BERTology: From XLNet to ELECTRA
BERT demonstrated that bidirectional pre-training yields powerful representations, but it also introduced fundamental limitations: the independence assumption between masked positions, the pre-train/fine-tune discrepancy from [MASK] tokens, and the inefficiency of learning from only 15% of tokens per sample. The subsequent “BERTology” wave addressed each of these issues systematically. XLNet combined autoregressive factorization with permutation-based bidirectionality; RoBERTa showed that BERT was simply undertrained; SpanBERT proved that span-level objectives outperform token-level ones for extraction tasks; ALBERT tackled parameter efficiency; and ELECTRA achieved sample efficiency by learning from all input tokens.
This post covers these key innovations with their formulations, architectural insights, and training strategies.
Background: AR vs. AE Pre-training
Autoregressive (AR) Language Modeling
Given a sequence \(\mathbf{x} = (x_1, \ldots, x_T)\), AR models factorize the likelihood unidirectionally:
\[p(\mathbf{x}) = \prod_{t=1}^T p(x_t \vert x_{<t})\]The pre-training objective maximizes:
\[\max_\theta \sum_{t=1}^T \log \frac{\exp\!\big(h_\theta(\mathbf{x}_{1:t-1})^\top e(x_t)\big)}{\sum_{x'} \exp\!\big(h_\theta(\mathbf{x}_{1:t-1})^\top e(x')\big)}\]where \(h_\theta(\mathbf{x}_{1:t-1})\) is the context representation and \(e(x_t)\) is the token embedding. AR models cannot efficiently capture deep bidirectional context.
Autoencoding (AE) Pre-training
BERT recovers original tokens from corrupted input. Given masked positions $\bar{\mathbf{x}}$ in $\hat{\mathbf{x}}$:
\[\max_\theta \sum_{t=1}^T m_t \log \frac{\exp\!\big(H_\theta(\hat{\mathbf{x}})_t^\top e(x_t)\big)}{\sum_{x'} \exp\!\big(H_\theta(\hat{\mathbf{x}})_t^\top e(x')\big)}\]where \(m_t = 1\) indicates a masked position. Drawbacks: (1) independence assumption—masked tokens are predicted independently, ignoring inter-mask dependencies; (2) pre-train/fine-tune discrepancy from [MASK] tokens absent during fine-tuning.
XLNet: Permutation Language Modeling
XLNet1 combines AR and AE advantages through permutation language modeling (PLM): it maximizes the expected log-likelihood over all $T!$ factorization orders:
\[\max_\theta \; \mathbb{E}_{\mathbf{z} \sim \mathcal{Z}_T} \left[\sum_{t=1}^T \log p_\theta(x_{z_t} \vert \mathbf{x}_{\mathbf{z}_{<t}})\right]\]This retains the AR objective (no independence assumption, no [MASK] tokens) while capturing bidirectional context through permutation.
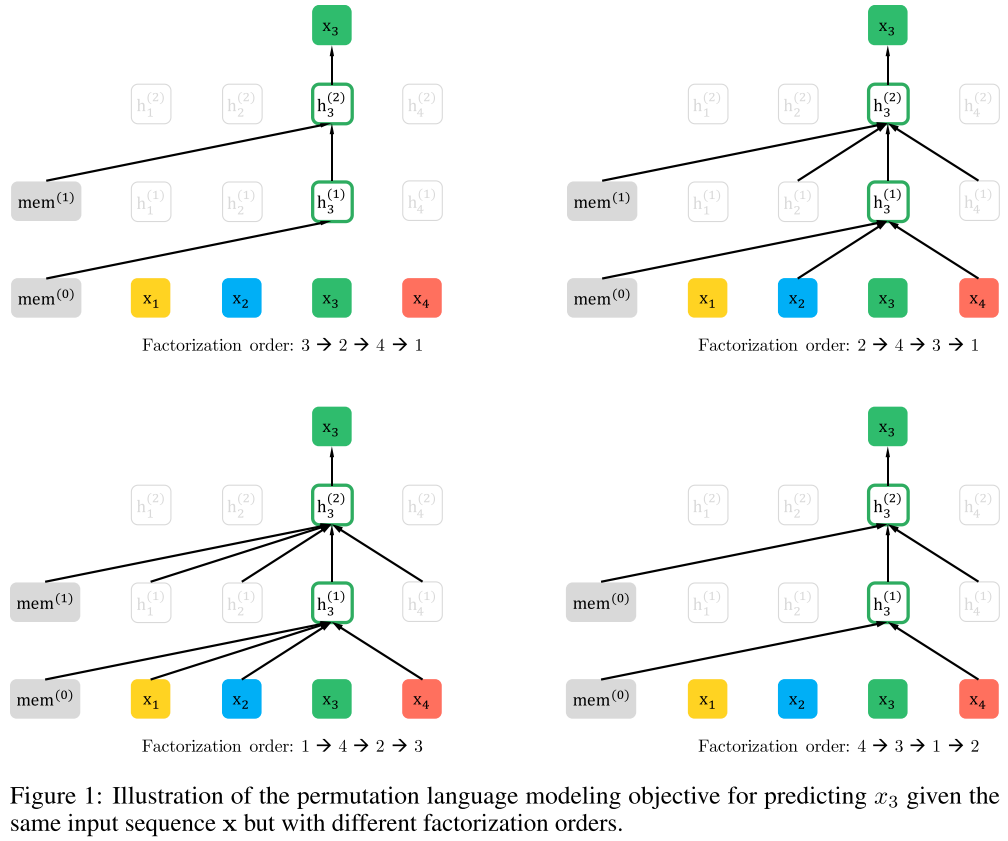
Two-Stream Self-Attention
Standard Transformer representations encode both context and the token itself, creating ambiguity for different permutation targets sharing the same prefix. XLNet resolves this with two streams:
Content stream \(h_{z_t}\) (standard self-attention—sees both position and content):
\[h_{z_t}^{(m)} \leftarrow \text{Attention}\!\big(\mathbf{Q} = h_{z_t}^{(m-1)},\; \mathbf{KV} = \mathbf{h}_{\mathbf{z}_{\leq t}}^{(m-1)}\big)\]Query stream \(g_{z_t}\) (sees position \(z_t\) but not content \(x_{z_t}\)):
\[g_{z_t}^{(m)} \leftarrow \text{Attention}\!\big(\mathbf{Q} = g_{z_t}^{(m-1)},\; \mathbf{KV} = \mathbf{h}_{\mathbf{z}_{<t}}^{(m-1)}\big)\]The prediction distribution uses the query stream:
\[p_\theta(X_{z_t} = x \vert \mathbf{x}_{\mathbf{z}_{<t}}) = \frac{\exp\!\big(e(x)^\top g_\theta(\mathbf{x}_{\mathbf{z}_{<t}}, z_t)\big)}{\sum_{x'} \exp\!\big(e(x')^\top g_\theta(\mathbf{x}_{\mathbf{z}_{<t}}, z_t)\big)}\]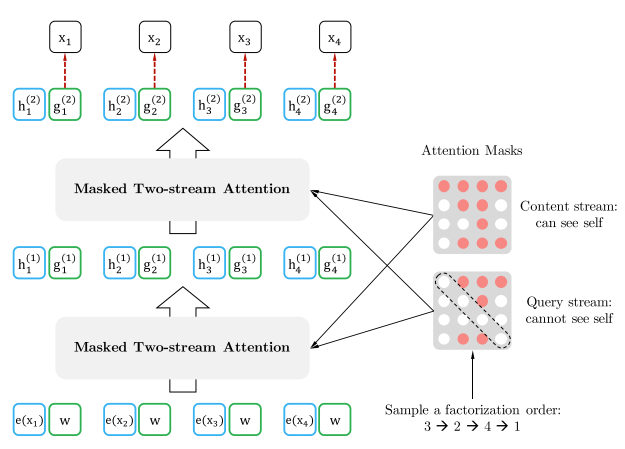
During fine-tuning, the query stream is dropped and the content stream functions as a standard Transformer(-XL). Permutation is implemented via attention masks, leaving the original sequence order unchanged.
XLNet also inherits relative positional encoding and segment recurrence from Transformer-XL2, enabling modeling of cross-segment dependencies.
RoBERTa: “BERT Is Undertrained”
RoBERTa3 showed that carefully optimizing BERT’s training recipe yields substantial gains:
- Dynamic masking (new mask each epoch) instead of static masking.
- Larger batches (8k sequences) and more data (160GB).
- Removing NSP (Next Sentence Prediction)—it provides negligible or negative benefit.
- Longer training (500k steps).
The conclusion: BERT’s architecture is sound; it was simply trained with suboptimal hyperparameters and insufficient data.
SpanBERT: Span-Level Pre-training
SpanBERT4 masks contiguous spans (geometric distribution, $p=0.2$, mean $\bar{\ell} \approx 3.8$ words) and introduces a span boundary objective (SBO): predict each masked token \(x_i\) from boundary representations \(\mathbf{x}_{s-1}\), \(\mathbf{x}_{e+1}\) and positional embedding \(\mathbf{p}_i\):
\[\begin{align} \mathbf{h} &= \text{LayerNorm}\!\big(\text{GeLU}(W_1 \cdot [\mathbf{x}_{s-1};\, \mathbf{x}_{e+1};\, \mathbf{p}_i])\big) \\ \mathbf{y}_i &= \text{LayerNorm}\!\big(\text{GeLU}(W_2 \cdot \mathbf{h})\big) \end{align}\]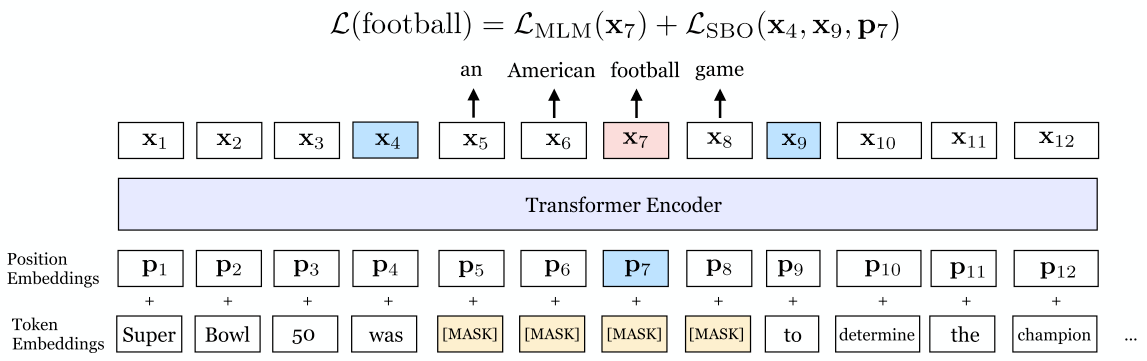
SpanBERT removes NSP entirely and consistently outperforms BERT on span-selection tasks (SQuAD, coreference resolution).
ALBERT: Parameter-Efficient BERT
ALBERT5 reduces BERT’s memory footprint through:
-
Factorized embedding parameterization: Decompose the $V \times H$ embedding matrix into $V \times E$ and $E \times H$ ($E \ll H$), reducing parameters from $O(V \times H)$ to $O(V \times E + E \times H)$.
-
Cross-layer parameter sharing: All Transformer layers share the same parameters (self-attention and FFN), reducing the parameter count by $\sim$$12\times$ for ALBERT-xxlarge vs. BERT-large.
-
Sentence-order prediction (SOP): Replace NSP with predicting whether two consecutive segments are in their natural order or swapped—a harder task that consistently improves multi-sentence understanding.
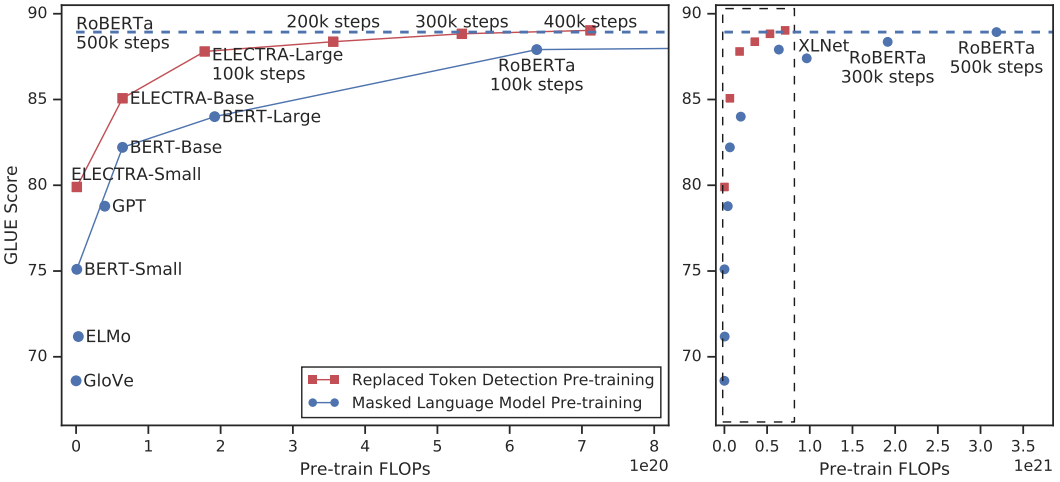
ELECTRA: Replaced Token Detection
ELECTRA6 replaces the MLM objective with replaced token detection, achieving sample efficiency by learning from all input tokens (not just the 15% that are masked).
Architecture: A small generator $G$ performs MLM to produce plausible replacements; a discriminator $D$ classifies each token as original or replaced.
\[p_G(x_t \vert \mathbf{x}) = \frac{\exp\!\big(e(x_t)^\top h_G(\mathbf{x})_t\big)}{\sum_{x'} \exp\!\big(e(x')^\top h_G(\mathbf{x})_t\big)}\] \[D(\mathbf{x}, t) = \sigma\!\big(w^\top h_D(\mathbf{x})_t\big)\]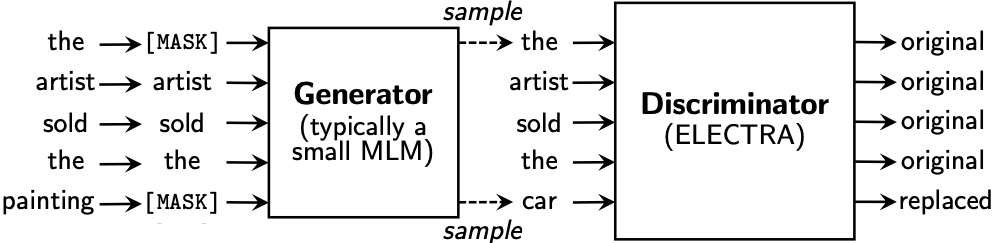
Training objective:
\[\begin{align} \mathcal{L}_\text{MLM}(\mathbf{x}, \theta_G) &= \mathbb{E}\!\left[\sum_{i \in \mathbf{m}} -\log p_G(x_i \vert \mathbf{x}^\text{masked})\right] \\ \mathcal{L}_D(\mathbf{x}, \theta_D) &= \mathbb{E}\!\left[\sum_{t=1}^n -\mathbb{1}(x_t^\text{corrupt} = x_t) \log D(\mathbf{x}^\text{corrupt}, t) - \mathbb{1}(x_t^\text{corrupt} \neq x_t) \log(1 - D(\mathbf{x}^\text{corrupt}, t))\right] \end{align}\]Combined loss: \(\min_{\theta_G, \theta_D} \mathcal{L}_\text{MLM} + \lambda \mathcal{L}_D\).
Training details: Generator and discriminator share token and position embeddings. After pre-training, the generator is discarded and only the discriminator is fine-tuned. ELECTRA-small matches GPT’s performance with 1/15th the compute.
References
-
Yang, Z., et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding. NeurIPS 2019. ↩
-
Dai, Z., et al. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. ACL 2019. ↩
-
Liu, Y., et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692, 2019. ↩
-
Joshi, M., et al. SpanBERT: Improving Pre-training by Representing and Predicting Spans. TACL 2020. ↩
-
Lan, Z., et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. ICLR 2020. ↩
-
Clark, K., et al. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. ICLR 2020. ↩
Related Posts