Masking Strategies for Pre-trained Language Models: From MLM to T5
The masking strategy is arguably the single most important design choice in denoising pre-training. BERT’s original 80/10/10 random token masking was a breakthrough, but the field quickly discovered that what you mask matters as much as how you predict it. Whole-word masking prevents partial subword leakage; span masking (SpanBERT) yields better representations for extraction tasks; MASS and BART explore sequence-to-sequence denoising; and T5 streamlines everything with sentinel-based span corruption that shortens targets and speeds up training.
This post walks through the major masking strategies chronologically—from BERT’s MLM through SpanBERT, MASS, BART, and T5—with formulations, reference implementations, and empirical comparisons. Understanding these strategies is essential for anyone designing pre-training objectives, whether for NLU, NLG, or the increasingly popular encoder-decoder architectures.
BERT / RoBERTa: Random Token Masking
BERT1 applies Masked Language Modeling (MLM) with a uniform masking rate of 15% after WordPiece tokenization. Masked tokens are replaced with:
-
[MASK]80% of the time, - A random word 10% of the time,
- The original word 10% of the time (to bias representations toward the actual observed word).
Since random replacement only affects 1.5% of all tokens (10% of 15%), it does not harm the model’s language understanding.
Static vs. Dynamic Masking: BERT generates masks once ahead of time (static masking); RoBERTa applies masks on-the-fly during training (dynamic masking), exposing the model to different masking patterns across epochs.
Core Implementation (Google BERT)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
MaskedLmInstance = collections.namedtuple("MaskedLmInstance", ["index", "label"])
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
# Whole Word Masking: group WordPiece continuations (##-prefixed)
if (FLAGS.do_whole_word_mask and len(cand_indexes) >= 1
and token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index_set in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
if len(masked_lms) + len(index_set) > num_to_predict:
continue
is_any_index_covered = False
for index in index_set:
if index in covered_indexes:
is_any_index_covered = True
break
if is_any_index_covered:
continue
for index in index_set:
covered_indexes.add(index)
masked_token = None
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
if rng.random() < 0.5:
masked_token = tokens[index]
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
masked_lms = sorted(masked_lms, key=lambda x: x.index)
return (output_tokens,
[p.index for p in masked_lms],
[p.label for p in masked_lms])
PyTorch MLM Masking (HuggingFace)
The core torch_mask_tokens method implements the 80/10/10 schedule:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def torch_mask_tokens(self, inputs, special_tokens_mask=None):
labels = inputs.clone()
probability_matrix = torch.full(labels.shape, self.mlm_probability)
if special_tokens_mask is None:
special_tokens_mask = [
self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True)
for val in labels.tolist()]
special_tokens_mask = torch.tensor(special_tokens_mask, dtype=torch.bool)
probability_matrix.masked_fill_(special_tokens_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100
# 80%: [MASK]
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10%: random word
indices_random = (torch.bernoulli(torch.full(labels.shape, 0.5)).bool()
& masked_indices & ~indices_replaced)
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
# 10%: unchanged
return inputs, labels
Span Masking (SpanBERT)
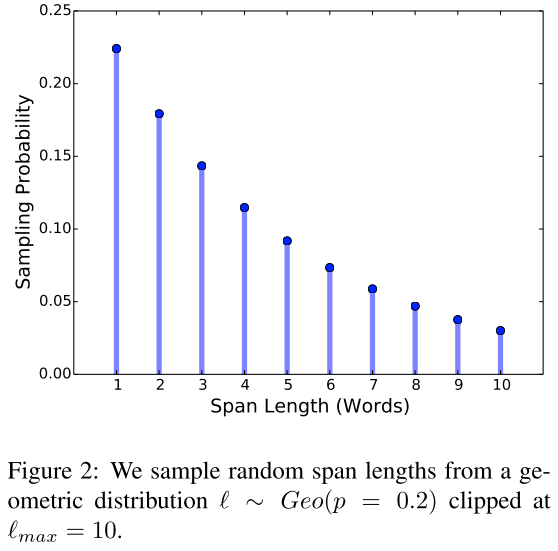
SpanBERT2 replaces BERT’s random token masking with contiguous span masking. Span lengths are sampled from a clamped geometric distribution:
\[P(\ell = k) = (1 - p)^{k-1} p, \qquad \ell = \min(\ell, 10)\]with $p = 0.2$, yielding a mean span length of $\bar{\ell} \approx 3.8$ complete words (not subword tokens). The total masking budget remains 15%, with the same 80/10/10 replacement schedule.
Related approaches:
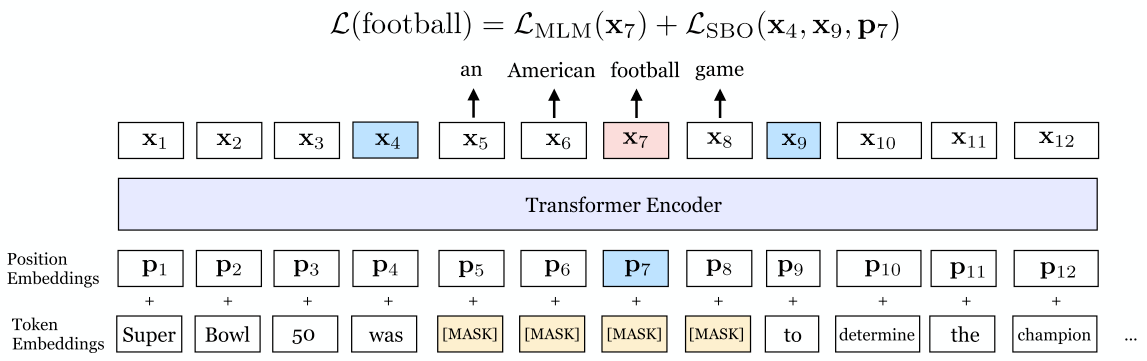
Span Boundary Objective (SBO)
In addition to MLM, SpanBERT introduces a span boundary objective: for each masked span \((x_s, \ldots, x_e)\), it predicts each token \(x_i\) from the boundary representations \(\mathbf{x}_{s-1}\), \(\mathbf{x}_{e+1}\) and a positional embedding \(\mathbf{p}_i\):
\[\mathbf{y}_i = f(\mathbf{x}_{s-1}, \mathbf{x}_{e+1}, \mathbf{p}_i)\]where $f(\cdot)$ is a 2-layer FFN with LayerNorm and GeLU activations.
Masking Scheme Comparison
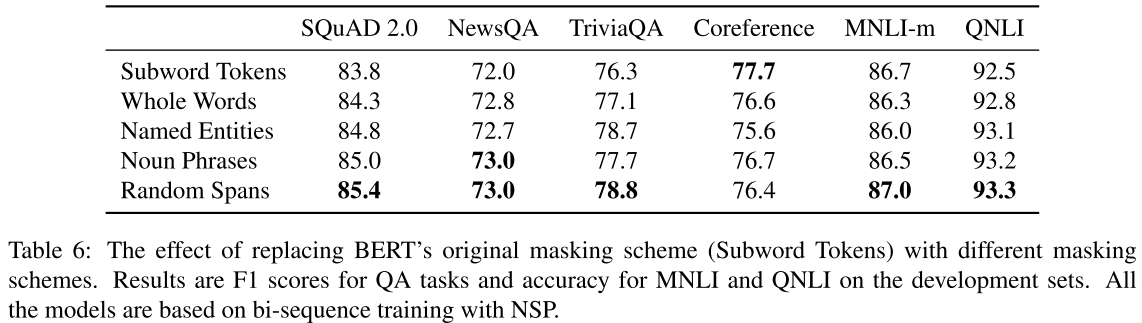
Random span masking is preferable to linguistic masking (named entities, noun phrases) for most tasks. The exception is coreference resolution, where random subword masking performs best.
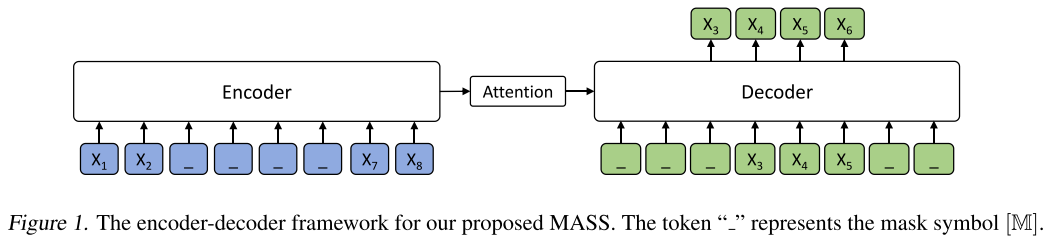
MASS: Masked Sequence-to-Sequence
MASS5 masks a contiguous span in the encoder input (replacing each token with [MASK]) while keeping the sequence length unchanged. The decoder then autoregressively predicts only the masked tokens, with the unmasked positions hidden from the decoder. This bridges the gap between encoder-only (BERT) and decoder-only (GPT) pre-training.
BART: Denoising Sequence-to-Sequence
BART6 uses a transformer encoder-decoder architecture and explores multiple corruption strategies:
- Token Masking: Same as BERT’s random masking.
- Token Deletion: Random tokens are deleted entirely (the model must determine which positions are missing).
- Text Infilling: Spans are sampled from a Poisson distribution ($\lambda = 3$) and each span is replaced with a single
[MASK]token—even 0-length spans (inserting masks). - Sentence Permutation: Sentences (split on periods) are randomly shuffled.
- Document Rotation: The document is rotated to start at a randomly chosen token.
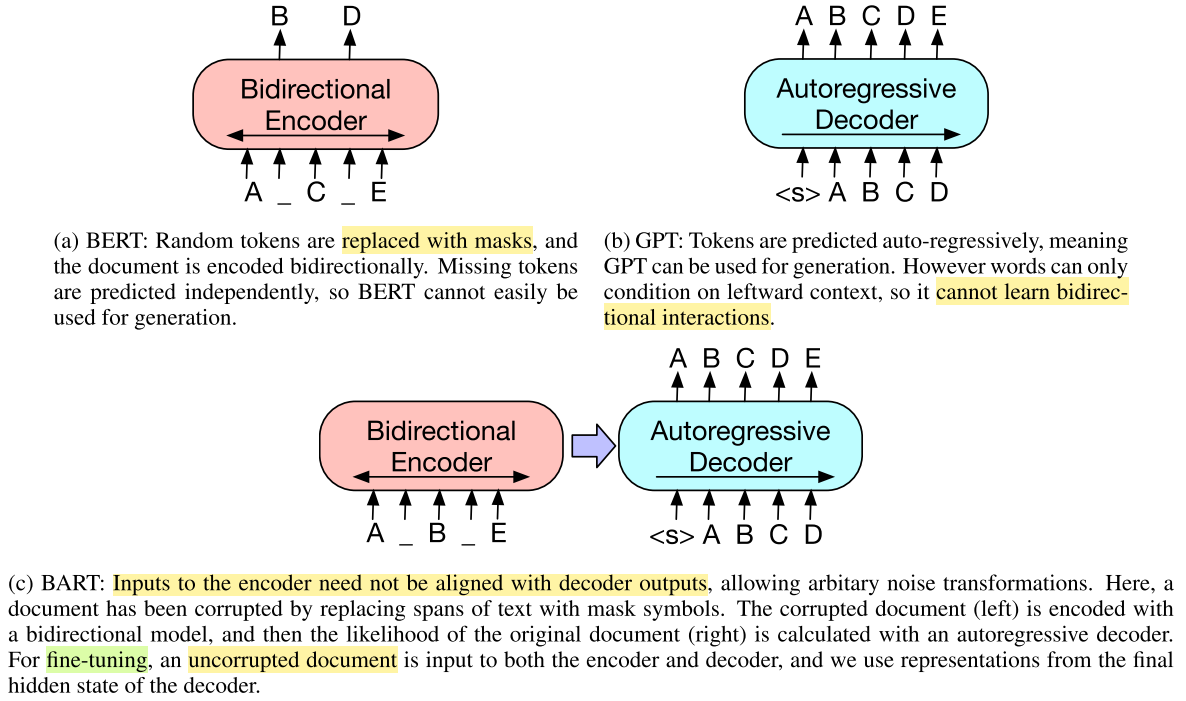
Text infilling is the most effective single strategy, as it forces the model to learn both span boundaries and content.
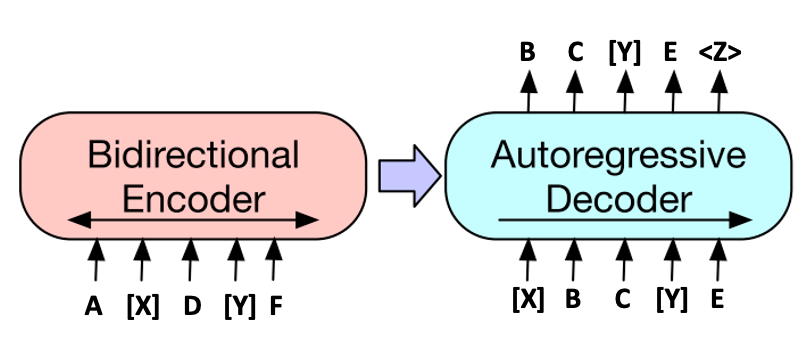
T5: Sentinel-Based Span Corruption
T57 replaces each corrupted span with a unique sentinel token (e.g., <extra_id_0>) in the encoder input. The decoder target is the concatenation of corrupted spans, each prefixed by its corresponding sentinel. This design produces much shorter targets than BERT-style or MASS-style objectives, significantly accelerating training.
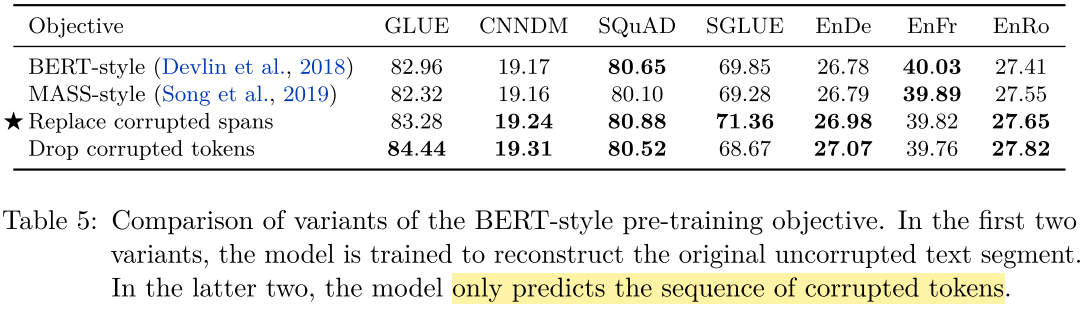
Key findings from the T5 ablation:
- The first two rows (BERT-style, MASS-style) reconstruct the full input, requiring self-attention over long decoder sequences.
- “Replace corrupted spans” (T5’s approach) and “drop corrupted tokens” both produce shorter targets.
- Dropping tokens completely yields a small CoLA improvement but hurts SuperGLUE compared to sentinel replacement.
- Sentinel-based corruption offers the best speed-accuracy trade-off.
References
-
Devlin, J., et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019. ↩
-
Joshi, M., et al. SpanBERT: Improving Pre-training by Representing and Predicting Spans. TACL 2020. ↩
-
Sun, Y., et al. ERNIE: Enhanced Representation through Knowledge Integration. arXiv:1904.09223, 2019. ↩
-
Cui, Y., et al. Pre-Training with Whole Word Masking for Chinese BERT. IEEE/ACM TASLP, 2021. ↩
-
Song, K., et al. MASS: Masked Sequence to Sequence Pre-training for Language Generation. ICML 2019. ↩
-
Lewis, M., et al. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. ACL 2020. ↩
-
Raffel, C., et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR 2020. ↩
Related Posts