
Efficient attention mechanisms are crucial for scaling transformers in large-scale applications. Here we explore different attention variants of Multi-Head Attention (MHA), Multi-Query Attention (MQA), Grouped-Query Attention (GQA), and Multi-Head Latent Attention (MLA), analyzing their trade-offs in memory, speed, and expressivity, and how they enhance transformer scalability. 🚀
Self-attention architecture
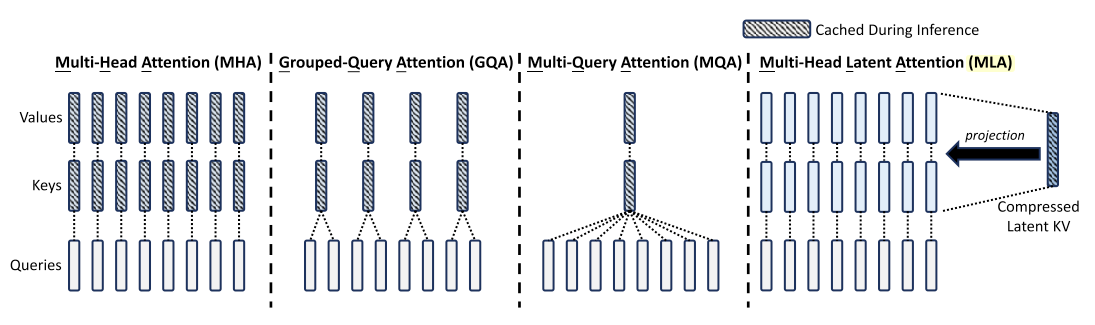
Multi-Head Attention (MHA)
Standard MHA[1] uses independent queries, keys, and values per head.
Formulation
Linear Projections (Per Head)
where:
- is the input sequence,
- are head-specific projections.
Scaled Dot-Product Attention (Per Head)
Concatenation and Output Projection
where is the output projection matrix.
1 | import torch |
Multi-Query Attention (MQA)
MQA[2] optimizes MHA by sharing keys and values across all heads.
Formulation
Query Projection (Per Head)
Shared Key and Value Projections
where:
- are shared across all heads.
Attention Computation
Concatenation and Output Projection
Key Difference from MHA: All heads share the same , reducing memory usage.
1 | class MultiQueryAttention(nn.Module): |
Grouped-Query Attention (GQA)
GQA[3] is a middle ground between MHA and MQA: queries are grouped, with each group sharing key-value projections.
Formulation
Query Projection (Per Head)
Grouped Key-Value Projections
- Queries are divided into groups (), each with its own shared key-value pair:where .
Attention Computation (Per Group)
Concatenation and Output Projection
Key Difference from MQA: Each group of heads has its own key-value pairs, offering better expressivity than fully shared MQA.
1 | class GroupedQueryAttention(nn.Module): |
Multi-Head Latent Attention (MLA)
MLA[4] compresses queries, keys, and values using low-rank projections, reducing KV cache size and activation memory. For simplicity, we omit the RoPE embeddings.
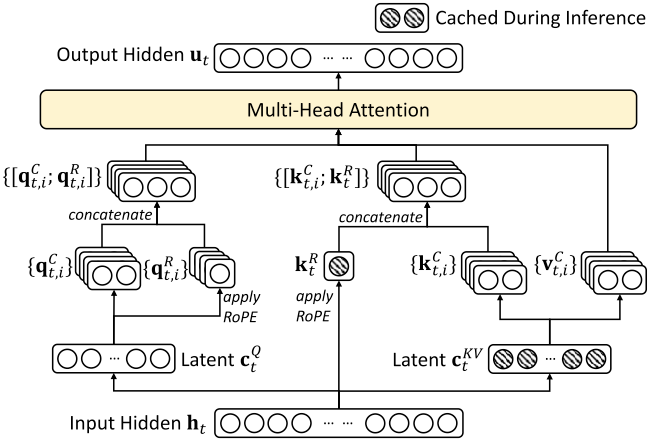
Formulation
Latent Compression for Keys and Values
where is the compressed KV dimension.
Key-Value Reconstruction
where are up-projection matrices.
Latent Compression for Queries
where is the compressed query dimension.
Query Reconstruction
where is an up-projection matrix.
Attention Computation
Concatenation and Output Projection
Key Difference: MLA stores compressed latent low-rank representations in the KV cache, reducing memory footprint while maintaining expressivity.
1 | # Here, we **omit the branch of RoPE position embeddings**. |
Comparison
| Attention Type | Query Projection | Key Projection | Value Projection | KV Cache Size | Expressivity | Use Case |
|---|---|---|---|---|---|---|
| MHA (Multi-Head) | Per Head | Per Head | Per Head | High | High | General Transformer models |
| MQA (Multi-Query) | Per Head | Single | Single | Low | Low | Large decoder models (e.g., LLMs) |
| GQA (Grouped-Query) | Per Head | Per Group | Per Group | Medium | Medium | Balanced tradeoff for large models |
| MLA (Multi-Head Latent) | Compressed | Compressed | Compressed | Very Low | Moderate | Efficient KV caching for long-sequence processing |
References
- 1.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30. ↩
- 2.Shazeer, Noam. "Fast transformer decoding: One write-head is all you need." arXiv preprint arXiv:1911.02150 (2019). ↩
- 3.Ainslie, Joshua, et al. "Gqa: Training generalized multi-query transformer models from multi-head checkpoints." arXiv preprint arXiv:2305.13245 (2023). ↩
- 4.Liu, Aixin, et al. "Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model." arXiv preprint arXiv:2405.04434 (2024). ↩