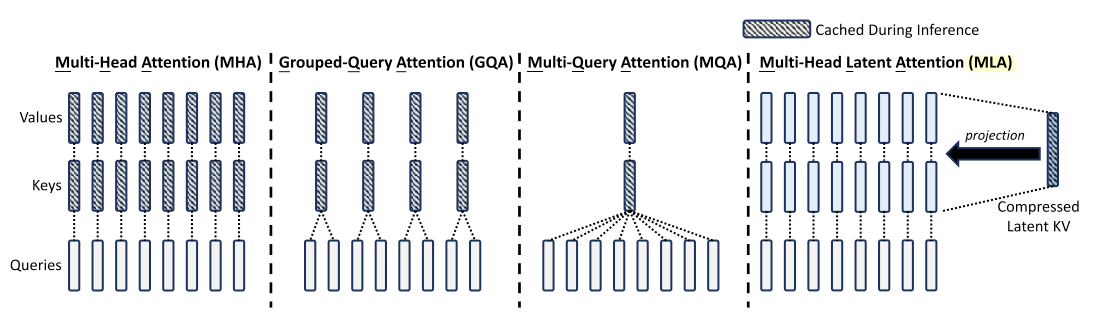
Memory-Efficient Attention: MHA vs. MQA vs. GQA vs. MLA
The KV cache is the silent bottleneck of large-language-model serving. At inference time, every decoding step must read the full key-value history for each layer and each head—memory bandwidth, not compute, becomes the wall. This is why the seemingly minor question of “how many independent KV projections do we really need?” has become one of the most impactful design axes in modern transformer architectures.
This post compares four attention variants along that axis: MHA (the original, full-expressivity baseline), MQA (a single shared KV head—radical compression, but at a quality cost), GQA (a principled interpolation that groups heads to balance cache size and expressivity), and MLA (DeepSeek-V2’s approach that compresses KV into a low-rank latent, achieving even smaller cache footprints without sacrificing multi-head diversity).
For each variant, we present the precise formulation, analyze the KV cache scaling behavior, and provide a reference PyTorch implementation. The comparison table at the end offers a quick decision guide for practitioners choosing an attention architecture for their next model.
Self-attention architecture
Multi-Head Attention (MHA)
Standard MHA1 uses independent queries, keys, and values per head.
Formulation
-
Linear Projections (Per Head)
\[Q_h = X W_h^Q, \quad K_h = X W_h^K, \quad V_h = X W_h^V, \quad h \in \{1, \dots, H\}\]where:
- \(X \in \mathbb{R}^{T \times d_{\text{model}}}\) is the input sequence,
- \(W_h^Q, W_h^K, W_h^V \in \mathbb{R}^{d_{\text{model}} \times d_k}\) are head-specific projections.
-
Scaled Dot-Product Attention (Per Head)
\[\text{head}_h = \text{softmax} \left(\frac{Q_h K_h^T}{\sqrt{d_k}}\right) V_h\] -
Concatenation and Output Projection \(\text{MHA}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_H) W^O\) where \(W^O \in \mathbb{R}^{H d_k \times d_{\text{model}}}\) is the output projection matrix.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
# projection x to Q,K,V
Q, K, V = self.W_q(x), self.W_k(x), self.W_v(x)
# reshape to (bsz, num_heads, seq_len, d_k)
Q, K, V = (
rearrange(Q, 'b t (h d) -> b h t d', h=self.num_heads),
rearrange(K, 'b t (h d) -> b h t d', h=self.num_heads),
rearrange(V, 'b t (h d) -> b h t d', h=self.num_heads),
)
# scaled dot-product attention
attn = torch.einsum("bhtd,bhTd->bhtT", Q,K) / self.d_k**.5
attn = F.softmax(attn, dim=-1)
output = torch.einsum('bhtT,bhTd->bhtd', attn, V)
# merge & project
output = rearrange(output, "b h t d -> b t (h d)")
return self.W_o(output)
Multi-Query Attention (MQA)
MQA2 optimizes MHA by sharing a single set of keys and values across all heads.
Formulation
-
Query Projection (Per Head)
\[Q_h = X W_h^Q, \quad h \in \{1, \dots, H\}\] -
Shared Key and Value Projections
\[K = X W^K, \quad V = X W^V\]where:
- \(W^K, W^V \in \mathbb{R}^{d_{\text{model}} \times d_k}\) are shared across all heads.
-
Attention Computation
\[\text{head}_h = \text{softmax} \left(\frac{Q_h K^T}{\sqrt{d_k}}\right) V\] -
Concatenation and Output Projection \(\text{MQA}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_H) W^O\)
Key Difference from MHA: All heads share the same $K$ and $V$, reducing KV cache from $O(H)$ to $O(1)$ per layer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class MultiQueryAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_k, bias=False) # shared K
self.W_v = nn.Linear(d_model, d_k, bias=False) # shared V
self.W_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
Q = self.W_q(x)
K, V = self.W_k(x), self.W_v(x)
Q = rearrange(Q, 'b t (h d) -> b h t d', h=self.num_heads)
# scaled dot-product attention
attn = torch.einsum("bhtd,bTd->bhtT", Q,K) / self.d_k**.5
attn = F.softmax(attn, dim=-1)
output = torch.einsum('bhtT,bTd->bhtd', attn, V)
# merge & project
output = rearrange(output, "b h t d -> b t (h d)")
return self.W_o(output)
Grouped-Query Attention (GQA)
GQA3 interpolates between MHA and MQA: queries are divided into groups, each sharing its own key-value projections.
Formulation
-
Query Projection (Per Head)
\[Q_h = X W_h^Q, \quad h \in \{1, \dots, H\}\] -
Grouped Key-Value Projections
- Queries are divided into $G$ groups ($G < H$), each group sharing its own key-value pair: \(K_g = X W_g^K, \quad V_g = X W_g^V, \quad g \in \{1, \dots, G\}\) where \(W_g^K, W_g^V \in \mathbb{R}^{d_{\text{model}} \times d_k}\).
-
Attention Computation (Per Group)
\[\text{head}_h = \text{softmax} \left(\frac{Q_h K_g^T}{\sqrt{d_k}}\right) V_g, \quad \text{where } h \text{ belongs to group } g.\] -
Concatenation and Output Projection \(\text{GQA}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_H) W^O\)
Key Difference from MQA: Each group of heads retains its own key-value pair, offering better expressivity than fully shared MQA while still reducing cache by a factor of $H/G$.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, num_heads, num_groups):
super().__init__()
assert d_model % num_heads == 0
assert num_heads % num_groups == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.num_groups = num_groups
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
# projection x to Q,K,V
Q, K, V = self.W_q(x), self.W_k(x), self.W_v(x)
# reshape Q into heads, K/V into groups
Q = rearrange(Q, 'b t (h d) -> b h t d', h=self.num_heads)
K = rearrange(K, 'b t (g d) -> b g t d', g=self.num_groups)
V = rearrange(V, 'b t (g d) -> b g t d', g=self.num_groups)
# assign each head to a group
group_idx = self.num_heads // self.num_groups
K = K.repeat_interleave(group_idx, dim=1)
V = V.repeat_interleave(group_idx, dim=1)
# scaled dot-product
attn = torch.einsum("bhtd,bhTd->bhtT", Q,K) / self.d_k**.5
attn = F.softmax(attn, dim=-1)
output = torch.einsum('bhtT,bhTd->bhtd', attn, V)
# merge & project
output = rearrange(output, "b h t d -> b t (h d)")
return self.W_o(output)
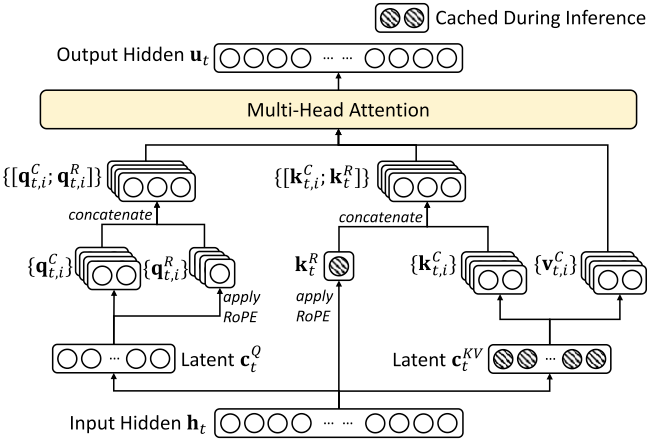
Multi-Head Latent Attention (MLA)
MLA4 compresses queries, keys, and values into low-rank latent representations, significantly reducing KV cache size and activation memory. For clarity, we omit the RoPE branch.
Formulation
-
Latent Compression for Keys and Values
\[C_t^{KV} = X W^{DKV}, \quad C_t^{KV} \in \mathbb{R}^{T \times d_c}\]where \(d_c \ll d_{\text{model}}\) is the compressed KV dimension.
-
Key-Value Reconstruction
\[K_t = C_t^{KV} W^{UK}, \quad V_t = C_t^{KV} W^{UV}\]where \(W^{UK}, W^{UV} \in \mathbb{R}^{d_c \times d_k}\) are up-projection matrices.
-
Latent Compression for Queries
\[C_t^Q = X W^{DQ}, \quad C_t^Q \in \mathbb{R}^{T \times d_c'}\]where \(d_c' \ll d_{\text{model}}\) is the compressed query dimension.
-
Query Reconstruction
\[Q_t = C_t^Q W^{UQ}\]where \(W^{UQ} \in \mathbb{R}^{d_c' \times d_k}\) is an up-projection matrix.
-
Attention Computation
\[\text{head}_h = \text{softmax} \left(\frac{Q_t K_t^T}{\sqrt{d_k}}\right) V_t\] -
Concatenation and Output Projection \(\text{MLA}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_H) W^O\)
Key Difference: MLA stores only the compressed latent \(C_t^{KV}\) in the KV cache instead of full-dimensional $K$ and $V$, reducing the per-token cache from \(O(H d_k)\) to \(O(d_c)\) while preserving multi-head diversity through up-projection.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# RoPE position embeddings are omitted for clarity.
class MultiHeadLatentAttention(nn.Module):
def __init__(self, d_model, num_heads, d_c, d_c1):
"""
Args:
d_c (int): compression dimension for K/V.
d_c1 (int): compression dimension for Q.
"""
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
assert d_c < d_model and d_c1 < d_model
self.d_c = d_c
self.d_c1 = d_c1
self.W_dkv = nn.Linear(d_model, d_c, bias=False)
self.W_dq = nn.Linear(d_model, d_c1, bias=False)
self.W_uk = nn.Linear(d_c, d_model, bias=False)
self.W_uv = nn.Linear(d_c, d_model, bias=False)
self.W_uq = nn.Linear(d_c1, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
C_kv = self.W_dkv(x)
C_q = self.W_dq(x)
Q = self.W_uq(C_q)
K = self.W_uk(C_kv)
V = self.W_uv(C_kv)
Q = rearrange(Q, 'b t (h d) -> b h t d', h=self.num_heads)
K = rearrange(K, 'b t (h d) -> b h t d', h=self.num_heads)
V = rearrange(V, 'b t (h d) -> b h t d', h=self.num_heads)
attn = torch.einsum('bhtd,bhTd->bhtT', Q, K) / self.d_k ** .5
attn = F.softmax(attn, dim=-1)
output = torch.einsum('bhtT,bhTd->bhtd', attn, V)
output = rearrange(output, 'b h t d -> b t (h d)')
return self.W_o(output)
Comparison
| Attention Type | Query | Key | Value | KV Cache | Expressivity |
|---|---|---|---|---|---|
| MHA (Multi-Head) | Per Head \(Q_h\) | Per Head \(K_h\) | Per Head \(V_h\) | High | High |
| MQA (Multi-Query) | Per Head \(Q_h\) | Single \(K\) | Single \(V\) | Low | Low |
| GQA (Grouped-Query) | Per Head \(Q_h\) | Per Group \(K_g\) | Per Group \(V_g\) | Medium | Medium |
| MLA (Multi-Head Latent) | Compressed \(C_t^Q\) | Compressed \(C_t^{KV}\) | Compressed \(C_t^{KV}\) | Very Low | Moderate |
References
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30. ↩
-
Shazeer, Noam. “Fast transformer decoding: One write-head is all you need.” arXiv preprint arXiv:1911.02150 (2019). ↩
-
Ainslie, Joshua, et al. “Gqa: Training generalized multi-query transformer models from multi-head checkpoints.” arXiv preprint arXiv:2305.13245 (2023). ↩
-
Liu, Aixin, et al. “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.” arXiv preprint arXiv:2405.04434 (2024). ↩
Related Posts