Subword Tokenization in NLP: BPE, WordPiece, and Unigram
Tokenization is the unsung foundation of every language model. The choice of tokenizer dictates vocabulary size, sequence length, and—perhaps surprisingly—downstream task performance. Word-level tokenization suffers from large vocabularies and the OOV problem; character-level tokenization yields manageable vocabularies but loses semantic granularity and produces prohibitively long sequences. Subword tokenization strikes a middle ground: frequently used words remain intact while rare words are decomposed into meaningful fragments.
Three dominant algorithms power modern tokenizers: BPE (frequency-based bottom-up merging, used by GPT-2/3/4, RoBERTa, BART), WordPiece (likelihood-based merging, used by BERT, ELECTRA), and Unigram LM (top-down pruning via EM, used by XLNet, ALBERT, T5 with SentencePiece). This post covers the theory, algorithms, and production implementations of each, along with Byte-level BPE, SentencePiece, tiktoken, and an empirical comparison of Unigram vs. BPE.
Preliminaries
| Tokenization | Methods | Pros | Cons |
|---|---|---|---|
| Word-based | Space/punctuation splitting; rule-based | Easy to use | Large vocab; OOV; loses morphological similarity |
| Char-based | Split into characters | Small vocab; mostly open-vocabulary | Very long sequences; less meaningful tokens |
| Subword-based | WordPiece, BPE, Unigram | Balanced vocab/length; captures morphology; identifies word boundaries | Requires training a tokenizer |
Why subword?
- Frequent words should not be split into smaller pieces.
- Rare words should be decomposed into meaningful subwords.
- Subwords capture shared prefixes/suffixes (e.g., “un-“, “-ing”), helping models generalize across morphological variants.
Model Tokenizer Summary
| Model | Tokenization | Vocab Size | Corpus | Org |
|---|---|---|---|---|
| GPT | BPE (Spacy/ftfy) | 40,478 | BooksCorpus | OpenAI |
| GPT-2 | BBPE | 50,257 | WebText (40GB) | OpenAI |
| GPT-3 | BBPE | 50,257 | CommonCrawl, WebText2, Books, Wiki | OpenAI |
| GPT-4 | BBPE | 100,256 | Public + third-party data | OpenAI |
| GPT-4o | BBPE | 200k | — | OpenAI |
| Gemini | BPE | 256k | Large training corpus sample | |
| BERT | WordPiece | 30k | BooksCorpus, enwiki | |
| T5 | WordPiece (spm) | 32k | C4 | |
| XLNet | Unigram (spm) | 32k | BooksCorpus, enwiki, Giga5, ClueWeb, CC | |
| ALBERT | Unigram (spm) | 30k | BooksCorpus, enwiki | |
| PaLM | Unigram (spm) | 256k | LamDA + GLaM + code | |
| Llama | BPE (spm) | 32k | CC, C4, GitHub, Wiki, Books, ArXiv, SE | Meta |
| Llama 2 | BPE (spm) | 32k | Same tokenizer as Llama 1 | Meta |
| Llama 3 | BBPE (tiktoken) | 128k | Extended from GPT-4’s cl100k with 28k non-English | Meta |
| Gemma / Gemma 2 | BPE (spm) | 256k | Same as Gemini |
TL;DR
| Algorithm | Strategy | Merge Rule | Direction |
|---|---|---|---|
| WordPiece | Probability-based | Bigram likelihood (mutual information) | Bottom-up merge ↑ |
| BPE | Frequency-based | Bigram frequency (greedy, deterministic) | Bottom-up merge ↑ |
| Unigram LM | Subword regularization | Unigram LM perplexity (EM) | Top-down prune ↓ |
- WordPiece selects the subword pair that maximizes the training data likelihood (equivalently, mutual information).
- BPE greedily merges the most frequent adjacent pair. It is deterministic and cannot generate multiple segmentations with probabilities.
- Unigram starts with a large vocabulary and iteratively prunes tokens whose removal least increases the unigram LM loss, using the EM algorithm. It naturally supports stochastic segmentation (subword regularization).
Byte-Pair Encoding (BPE)
BPE1 first applies a pre-tokenizer (space/punctuation/rule-based splitting), then builds a base vocabulary from all characters in the training data and iteratively merges the most frequent adjacent pair.
Pre-tokenization options:
- Space tokenization (GPT-2, RoBERTa)
- Rule-based (Moses, XLM)
- Spacy + ftfy (GPT)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols) - 1):
pairs[symbols[i], symbols[i + 1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2,
'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
for i in range(10):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(f"Merge {i+1}: {best} -> {vocab}")
Byte-Level BPE (BBPE)
Unicode covers 130k+ code points, inflating the base vocabulary. GPT-22 instead operates on the byte sequence of text—a base vocabulary of just 256 byte values. This eliminates OOV entirely while keeping vocabulary size moderate.
| Level | Base Vocab | Max Seq Length | OOV |
|---|---|---|---|
| Unicode BPE | 13k+ | $L$ | Yes |
| Byte-level BPE | 256 | $\leq 4L$ | No |
A key design choice: GPT-2 prevents BPE from merging across character categories (except spaces), avoiding degenerate tokens like “-ing.” or “-ing!”.
Vocabulary size = base vocab + number of merges:
- GPT (char BPE): 478 base + 40k merges = 40,478
- GPT-2 (byte BPE): 256 base + 1 EOS + 50k merges = 50,257

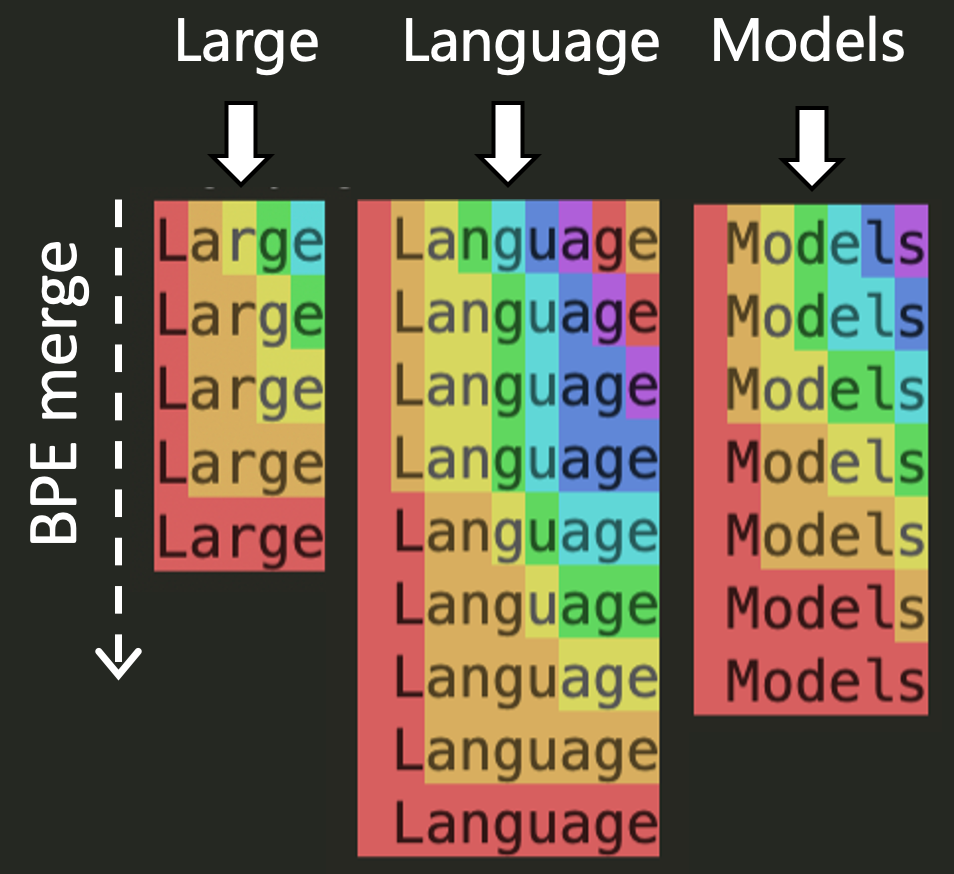
GPT-2 Encoder Implementation
The core BPE encoder used by GPT-2 and RoBERTa. The bytes_to_unicode mapping avoids whitespace/control character issues in the BPE vocabulary:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
import json
from functools import lru_cache
@lru_cache()
def bytes_to_unicode():
bs = (list(range(ord("!"), ord("~") + 1))
+ list(range(ord("¡"), ord("¬") + 1))
+ list(range(ord("®"), ord("ÿ") + 1)))
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class Encoder:
def __init__(self, encoder, bpe_merges, errors="replace"):
self.encoder = encoder
self.decoder = {v: k for k, v in self.encoder.items()}
self.errors = errors
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
import regex as re
self.pat = re.compile(
r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
pairs = get_pairs(word)
if not pairs:
return token
while True:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
new_word.extend(word[i:j])
i = j
except ValueError:
new_word.extend(word[i:])
break
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = " ".join(word)
self.cache[token] = word
return word
def encode(self, text):
bpe_tokens = []
for token in self.re.findall(self.pat, text):
token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
bpe_tokens.extend(
self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" "))
return bpe_tokens
def decode(self, tokens):
text = "".join([self.decoder.get(token, token) for token in tokens])
text = bytearray([self.byte_decoder[c] for c in text]).decode("utf-8", errors=self.errors)
return text
WordPiece
WordPiece34 is a likelihood-based BPE variant. Instead of merging the most frequent pair, WordPiece selects the pair that maximizes the likelihood of the training data—equivalently, the pair with the highest mutual information score.
BERT applies a two-stage tokenization pipeline:
- BasicTokenizer: Unicode conversion → whitespace/punctuation splitting → lowercasing → accent stripping. CJK characters are isolated into individual tokens.
- WordpieceTokenizer: Greedy longest-match-first algorithm against the learned vocabulary. Continuation tokens are prefixed with
##.

All Chinese characters are split into individual tokens regardless of WordPiece vocabulary, as CJK text is not whitespace-delimited.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class WordpieceTokenizer:
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
def tokenize(self, text):
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
Unigram Language Model
Unigram LM5 takes the opposite direction: it initializes with a large vocabulary and iteratively prunes the tokens whose removal causes the smallest increase in training loss. Token probabilities are computed via EM.

Since Unigram is not based on deterministic merge rules, it can produce multiple valid segmentations with associated probabilities—enabling subword regularization for data augmentation during training.
Given all possible tokenizations \(S(x_i)\) for word \(x_i\), the training objective minimizes:
\[\mathcal{L} = - \sum_{i=1}^N \log \left( \sum_{x \in S(x_i)} p(x) \right)\]The Viterbi forward-backward algorithm efficiently finds the most likely segmentation, while the EM algorithm iterates between re-estimating token probabilities (E-step) and finding optimal segmentations (M-step).
SentencePiece
SentencePiece6 is a language-independent, whitespace-agnostic tokenizer library that treats the input as a raw byte stream and includes whitespace in the vocabulary (as ▁). It supports both BPE and Unigram modes (Unigram by default). Used by XLNet, T5, ALBERT, Llama, and Gemma.
Key advantages:
- Fast C++ implementation with Python/protobuf bindings.
- Whitespace-agnostic: handles CJK and non-space-delimited languages seamlessly.
- Byte-level fallback: can decompose unknown characters into UTF-8 byte pieces.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import sentencepiece as spm
spm.SentencePieceTrainer.train(
'--input=data.txt --model_prefix=m --vocab_size=32000')
sp = spm.SentencePieceProcessor()
sp.load('m.model')
print(sp.encode_as_pieces('This is a test'))
print(sp.encode_as_ids('This is a test'))
print(sp.decode_pieces(['▁This', '▁is', '▁a', '▁t', 'est']))
# Subword regularization (Unigram only)
for _ in range(5):
print(sp.encode('hello world', out_type=str,
enable_sampling=True, alpha=0.1, nbest_size=-1))
OpenAI tiktoken
tiktoken is OpenAI’s fast BPE tokenizer implementation in Rust with Python bindings. It powers GPT-3.5-turbo, GPT-4, and newer models.
1
2
3
4
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
tokens = enc.encode("tiktoken tokenizer")
text = enc.decode(tokens)
| Models | Encoding | Vocab Size |
|---|---|---|
| GPT-2 | gpt2 | 50,257 |
| GPT-3 (davinci, etc.) | r50k_base | 50,257 |
| text-davinci-002/003 | p50k_base | 50,281 |
| GPT-3.5-turbo, GPT-4 | cl100k_base | 100,256 |
Empirical Analysis: Unigram vs. BPE
Bostrom and Durrett7 found that Unigram LM tokenization aligns better with morphology than character-based BPE. Unigram tends to produce longer subword units with more moderate frequency distributions, while BPE greedily merges common tokens into neighbors even when the result is not semantically meaningful.
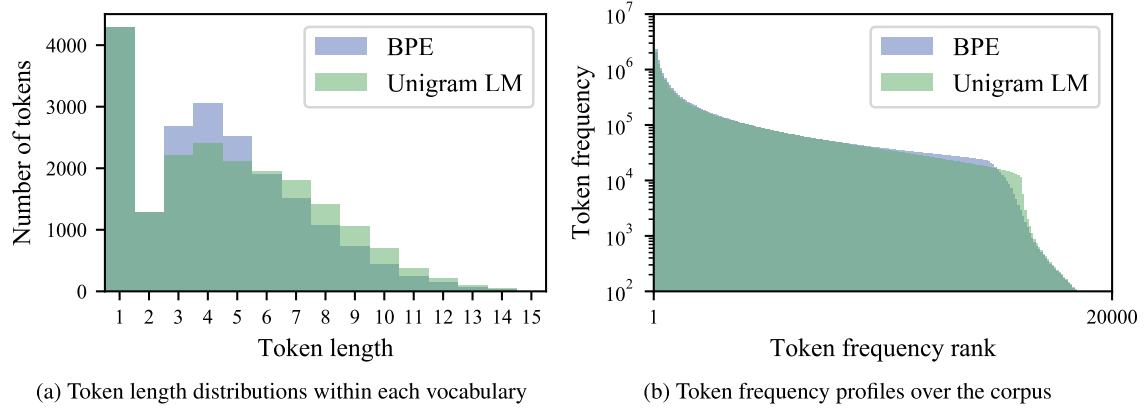

Segmentation boundaries produced by Unigram more closely match morphological references in both English and Japanese:
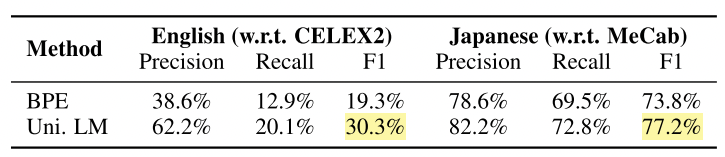
Furthermore, fine-tuning models pre-trained with Unigram outperforms BPE on the evaluated downstream tasks:

References
-
Sennrich, R., Haddow, B. and Birch, A. Neural Machine Translation of Rare Words with Subword Units. ACL 2016. ↩
-
Radford, A., et al. Language Models Are Unsupervised Multitask Learners. OpenAI Blog, 2019. ↩
-
Schuster, M. and Nakajima, K. Japanese and Korean Voice Search. ICASSP 2012. ↩
-
Wu, Y., et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv:1609.08144, 2016. ↩
-
Kudo, T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. ACL 2018. ↩
-
Kudo, T. and Richardson, J. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. EMNLP 2018. ↩
-
Bostrom, K. and Durrett, G. Byte Pair Encoding Is Suboptimal for Language Model Pretraining. Findings of EMNLP 2020. ↩
Related Posts