-
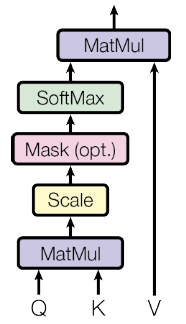
Masking Strategies for Pre-trained Language Models: From MLM to T5
A comprehensive survey of masking and denoising strategies in pre-training—BERT's MLM (static vs. dynamic), whole-word masking, SpanBERT's geometric span masking, MASS, BART's corruption zoo, and T5's sentinel-based span corruption.
-
Subword Tokenization in NLP: BPE, WordPiece, and Unigram
A comprehensive guide to subword tokenization—BPE, Byte-level BPE, WordPiece, and Unigram LM—with algorithms, implementations (GPT-2, tiktoken, BERT, SentencePiece), and empirical comparisons.

-
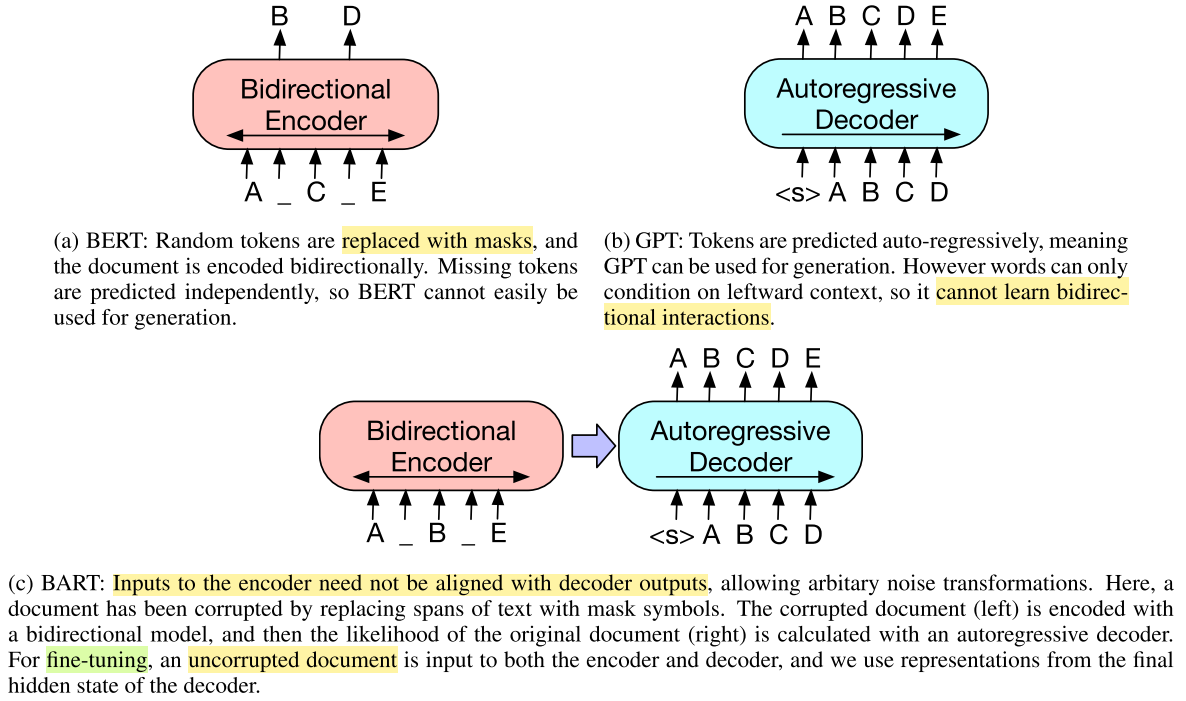
BERTology: From XLNet to ELECTRA
A technical deep-dive into BERT-era pre-training innovations—XLNet's permutation LM, two-stream attention, RoBERTa's training recipe, SpanBERT's boundary objective, ALBERT's parameter efficiency, and ELECTRA's replaced token detection.
-
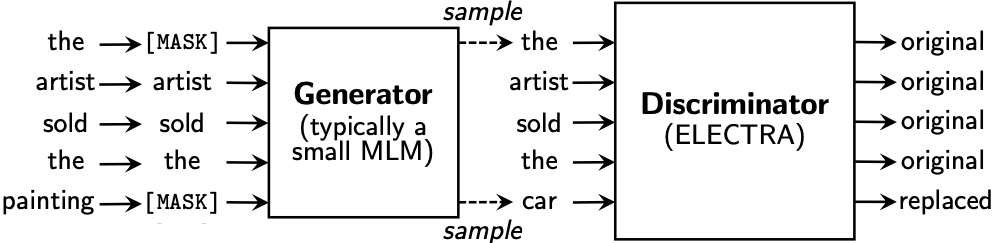
Normalization in Neural Networks: BN, LN, RMSNorm, and Beyond
From Batch Normalization to RMSNorm—a systematic comparison of normalization techniques (BN, LN, IN, GN, SN) with formulations, implementations, and practical guidance for modern deep learning.
-
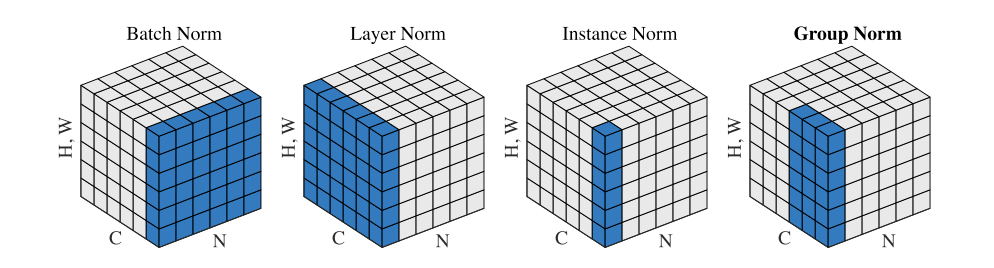
Attention Mechanisms and the Transformer Architecture
From seq2seq bottlenecks to self-attention—a systematic walkthrough of additive attention, scaled dot-product attention, multi-head attention, the Transformer encoder-decoder, positional encoding, and relative position representations, with complete PyTorch implementations.