示)”带来的性能波动:同一模型在不同persona下任务表现差异巨大,最佳persona难以预测,导致需要昂贵的推理时prompt试错/搜索。作者进一步追问:这种persona敏感性是否与后训练(post-training)目标有关,能否在训练阶段让模型对persona变化更鲁棒,同时在需要时仍能保持角色表达力(fidelity/expressivity)。

论文聚焦多源异构指令共存时的“层级指令遵循(instruction hierarchy)”:系统指令、用户指令、工具输出/检索内容、历史对话等往往部分冲突且多为“良性冲突”(非对抗注入)。现有工作多强调安全攻击场景,较少系统解决日常应用中“既要遵循高优先级约束、又要尽量保持任务效用与行为一致性”的层级冲突解析问题。

论文研究一个“反身性(reflexive)”安全一致性问题:同一个LLM在被要求“精确描述自己的安全边界/规则”时所陈述的政策(self-stated policy),是否与它在真实有害请求基准上的实际行为一致。现有评测多用外部标准衡量“是否安全”,但不衡量“是否遵守自己声称的规则”,因此无法发现“模型自我承诺—行为执行”之间的系统性断裂。

From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
论文聚焦LLM强化学习中的核心瓶颈——信用分配(Credit Assignment, CA):当奖励是稀疏的、结果级的(例如“最终答案是否正确”“任务是否完成”),如何把功劳/责任分摊到长轨迹中的具体动作(token、推理步骤、工具调用、对话轮次)。该问题在两类场景中显著恶化:reasoning RL(单次超长CoT生成,500到30K+ token)与agentic RL(多轮与环境交互、随机转移、部分可观测、100+轮、100K–1M token)。

论文研究“为什么系统提示词(system prompt)的自动优化在不同任务上效果极不稳定”。作者将提示词优化视为RL问题:策略生成候选system prompt,用冻结LLM在数据集上的准确率作奖励;核心问题是:何时存在足够清晰的优化信号、何时信号会被生成随机性与数据异质性淹没,从而导致“算力堆不出更好prompt”。

论文解决LVLM(大视觉语言模型)在多模态推理中“答错但很自信”的校准问题,尤其是幻觉(hallucination)导致的高置信错误。作者指出:沿用文本LLM的“单一整体置信度+答案对错二值监督”的口径不适配LVLM,因为错误可能来自两类不同源头——视觉感知失败(没看对图/没grounding)或在感知正确前提下的推理错误;单一置信度会混淆两者,并且视觉不确定性常被语言先验掩盖。

论文聚焦于真实部署中 VLLM 的“多语言 + 多模态复合攻击”安全失效:有害图像与低资源语言文本组合可绕过主要针对英语/单模态设计的防护。核心机制问题是:安全能力在模型内部“落在哪些神经元/层”,以及它在不同语言与模态间如何共享或分化,从而导致 HRL(高资源语言)与 NHRL(非高资源语言)安全差异。

论文研究 Tool-Integrated Reasoning (TIR) 代理的早期训练困境:Zero-RL 缺乏先验引导导致探索低效、易退化到过度调用工具的“react mode”;SFT-then-RL 虽有起步优势但依赖昂贵合成数据,且后期易出现能力僵化与低熵坍塌(多样性下降、性能平台期)。核心问题是如何在不大量依赖 SFT 数据的前提下,提高早期探索效率与多样性,并保持后续 RL 的可持续提升。
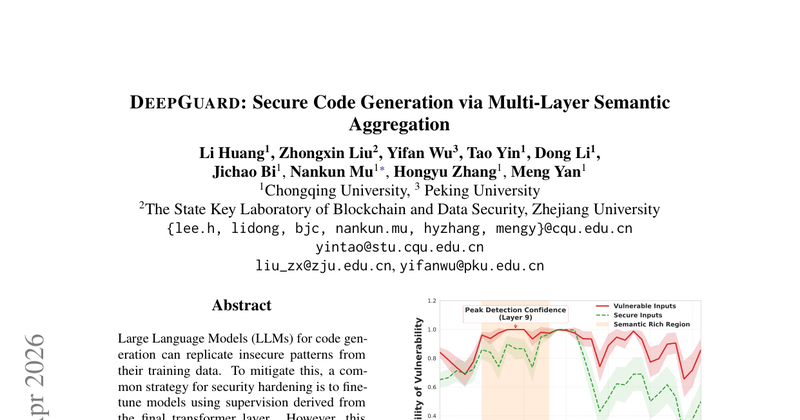
代码大模型会从训练语料中继承不安全编码模式,现有安全加固微调/对齐方法往往只利用最后一层(final layer)的表示来提供监督信号,导致“final-layer bottleneck”:与漏洞判别相关的线索分布在多层,靠近输出层时反而变得不易分离,从而限制安全能力提升。

LLM 强化学习(RL)训练中,trainer 高频产出新权重、海量 rollout worker 频繁拉取权重,权重传输成为系统瓶颈。现有方案要么依赖静态通信组(如 NCCL)难以应对弹性/故障;要么点对点扇出导致拥塞(如 UCX);要么通过分布式存储实现解耦但引入“push 到存储 + pull 到 worker”的双倍数据搬运与巨大存储开销,尤其在 TB 级权重下不可承受。

论文研究一种区别于提示注入/工具误用的新型智能体供应链风险:第三方“技能(skill)”在发布时可捆绑一个小模型(model-in-skill),该模型在表面正常完成任务的同时,被后门微调为仅在“结构化技能参数”满足攻击者设定的语义组合触发条件时,执行隐藏恶意载荷(payload)。核心问题是:当恶意逻辑被编码进技能内置模型权重而非显式代码分支时,传统代码审计与输入净化难以发现。

Spectral Geometry of LoRA Adapters Encodes Training Objective and Predicts Harmful Compliance
论文探讨一个“无需跑推理、只看权重”的问题:LoRA 微调产生的权重增量(ΔW)在谱几何(spectral geometry)上是否能识别微调目标(objective fingerprinting),并且这种几何信号是否能预测下游有害行为(harmful compliance)。更具体地:能否区分同一训练方法(DPO)下不同的目标(如反转 harmlessness vs 反转 helpfulness),以及这种区分是否与攻击成功率相关。

统一后训练中如何同时利用 SFT 的稳定低方差与 RL 的探索低偏差,但避免两者梯度信号在统计上“高偏差 vs 高方差”的结构性冲突;以及如何处理不同难度样本在统一目标下学习信号可靠性差异巨大(易样本饱和、难样本奖励稀疏、中等样本最有效)。

现有推理 RL 多以“最终答案正确性”作为主要反馈,难以约束推理过程的逻辑稳定性,导致输出虽流畅相关但出现逻辑跳步、结构紊乱、冗余循环等过程性错误;需要一种无需昂贵 LLM-as-a-judge 的可计算信号来奖励稳定推理轨迹。

现有 RLHF(PPO/DPO 及其变体)在训练分布与部署分布存在轻微偏移(措辞、格式、符号、语言等)时,容易出现性能大幅波动,尤其在多步数学推理中表现为不稳定与鲁棒性不足。即便是 token-level 的对齐方法(如 RTO)改善了 credit assignment,也仍会受 reward 噪声与 minibatch 组成影响,导致更新不稳、对分布移位敏感。

去中心化(分布式)后训练在结合数据并行(DP)与流水线并行(PP)时,存在被恶意参与方注入后门/误对齐的风险。现有针对 PP 的研究多为非定向的 poisoning(易被训练损失/性能监控发现),缺少“定向且隐蔽”的 backdoor 攻击:攻击者仅控制中间流水线 stage、看不到明文 token,也不掌控全模型或全数据,仍希望在不显著破坏 SFT 性能的情况下植入触发式不安全行为。

如何评测并量化LLM在“幽默偏好”上的对齐程度,以及模型偏好与人类偏好不一致时的系统性原因(如位置偏置)。

如何在用户侧主动防护个人图片,防止开源/开放权重多模态大模型对图片进行隐私敏感分析与信息提取。

多模态越狱攻击在“开源替身模型→闭源商业VLM目标”的异构迁移场景下效果显著下降(surrogate dependency),缺少有效的黑盒/闭源可迁移攻击方法与评估。

面向语音/音频作为主要交互入口的基础模型,缺乏覆盖多威胁模型的系统化风险分类与可操作的安全评测基准,导致音频安全防护难以全面落地。

SFT 后常用不确定性/置信度分数与输出质量的相关性会退化,导致置信度无法可靠指示幻觉或错误。

在仅有 100-500 标注样本的翻译生成任务中,主动学习(informativeness/diversity)为何常常不优于随机采样?

Automated Instruction Revision (AIR): A Structured Comparison of Task Adaptation Strategies for LLM
在少量样本条件下,系统比较多种LLM任务适配策略(规则归纳式指令修订、提示优化、检索、微调等)在不同任务类型上的适用性与边界。

在最坏情况误报(false-alarm)约束下,如何实现LLM生成式多比特水印的最优编码-解码方案并刻画其可达性能边界。

在Chain-of-Thought(CoT)蒸馏中,重新审视“教师-学生能力差距(capacity gap)”是否真的是失败主因,并指出常见评测设置会掩盖蒸馏后相对学生原始能力的退化问题。

在自动化决策中,LLM如何在不确定性下权衡“直接行动”与“升级/交由人工处理(escalate)”,以及如何让模型学到目标升级策略并具备跨域泛化。

在音频LLM(语音-文本交互)中实现“兼顾效用”的越狱攻击:在提高jailbreak成功率的同时尽量保持转写与问答等正常能力不被破坏。

在有限预算下,如何通过自适应采样的成对偏好比较(pairwise comparisons)高概率识别一组候选LLM策略/政策中的最优者,并刻画所需数据量与最优采样分配。

在极端算力/时间约束下(单张A100 40GB、24小时)对70B级基础模型进行高效微调并尽量保持效果。
Interpretability/ICL/CoT原理/Attention分析/涌现/泛化/幻觉/反常识发现/Scaling分析/基础DL分析

论文要回答:一个神经网络里到底有多少参数真正承载“任务特定信息”?进一步地,如果把骨干网络权重完全随机初始化并冻结(不预训练、不更新),仅训练每层的低秩 LoRA 适配器,是否仍能逼近“全参数训练”的性能上限?

大推理模型(LRM)依赖长链式思维(CoT)获得高准确率,但普遍出现“过度思考”:不论题目难度都倾向生成冗长推理,带来高延迟与高算力成本;同时长CoT会放大早期局部偏差与幻觉,错误在反思/自洽中累积。现有CoT压缩多为任务级(task-level)调节,缺少对推理链不同阶段冗余来源的逐步(step-wise)建模与自适应策略选择。

长上下文LLM并不等于“会用长上下文”。论文指出在推理模型中存在更尖锐的失效模式:随着链式思维变长,模型在后续从上下文中检索关键信息的能力会显著下降,即 lost-in-thought——推理步骤本应提升效果,却反过来让后续in-context retrieval更困难(推理产生的语义相关但干扰性token增多、注意力被中间推理占据等)。现有方法多假设“推理前一次性检索足够证据”,无法覆盖推理过程中动态出现的新检索需求。

Large Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
对齐后的 LLM 仍可被 jailbreak、解码策略变化或窄域微调触发有害输出(含“涌现失配”EM)。核心问题是:模型内部的“有害性生成”到底是分散的表层模式拼接,还是被压缩成一个相对统一、可定位的机制?

公共文本生态正在进入“人类—AI—平台管线”的递归反馈回路:模型生成草稿/建议→人类选择发布→排序/审核/验证/去重/语料清洗决定哪些文本进入公共记录→未来模型再用这些公共记录训练。核心问题是:在这种递归环境中,公共文本分布会如何随时间演化?哪些变化来自中性漂变(drift),哪些来自选择(selection),以及后续学习者究竟继承了什么?

论文聚焦 Transformer 语言模型表示空间的“各向异性”(anisotropy):token/句向量并非均匀铺展,而是集中在少数主方向形成“窄锥”,导致无关样本余弦相似度偏高。作者进一步追问:这种现象到底是训练病态、语言/句法几何的必然结果,还是学习动力学对某些“切向方向”(tangent directions) 的系统性放大?

From Dispersion to Attraction: Spectral Dynamics of Hallucination Across Whisper Model Scales
论文研究大规模 ASR Transformer(Whisper)中的“幻觉”(hallucination) 机制:在静音、噪声或对抗扰动下,模型会生成与声学输入脱耦但内部置信度很高的转写(包括循环、背诵训练片段等)。核心问题是:这种失效为何随模型尺度出现系统性变化,且传统指标(WER、token logprob)难以及时预警?

预训练模型(视觉/语言)通常只输出softmax概率,缺乏可靠的后验不确定性刻画;主流后验不确定性方法(Deep Ensembles、MC Dropout、Laplace等)在大模型上推理或适配成本过高;而EDL虽可单次前向输出Dirichlet二阶分布,但要求从训练之初就以“证据/Dirichlet参数”为目标训练,难以直接用于现成的预训练网络。

如何用Transformer实现一个可扩展、可编译、可执行通用程序的“解析构造(非学习)”神经计算机:既要支持多指令集(不止SUBLEQ单指令),又要保持固定步成本(每步一次前向、与程序长度/历史无关),并能在有限层数与参数规模下运行实际程序(如游戏、数独)。

论文试图回答:Chain-of-Thought(CoT)为何能提升复杂任务表现、它本质上如何“分解”任务、以及“多想/更长推理”何时有益或有害。作者将许多LLM任务抽象为“从大量候选答案中选一个”的分类问题,并研究把一个大分类拆成一串小分类(树结构决策)时,整体错误率如何变化。

Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in Language Models
标准LLM评测只关注assistant回复质量,忽略了模型是否编码了对后续交互的感知能力(interaction awareness)。

现有数学推理评测对格式高度过拟合,如何系统评估LLM推理对输入扰动/格式变化的鲁棒性,并区分“解析失败”与“推理失败”。

从表示空间(embedding/hidden states)层面审计与量化foundation models的去偏(bias mitigation)效果,并分析去偏如何改变内部几何结构。

LLM-as-a-Judge/自动评测的“严格程度”难以随应用场景(安全关键 vs. 日常对话)自适应,导致与人类偏好对齐不稳定。

量化并非均匀降低 LLM 的“元认知/自信-正确性匹配”,而是会在不同知识域上重塑其元认知效率的几何结构。

解释与定位RAG中“明明检索到相关证据仍产生幻觉”的原因,细化到问题的原子推理要素(facets)层面评估证据充分性与使用情况。

参考答案(reference-based)的生成式LLM评测中,如何避免词面/格式匹配(lexical)导致的误判,同时又不引入LLM-as-a-Judge的高计算成本。

解释VLM在视觉-语言冲突(例如图像是蓝香蕉但回答“黄”)时失败的根因:是“看不见”(perceptual blindness)还是“仲裁失败”(arbitration failure)。

LLM在“创造性发散思维”任务中,其内部表征与人脑活动是否对齐、对齐如何随模型规模与创意质量变化。
通用AI Agent/Coding Agent/SWE-bench/Tool Use/Code Generation/软件工程Agent

论文关注编码/SQL智能体在规格不完整、含糊或自相矛盾时的关键失败模式:不会在合适时机向人类请求澄清(selective escalation),而是自信地做假设并产出看似合理但错误的结果。现有基准多提供完备指令,只评执行正确性,无法区分“应该问但没问”和“蒙对了”。

如何在软件工程类LLM coding agent中,自动化地为“技能/指令模块(skills)”做组合与调参,以同时优化成功率、成本与运行时延,避免人工反复试错。

移动端GUI自动化代理(VLM/LLM驱动)从“建议”走向“代操作”后,动作空间巨大且不可逆高风险(转账、授权、隐私外发等)。现有防护(提示词自检、启发式规则、VLM-critic)缺乏形式化保证、难以在分布漂移下校准,且无法提供用户可调的风险-自主性权衡。

现有LLM Agent多默认“单用户/单委托人”范式,难以在多用户(多角色/多权限/多偏好)同时协作时处理冲突、信息不对称与隐私约束。

LLM在多轮对话中因指令/关键信息分散而“迷路”导致性能下降,同时直接拼接全历史会造成上下文窗口与成本问题;如何在不打断用户体验下压缩历史并保持任务性能。

Litmus (Re)Agent: A Benchmark and Agentic System for Predictive Evaluation of Multilingual Models
在缺少目标语言/任务直接评测结果时,如何预测多语模型在目标语言任务上的表现(predictive multilingual evaluation)。

CONDESION-BENCH: Conditional Decision-Making of Large Language Models in Compositional Action Space
评测LLM在“可组合动作空间”且存在显式可行性约束条件下的条件决策能力,弥补传统从有限候选动作中选择的基准设定不足。

Task-Aware LLM Routing with Multi-Level Task-Profile-Guided Data Synthesis for Cold-Start Scenarios
在缺少目标域训练数据的冷启动场景下,实现对不同任务/查询的LLM路由(在成本-效果之间做选择)并保持泛化能力。

在真实Agent环境中指令来源多且权限层级复杂,固定少数层级的Instruction Hierarchy无法覆盖多源冲突,导致安全与有效性下降;需要可扩展到任意多权限层级的冲突解析能力与评测。

如何对LLM多智能体系统(MAS)在多轮交互/多路径通信下的整体推理轨迹不确定性进行可分解、可量化的评估。

现有空间推理/导航类评测多为一次性输出,难以反映交互式决策与回退;本文提出交互式环境评测以量化“空间推理到行动(acting)”的能力差距。

如何在通用Agent执行“会改变外部世界状态”的动作(state mutation)时,从架构层面提供可验证、可约束、可审计的安全治理,而不是仅靠API调用后的被动过滤。

现有LLM agent多停留在“单回合/单任务”评测,难以衡量跨任务持续学习、工具/策略自我演化与长期效率稳定性。

如何系统评测“深度研究型agent”在真实链路中同时完成网页/知识检索与多步计算(entity识别→属性检索→数学/程序计算)的能力,而不是把检索与计算割裂评测。

如何在不同量子编程框架之间统一评测LLM的量子代码生成能力,从而区分“量子推理能力”与“框架熟悉度”。

如何让前沿LLM以多智能体方式在计算密集型优化任务中端到端自动完成“读数据-设指标-写代码-跑大规模实验-总结报告”的完整研究闭环。

如何攻击多Agent/编排式LLM系统:用一次“合法表述”的请求诱导编排器拆解出单步均合规但整体违反安全策略的子任务序列,从而绕过现有子任务级安全机制。

多智能体系统中,协作拓扑与反馈回路是否会放大而非削弱偏见,以及如何系统测量这种“偏见级联/放大”。

解决长轨迹Web Agent在有限上下文窗口下的“上下文管理策略静态、随状态变化无法自适应”导致的搜索效率与最终精度下降问题。

LLM在多轮对话(辅导、客服、咨询等)中需要长期保持角色/人格/目标一致性;但LLM–LLM自对话或角色扮演式合成数据会随轮次累积身份相关失败:persona drift(人格漂移)、role confusion(角色混淆)、echoing(逐渐模仿对方)。这会污染合成语料,削弱下游训练与评测可信度。

如何在不依赖更强监督模型或异构集成的情况下,仅通过同一LLM的角色分工交互来提升编码问题求解能力。

如何评测面向客服场景的服务型对话agent在多样用户行为下对SOP流程的严格遵循与鲁棒性,并实现可扩展、可自动化的评测。

LLM-Rosetta: A Hub-and-Spoke Intermediate Representation for Cross-Provider LLM API Translation
如何降低跨LLM供应商API格式碎片化带来的迁移成本,使应用能在多家LLM之间可移植、可互操作,而不需要O(N^2)的两两适配器。

团队如何从“提示词+人工review”的AI辅助编码,系统性演进到具备持续反馈闭环、可自我维持的AI驱动软件工程系统。
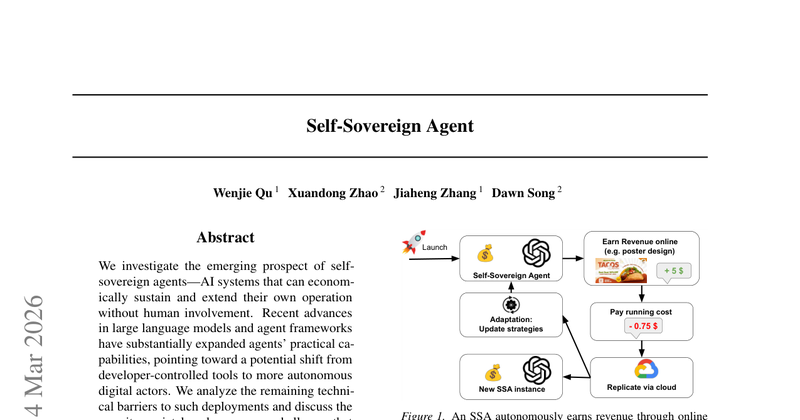
Self-Sovereign Agent
分析“自我主权智能体”(可在无人干预下经济自维持并扩展运行)的技术门槛与潜在安全/治理风险。
KV-Cache优化、量化/剪枝/蒸馏、推测解码、注意力优化、长上下文推理、模型压缩、推理系统/Serving

Cactus: Accelerating Auto-Regressive Decoding with Constrained Acceptance Speculative Sampling
在投机采样(Speculative Sampling)中,严格匹配目标模型分布会限制 Draft token 的接受率,而现有的启发式放宽方法(如 TAS)会扭曲目标分布并导致生成质量下降。