We summarize the positional encoding approaches in transformers.
Summary
PE
Relative
Trainable
Each Layer
Extrapolation
Sinusoidal
✘
✘
✘
✘
T5 bias
✔
✔
✔
✔
RoPE
✔
✔
✔
✘
ALiBi
✔
✘
✔
✔
KERPLE
✔
✔
✔
✔
Sandwich
✔
✘
✔
✔
xPos
✔
✘
✔
✔
Position Encoding
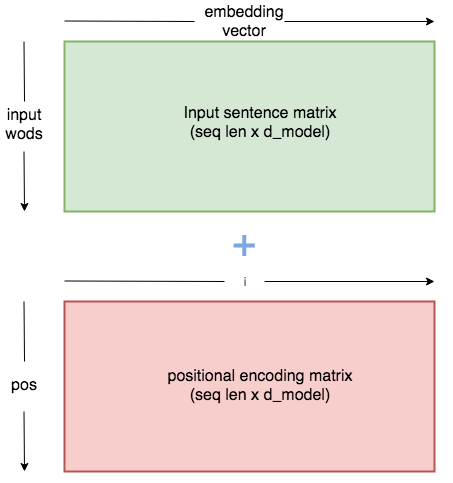
Sinusoidal Position Embeddings
Sinusoidal position embeddings[1] are constantly encoded vectors to be added on token embeddings of the first transformer layer.
where $\text{pos}$ is the position in the sentence and $i$ is the order along the embedding vector dimension. Assume this allows to learn to attend by relative positions, since for and fixed offset $k$, can be represented as the linear function of .
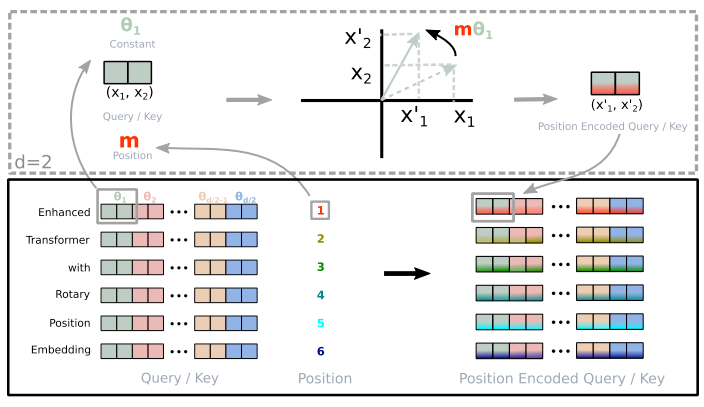
Rotary Position Embedding (RoPE) [3][4] proposes to use complex numbers as the base field of encoding space. Instead of working in $\mathbb{R}^d$, it uses consecutive pairs of elements of the query and key vectors in $\mathbb{C}^{d/2}$ to be a single complex number.
Specifically, instead of viewing as a $d$-dimensional real vector, RoPE views it as . If $d$ is odd, RoPE pads it with a dummy coordinate to ensure things line up correctly. Alternatives, it simply increases $d$ by one.
Derivation
The complex number format of RoPE is written as:
Here, $m$ indicates the $m$-th position of the sequence.
It is convenient to convert into matrix equation:
where , $\mathbf{\Theta_m}$ is the block diagonal rotation matrix, $\mathbf{W_q}$ is learned query weights, and $\mathbf{X_m}$ is the embedding of the $m$-th token.
Due to the high computation cost of sparse matrix, it is implemented as:
where $\odot$ denotes the element-wise product (*).
defprecompute_freqs_cis(dim: int, end: int, theta: float=10000,0): """ Args: dim (int): dimension of the frequency tensor. """ freqs = 1.0 / (theta ** (torch.arange(0,dim,2)[:(dim//2)].float()/dim)) t = torch.arange(end, device=freqs.device) freqs = torch.outer(t, freqs).float() freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex 64 return freqs_cis
defapply_rotary_emb(xq, xk, freqs_cis): """ # Apply rotary embeddings to input tensors using the given frequency tensor. The input tensors are reshaped as complex numbers, and the frequency tensor is reshaped for broadcasting compatibility. The resulting tensors contain rotary embeddings and are returned as real tensors. """ xq_ = torch.vew_as_complex(xq.float().reshape(**xq.shape[:-1], -1, 2)) xk_ = torch.vew_as_complex(xq.float().reshape(**xk.shape[:-1], -1, 2)) freqs_cis = reshape_for_broad_cast(freqs_cis, xq_) xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3) xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3) return xq_out.type_as(xq), xk_out.type_as(xk)
defreshape_for_broad_cast(freqs_cis, x): """ Reshape frequency tensor for broadcasting it with another tensor. This function reshapes the frequency tensor to have the same shape as the target tensor 'x' for the purpose of broadcasting the frequency tensor during element-wise operations. """ ndim = x.ndim assert0<=1<ndim assert freqs_cis.shape == (x.shape[1], x.shape[-1]) shape = [d if i=1or i==ndim-1else1for i,d inenumerate(x.shape)] return freqs_cis.view(*shape)
# Note that self.params.max_seq_len is multiplied by 2 because the token limit for the Llama 2 generation of models is 4096. # Adding this multiplier instead of using 4096 directly allows for dynamism of token lengths while training or fine-tuning. freqs_cis = precompute_freqs_cis(d_model//num_heads, max_seq_len*2)
# start_pos: starting position for attention caching freqs_cls = freqs_cls[start_pos: start_pos+seqlen]
# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->RoFormer classRoFormerSinusoidalPositionalEmbedding(nn.Embedding): """This module produces sinusoidal positional embeddings of any length."""
@staticmethod def_init_weight(out: nn.Parameter): """ Identical to the XLM create_sinusoidal_embeddings except features are not interleaved. The cos features are in the 2nd half of the vector. [dim // 2:] """ n_pos, dim = out.shape position_enc = np.array( [[pos / np.power(10000, 2 * (j // 2) / dim) for j inrange(dim)] for pos inrange(n_pos)] ) out.requires_grad = False# set early to avoid an error in pytorch-1.8+ sentinel = dim // 2if dim % 2 == 0else (dim // 2) + 1 out[:, 0:sentinel] = torch.FloatTensor(np.sin(position_enc[:, 0::2])) out[:, sentinel:] = torch.FloatTensor(np.cos(position_enc[:, 1::2])) out.detach_() return out
@torch.no_grad() defforward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0): """`input_ids_shape` is expected to be [bsz x seqlen].""" bsz, seq_len = input_ids_shape[:2] positions = torch.arange( past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device ) returnsuper().forward(positions)
[6] finds that RoPE w/ Bias can increase the capability of length extrapolation.
where are rotation matrix, $\boldsymbol{a}, \boldsymbol{b}$ are learnable bias.
NB: Pure self-attention softmax gets equivalent results with or without bias term, since it can be cancelled by the softmax normalization.
But reducing the bias term for self-attention with RoPE cannot obtain the same results.[6]
T5 Bias
T5[7] adds no position encoding to word embeddings. Instead, it add a learned, shared bias to each query-key self-attention score that is dependent on just the distance between the query and key. In which multiple different distances share the same learned bias, which might be beneficial for length interpolation. Specifically, a fixed number of embeddings are learned, each corresponding to a range of possible key-query offsets.
T5 uses a bucket of 32 learnable parameters and assign the relative position bias with a log-binning strategy:
[8] finds that T5 bias enables length extrapolation.
T5 uses 32 embeddings for all models with ranges that increase in size logarithmically up to an offset of 128 beyond which it assigns all relative positions to the same embedding. All position embeddings are shared across all layers in T5, though within a given layer each attention head uses a different learned position embedding.
ifself.has_relative_attention_bias: self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets, self.n_heads) def_relative_position_bucket(relative_position, bidirectional=True, num_buckets=32, max_distance=128): """ Adapted from Mesh Tensorflow: https://github.com/tensorflow/mesh/blob/0cb87fe07da627bf0b7e60475d59f95ed6b5be3d/mesh_tensorflow/transformer/transformer_layers.py#L593 Translate relative position to a bucket number for relative attention. The relative position is defined as memory_position - query_position, i.e. the distance in tokens from the attending position to the attended-to position. If bidirectional=False, then positive relative positions are invalid. We use smaller buckets for small absolute relative_position and larger buckets for larger absolute relative_positions. All relative positions >=max_distance map to the same bucket. All relative positions <=-max_distance map to the same bucket. This should allow for more graceful generalization to longer sequences than the model has been trained on Args: relative_position: an int32 Tensor bidirectional: a boolean - whether the attention is bidirectional num_buckets: an integer max_distance: an integer Returns: a Tensor with the same shape as relative_position, containing int32 values in the range [0, num_buckets) """ relative_buckets = 0 if bidirectional: num_buckets //= 2 relative_buckets += (relative_position > 0).to(torch.long) * num_buckets relative_position = torch.abs(relative_position) else: relative_position = -torch.min(relative_position, torch.zeros_like(relative_position)) # now relative_position is in the range [0, inf)
# half of the buckets are for exact increments in positions max_exact = num_buckets // 2 is_small = relative_position < max_exact
# The other half of the buckets are for logarithmically bigger bins in positions up to max_distance relative_position_if_large = max_exact + ( torch.log(relative_position.float() / max_exact) / math.log(max_distance / max_exact) * (num_buckets - max_exact) ).to(torch.long) relative_position_if_large = torch.min( relative_position_if_large, torch.full_like(relative_position_if_large, num_buckets - 1) )
Length extrapolation allows transformers training on short sequences while testing on substantially long sequences, by means of relative positional encoding.
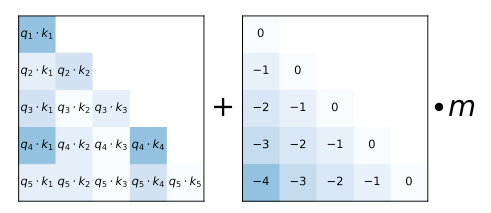
ALiBi[8] adds a static, non-learnable bias to the query-key dot product. As is done in T5 bias and RoPE, it adds position information to keys and querys at each layer.
where $\alpha$ is a head-specific slope (fixed). For $i$-th heads, the value of slope takes .
ALiBi bias is not multiplied by the scaling factor as in the original transformer.
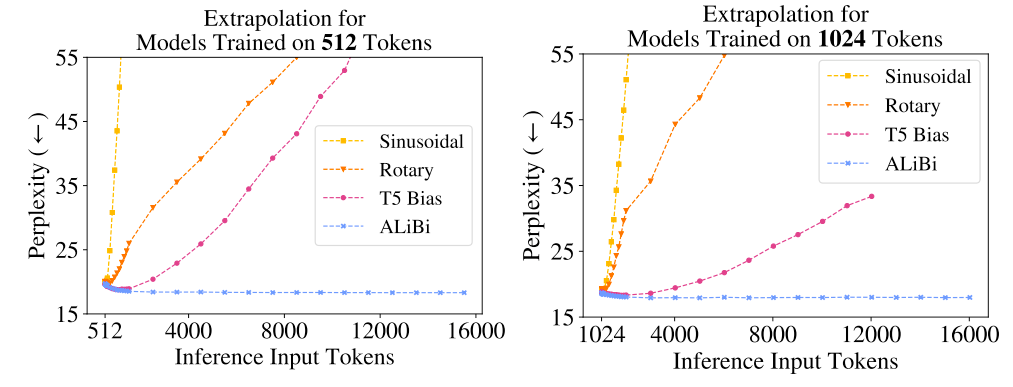
It is observed that ALiBi and T5 bias show length extrapolation ability[8], while RoPE and sinusoidal position do not have.
KERPLE
KErnelize Relative Positional Embedding for Length Extrapolation (KERPLE)[9] proposes kernelized positional embeddings as follows:
where are learnable parameters.
Triangle kernel: . It reduces to ALiBi.
xPos
Extrapolatable Position Embedding (XPOS)[10] proposes:
base = 1e4 heads = 12 seq_len = 8192 positions = np.arange(seq_len)[..., None] bar_d = 128# This is the hyperparameter of Sandwich i = np.arange(bar_d // 2)
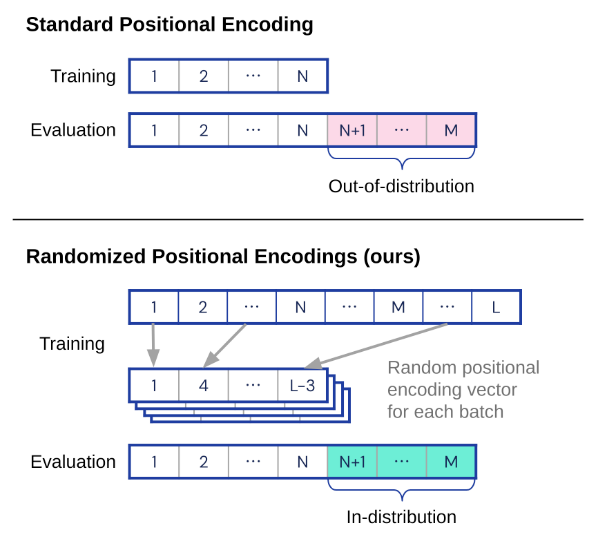
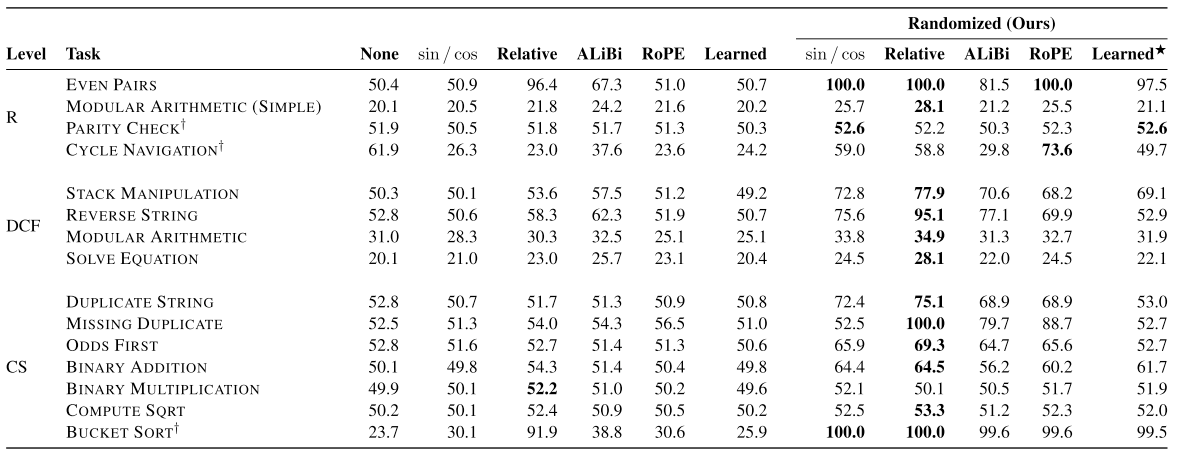
[13] introduce randomized position encoding that simulates the positions of longer sequences and randomly selects an ordered subset to fit the sequence’s length.
It allows transformers to generalize to sequences of unseen length (increasing test accuracy by 12.0% on average) across 15 algorithmic reasoning tasks.
No Position
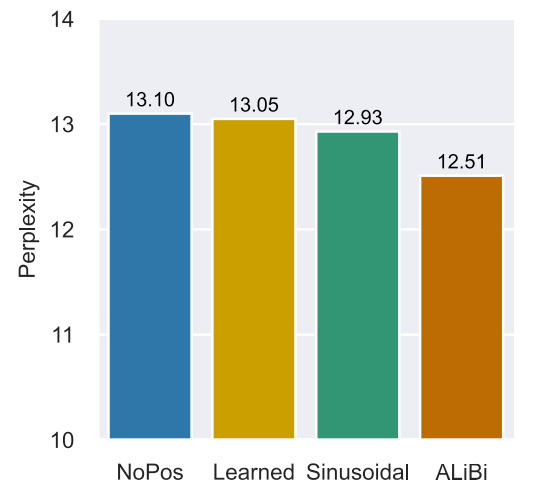
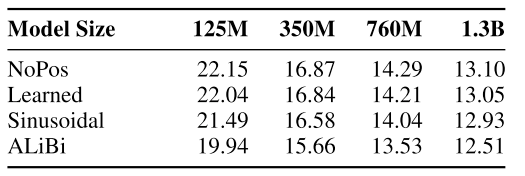
[12] observe that LMs without any explicit position encoding (NoPos) are still competitive with standard transformers across datasets, model sizes, and sequence length. It shows that causal LMs might derive positional awareness not only from the explicit positioning mechanism, but also from the causal mask effects.
Causal transformer LM can achieve competitive results with original LMs, while the bidirectional masked LMs fail to converge. This may be because that causal LMs can learn positions from the autoregressive nature (left-to-right) but masked LMs are order-invariant.
NB: LMs without explicit positional encodings (NoPos) are always slightly worse, suggesting the importance of inductive positional bias.
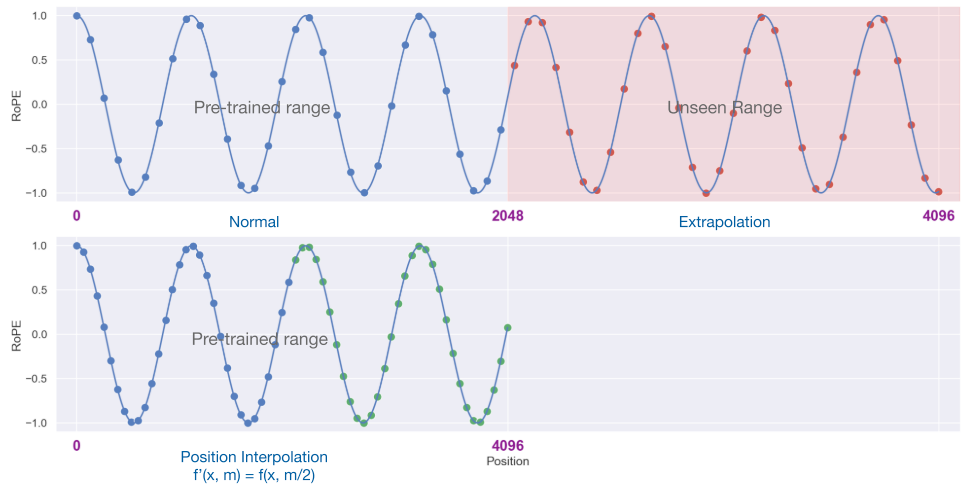
Position Interpolation
Instead of extrapolation, [15][16][17][18] presents position interpolation (PI) that directly downscales the non-integer position indices (RoPE-based) so that the maximum position index matches the previous context window limit in pre-training.
# Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings t = torch.arange( self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype, )
# These two lines: self.scale = 1 / 4 t *= self.scale
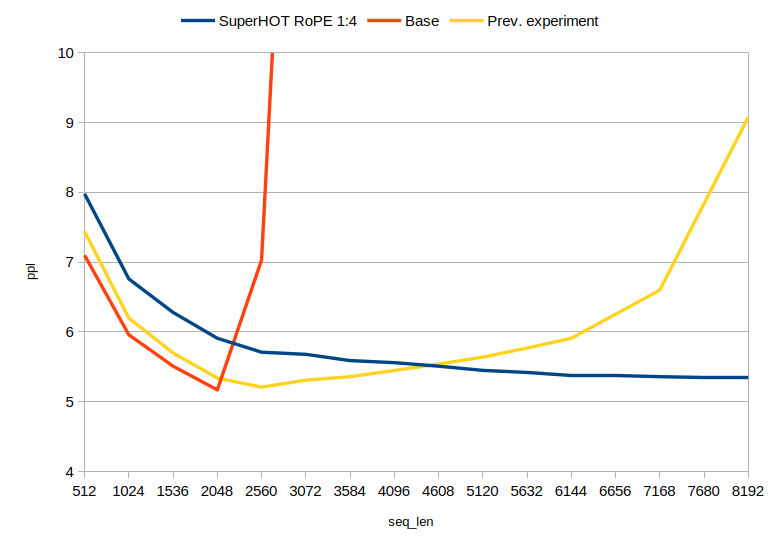
SuperHOT-13B[17] uptrained on scaling factor of 0.25, compared to base LLaMa 13B and a test LoRA trained on 6K sequence length with no scaling.
Note that PI requires further fine-tuning to take effects for length extrapolation.
NTK-Aware Scaled RoPE
Background
“Simply interpolating the RoPE’s fourier space “linearly” is very sub-optimal, as it prevents the network to distinguish the order and positions of tokens that are very close by.”[19]
“Scaling down the fourier features too much will eventually even prevent succesful finetunes (this is corroborated by the recent paper by Meta[15] that suggests an upper bound of ~600x)”[19]
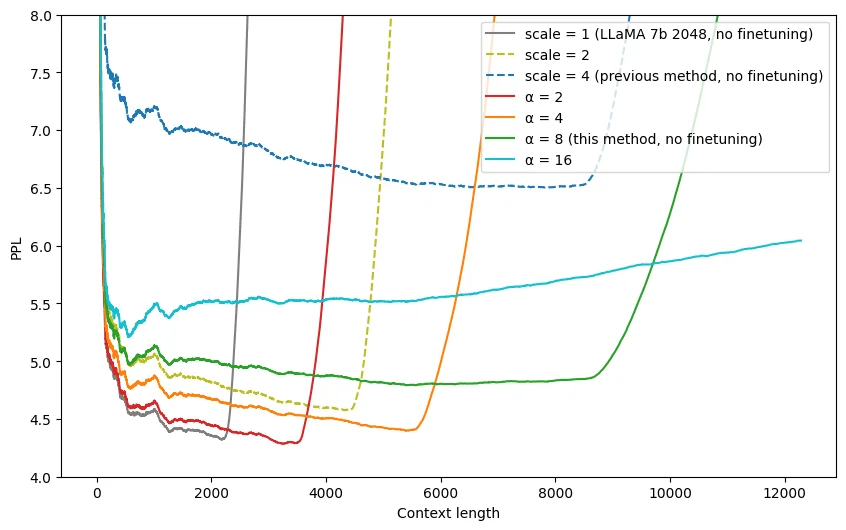
NTK-Aware Scaled RoPE[19][20] designs a nonlinear interpolation scheme using Neural Tangent Kernel (NTK) theory. It changes the base of the RoPE instead of the scale, which intuitively changes the “spinning” speed from which each of the RoPE’s dimension vectors shifts to the next.
# Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) t /= self.scale freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) dtype = torch.get_default_dtype() self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
defforward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] # This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case. if seq_len > self.max_seq_len_cached: self.max_seq_len_cached = seq_len t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype) t /= self.scale freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1).to(x.device) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False) return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), )
Dynamic NTK-Aware Scaled RoPE
Cons:
Compared to dynamic linear scaling, NTK-Aware has higher perplexity for shorter sequences, but better perplexity at the tail end of the sequence lengths.
NTK-aware RoPE suffers from catastrophic perplexity blowup, like regular RoPE and static linear scaling.
[22] introduces dynamic NTK-aware scaling. The scaling of $\alpha$ is set to:
This dynamically scales the $\alpha$ as the sequence length increases.
# Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) dtype = torch.get_default_dtype() self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
defforward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] # This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case. if seq_len > self.max_seq_len_cached: self.max_seq_len_cached = seq_len ifself.ntk: ### dynamic NTK base = self.base * ((self.ntk * seq_len / self.max_position_embeddings) - (self.ntk - 1)) ** (self.dim / (self.dim-2)) inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(x.device) / self.dim)) self.register_buffer("inv_freq", inv_freq) t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype) ifnotself.ntk: t *= self.max_position_embeddings / seq_len freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1).to(x.device) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False) return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), )
deffind_correction_factor(num_rotations, dim, base=10000, max_position_embeddings=2048): return (dim * math.log(max_position_embeddings/(num_rotations * 2 * math.pi)))/(2 * math.log(base)) #Inverse dim formula to find number of rotations
deffind_correction_range(low_rot, high_rot, dim, base=10000, max_position_embeddings=2048): low = math.floor(find_correction_factor(low_rot, dim, base, max_position_embeddings)) high = math.ceil(find_correction_factor(high_rot, dim, base, max_position_embeddings)) returnmax(low, 0), min(high, dim-1) #Clamp values just in case
deflinear_ramp_mask(min, max, dim): ifmin == max: max += 0.001#Prevent singularity
classLlamaPartNTKScaledRotaryEmbedding(torch.nn.Module): def__init__(self, dim, max_position_embeddings=2048, base=10000, scale=1, ntk_factor=1, extrapolation_factor=1, original_max_position_embeddings=2048, device=None): super().__init__() #Interpolation constants found experimentally for LLaMA (might not be totally optimal though) #Do not change unless there is a good reason for doing so! beta_0 = 1.25 beta_1 = 0.75 gamma_0 = 16 gamma_1 = 2
current_dtype = inv_freq_ntk.dtype current_device = inv_freq_ntk.device #Combine NTK and Linear low, high = find_correction_range(beta_0, beta_1, dim, base, original_max_position_embeddings) inv_freq_mask = (1 - linear_ramp_mask(low, high, dim // 2).type(current_dtype).to(current_device)) * ntk_factor inv_freq = inv_freq_linear * (1 - inv_freq_mask) + inv_freq_ntk * inv_freq_mask #Combine Extrapolation and NTK and Linear low, high = find_correction_range(gamma_0, gamma_1, dim, base, original_max_position_embeddings) inv_freq_mask = (1 - linear_ramp_mask(low, high, dim // 2).type(current_dtype).to(current_device)) * extrapolation_factor inv_freq = inv_freq * (1 - inv_freq_mask) + inv_freq_base * inv_freq_mask
self.register_buffer("inv_freq", inv_freq)
# Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) dtype = torch.get_default_dtype() self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
defforward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] # This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case. if seq_len > self.max_seq_len_cached: self.max_seq_len_cached = seq_len t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1).to(x.device) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False) return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), )
1.Vaswani, Ashish, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. “Attention is All you Need.” NeurIPS (2017). ↩



">[22]</span></a></sup>](/notes/images/Dynamic-NTK-RoPE.png)