-
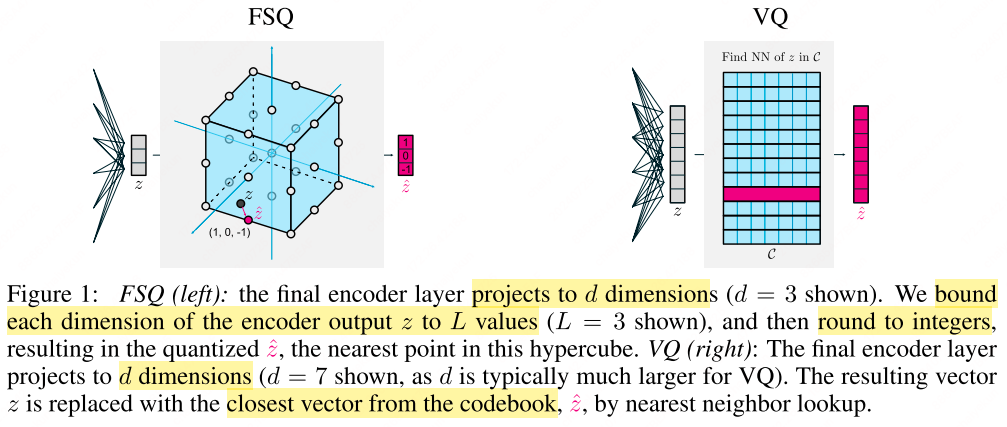
Multimodal Tokenization with Vector Quantization: A Review
From VQ-VAE to lookup-free quantization—a systematic review of codebook learning, residual/hierarchical quantization, and generation architectures for multimodal tokenization.
-
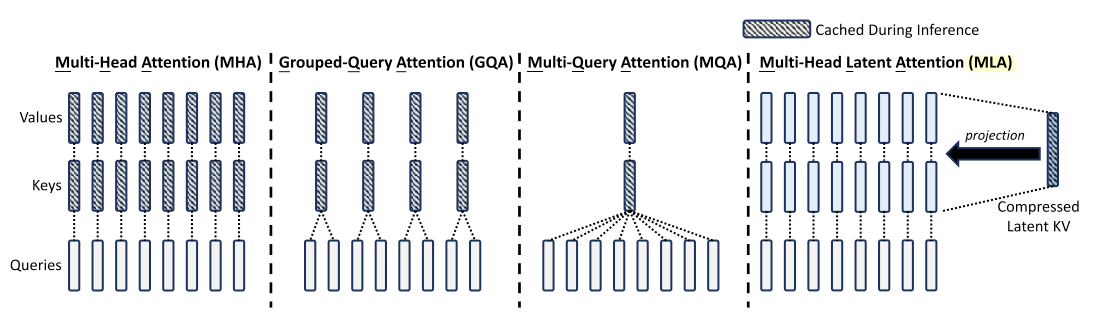
Memory-Efficient Attention: MHA vs. MQA vs. GQA vs. MLA
Efficient attention variants (MHA, MQA, GQA, MLA)—memory, speed, and expressivity trade-offs for scaling transformers.
-
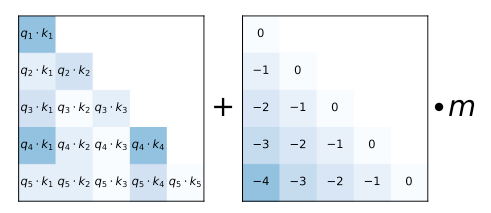
Positional Encoding in Transformers: From Sinusoidal to RoPE
A survey of positional encoding in transformers—sinusoidal PE, RoPE, T5 bias, ALiBi, KERPLE, xPos, Sandwich, interpolation, and NTK-scaled RoPE—with implementations and references.
-
Diffusion Models: A Mathematical Guide from Scratch
A mathematical walkthrough of Gaussian and categorical diffusion—from forward noise, reverse denoising, and ELBO to classifier guidance and discrete D3PM.

-
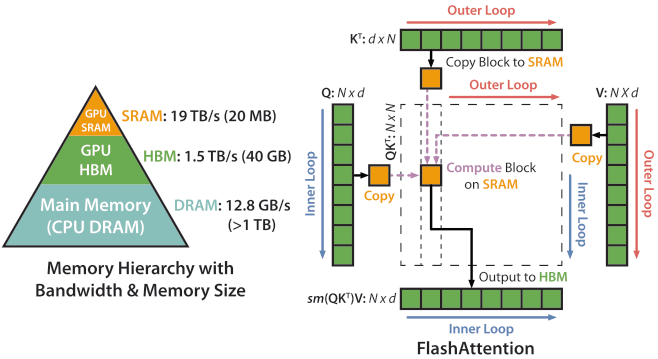
Efficient Distributed Training: From DP to ZeRO and FlashAttention
A practical guide to distributed training—data/tensor/pipeline/sequence parallelism, ZeRO, FSDP, mixed precision, and FlashAttention—with formulations and implementations.