
This is an introduction of variant Transformers.[1]
Relevant notes:
Transformer
The details of transformer is explained in previous blogs. The schema of Transformer is as following fig.
- Architecture
![]()
- Decoding
![]()
Vanilla Transformer
It is impossible to preprocess the entire context sequence in the whole corpus from the beginning, due to the limited resource in practice.
![]()
Vanilla Transformer (Al-Rfou et. al 2019)[2] splits the entire corpus into shorter segments, and train within each segment. This leads to the context fragmentation problem by ignoreing all contextual information from previous segments.
As in above fig., information never flows across segements.
- Evaluation
![]()
During evaluation, for each output step, the segment shifts right by only one position, which hurts the decoding efficiency and speed.
Relative Positional Representation(RPR)
- Relation-aware self-attn
Consider the pairwise relationships between input elements, which can be seen as a labeled, directed fully-connected graph. Let represent the edge between input elements and .
Then add the pairwise information to the sublayer output:
- Clip RPR
$k$ denotes the maximum relative position. The relative position information beyond $k$ will be clipped to the maximum value, which generalizes to the unseen sequence lengths during training.[5] In other words, RPR only considers context in a fixed window size $2k+1$, indicating $k$ elements on the l.h.s, and $k$ elements on the r.h.s, as well as itself.
where rpr and are learnable.
Trainable param number:
- MADPA:
MADPA with RPR:
My PyTorch implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102class MultiHeadedAttention_RPR(nn.Module):
""" @ author: Yekun CHAI """
def __init__(self, d_model, h, max_relative_position, dropout=.0):
"""
multi-head attention
:param h: nhead
:param d_model: d_model
:param dropout: float
"""
super(MultiHeadedAttention_RPR, self).__init__()
assert d_model % h == 0
# assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = utils.clones(nn.Linear(d_model, d_model), 4)
self.dropout = nn.Dropout(p=dropout)
self.max_relative_position = max_relative_position
self.vocab_size = max_relative_position * 2 + 1
self.embed_K = nn.Embedding(self.vocab_size, self.d_k)
self.embed_V = nn.Embedding(self.vocab_size, self.d_k)
def forward(self, query, key, value, mask=None):
"""
---------------------------
L : target sequence length
S : source sequence length:
N : batch size
E : embedding dim
---------------------------
:param query: (N,L,E)
:param key: (N,S,E)
:param value: (N,S,E)
:param mask:
"""
nbatches = query.size(0) # batch size
seq_len = query.size(1)
# 1) split embedding dim to h heads : from d_model => h * d_k
# dim: (nbatch, h, seq_length, d_model//h)
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) rpr
relation_keys = self.generate_relative_positions_embeddings(seq_len, seq_len, self.embed_K)
relation_values = self.generate_relative_positions_embeddings(seq_len, seq_len, self.embed_V)
logits = self._relative_attn_inner(query, key, relation_keys, True)
weights = self.dropout(F.softmax(logits, -1))
x = self._relative_attn_inner(weights, value, relation_values, False)
# 3) "Concat" using a view and apply a final linear.
# dim: (nbatch, h, d_model)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
def _generate_relative_positions_matrix(self, len_q, len_k):
"""
genetate rpr matrix
---------------------------
:param len_q: seq_len
:param len_k: seq_len
:return: rpr matrix, dim: (len_q, len_q)
"""
assert len_q == len_k
range_vec_q = range_vec_k = torch.arange(len_q)
distance_mat = range_vec_k.unsqueeze(0) - range_vec_q.unsqueeze(-1)
disntance_mat_clipped = torch.clamp(distance_mat, -self.max_relative_position, self.max_relative_position)
return disntance_mat_clipped + self.max_relative_position
def generate_relative_positions_embeddings(self, len_q, len_k, embedding_table):
"""
generate relative position embedding
----------------------
:param len_q:
:param len_k:
:return: rpr embedding, dim: (len_q, len_q, d_k)
"""
relative_position_matrix = self._generate_relative_positions_matrix(len_q, len_k)
return embedding_table(relative_position_matrix)
def _relative_attn_inner(self, x, y, z, transpose):
"""
efficient implementation
------------------------
:param x:
:param y:
:param z:
:param transpose:
:return:
"""
nbatches = x.size(0)
heads = x.size(1)
seq_len = x.size(2)
# (N, h, s, s)
xy_matmul = torch.matmul(x, y.transpose(-1, -2) if transpose else y)
# (s, N, h, d) => (s, N*h, d)
x_t_v = x.permute(2, 0, 1, 3).contiguous().view(seq_len, nbatches * heads, -1)
# (s, N*h, d) @ (s, d, s) => (s, N*h, s)
x_tz_matmul = torch.matmul(x_t_v, z.transpose(-1, -2) if transpose else z)
# (N, h, s, s)
x_tz_matmul_v_t = x_tz_matmul.view(seq_len, nbatches, heads, -1).permute(1, 2, 0, 3)
return xy_matmul + x_tz_matmul_v_tTensorflow implementation: [7]
Transformer-XL
Transformer-XL[3] is capable of learning the long-term dependency between different context fragments in Vanilla Transformers. It mainly employs the segment-level recurrence and relative positional encoding scheme.
Segment-level recurrence
![]()
During training, transformer-xl adopts both current and the previous segments, levaraging the recurrence mechanism on segement level.
Let the consecutive segment of length $L$ be and . Denote the $d$-dimensional hidden state of $n$-th layer for the $\tau$-th segment , be .
Thus, the recurrent dependency between and shifts one layer vertically and one segment horizontally, unlike the recurrence of same layer in RNNs. As a result, the largest long-range dependency length is linearly w.r.t # of layers times segment length, i.e. $O(N \times L)$.
- Evaluation
During evaluation process, the representation from previous segments can be reused, which is much faster compared with vanilla Transformers (as below fig.).![]()
Positional Encoding
Absolute Positional Encoding
- Problems: In the segment $\tau$, using the same absolute positional encoding for all segments cannot distinguish the positional difference between the same place in different segments, i.e. and for any $j=1, \cdots, L$.[1]
Here,
- (a) captures content-based information, i.e., how much attention the word in row-$i$ pays to word in col-$j$ despite the position.
- (b) captures content-dependent positional bias, representing how much the word in row-$i$ should attend to position $j$.
- (c) defines the global content biases, denoting how much the position-$i$ should attend to words in $j$-th position.
- (d) denotes the global positional bias, i.e., the soft attention that words in position $i$ should pay to a row in position $j$.
Relative positional encoding
Solution: use relative positional encoding. Conceptionally, positional encoding (pe) gives the temporal clue or biases about how information should be gathered, i.e., where to attend.[3] It is sufficient to know the relative distance beween each key vector and itself , i.e. $i-j$.
Replacement:
- replace all absolute pe’s in (b) and (d) with relative counterpart , which is a sinusoid encoding matrix without learnable weights.
- replace the query with a trainable parameter $\color{blue}{u \in \mathbb{R}^d}$ and similarly, $\color{blue}{v \in \mathbb{R}^d}$ in (d). Because the query vector is the same for all query positions, meaning that the query bias attending to words at various positions should be identical, no matter the query positions.
- substitude the weight of key vector with two matrices and respectively, to produce the $\color{Salmon}{\text{content-based}}$ and $\color{Green}{\text{location-based}}$ key vectors.
Thus,
- (a) denotes content-based addressing
- (b) captures content-dependent positional bias
- (c) denotes the global bias
- (d) represents the global positional bias
The PyTorch implementation:
1 | class TransformerXL(nn.Module): |
Comparison with Shaw et. al(2018)
Relative positional representation (RPR) (Shaw et. al, 2018) merely leveraged relative postional embedding, throwing away the sinusoid hard encodings. The RPR term introduces the trainable parameters. See my attention blog [6] for more details.
- The terms in the numerator correspond to terms (a) and (b) in relative PE in Transformer-XL. It is obvious that RPR shows a lack of the (c) and (d) terms.
R-Transformer
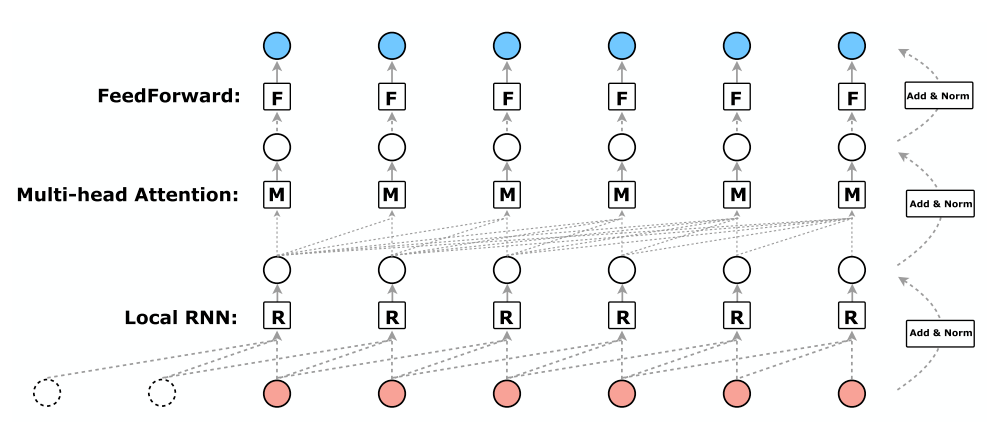
- Argument: multi-head attention only learn the global dependencies, but it ignores the inherent local structures.[4]
LocalRNN
R-Transformer[4] employs LocalRNN to model local structures, only focusing on local short-term dependencies with a local short sequence of length $M$: . The last hidden state is the representation of the local short sequences of a fixed length $M$.
- LocalRNNs pad $(M-1)$ positions before the start of a sequence.
- R-Transformers do not use any position embeddings.
- Here, the LocalRNN resembles the 1D ConvNets but the op for each window is not convolution. However, the conv op completely ignores the sequential information of positions within the local window.
Given sequence of length $m$: and window size $k=4$, localRNN encodes segmented short sub-sequence as:
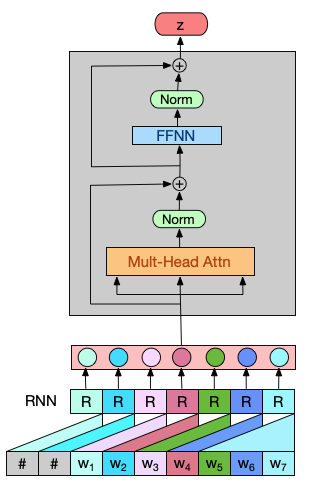
When doing implementation,
- first pad the sequence with embeddings of all 0s on the left hand side (kernel size-1) positions;
- then segment the subsequence of window size $k$, with one position shift right per time step. (See above digram.)
1 | class LocalRNN(nn.Module): |
For $i$-th layer, ()
References
- 1.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). ↩
- 2.Al-Rfou, R., Choe, D., Constant, N., Guo, M., & Jones, L. (2019, July). Character-level language modeling with deeper self-attention. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 3159-3166). ↩
- 3.Dai, Z., Yang, Z., Yang, Y., Cohen, W. W., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860. ↩
- 4.Wang, Z., Ma, Y., Liu, Z., & Tang, J. (2019). R-Transformer: Recurrent Neural Network Enhanced Transformer. arXiv preprint arXiv:1907.05572. ↩
- 5.Shaw, P., Uszkoreit, J., & Vaswani, A. (2018). Self-attention with relative position representations. arXiv preprint arXiv:1803.02155. ↩
- 6.Attention in a nutshell! ↩
- 7.Tensor2Tensor tensorflow code ↩
- 8.TRANSFORMERS FROM SCRATCH ↩