
Attention mechanism has been widely applied in natural langugage processing and computer vision tasks.
Attention mechanism
Background: what is WRONG with seq2seq?
Encoder-decoder architecture:
Encode a source sentence into a fixed-length vector from which a decoder generates a translation.[3]
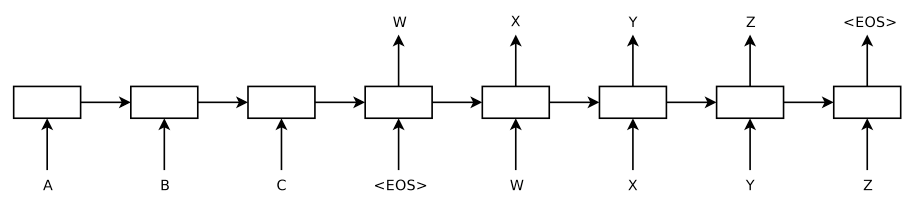
Seq2seq models encode an input sentence of variable length into a fixed-length vector representation $c$ (a.k.a sentence embedding, “thought” vector), by apply one LSTM to read the input sentence, one timestep at a time. The representation vector $c$ is expected to well capture the meaning of the source sentence.
Then decode the vector representation $v$ to the target sentence with another LSTM whose initial hidden state is the last hidden state of the encoder (i.e. the representation of the input sentence: $c$). [1]
where $g$ is a RNN that outputs the probability of , and is the hidden state of the RNN. $c$ is the fixed-length context vector for the input sentence.
Drawbacks: The fixed-length context vector $c$ is incapable of remembering long sentences[2]. It will forget the former part when processing the latter sequence. Sutskever et al.(2014)[1] proposed a trick that only reversing the order of source sentences rather than target sentences could be of benefit for MT.
Basic encoder-decoder architecture compresses all the necessary information of a source sentence into a fixed-length vector. This may be incapable of coping with long sentences, especially those that are longer than the sentences in the training corpus [3]. The performance of basic encoder-decoder drops rapidly as the length of an input sentence increases [4].
Thus attention mechanism is proposed to tackle this problem.
Attention mechanism
NMT by jointly learning to align and translate (EMNLP 2014)
Encoder
Bi-RNNs, obtain the annotation for each word by concatenating the forward and backward hidden states:
Decoder
The conditional probability is :
where $s_i$ is the RNN hidden state for time $i$:
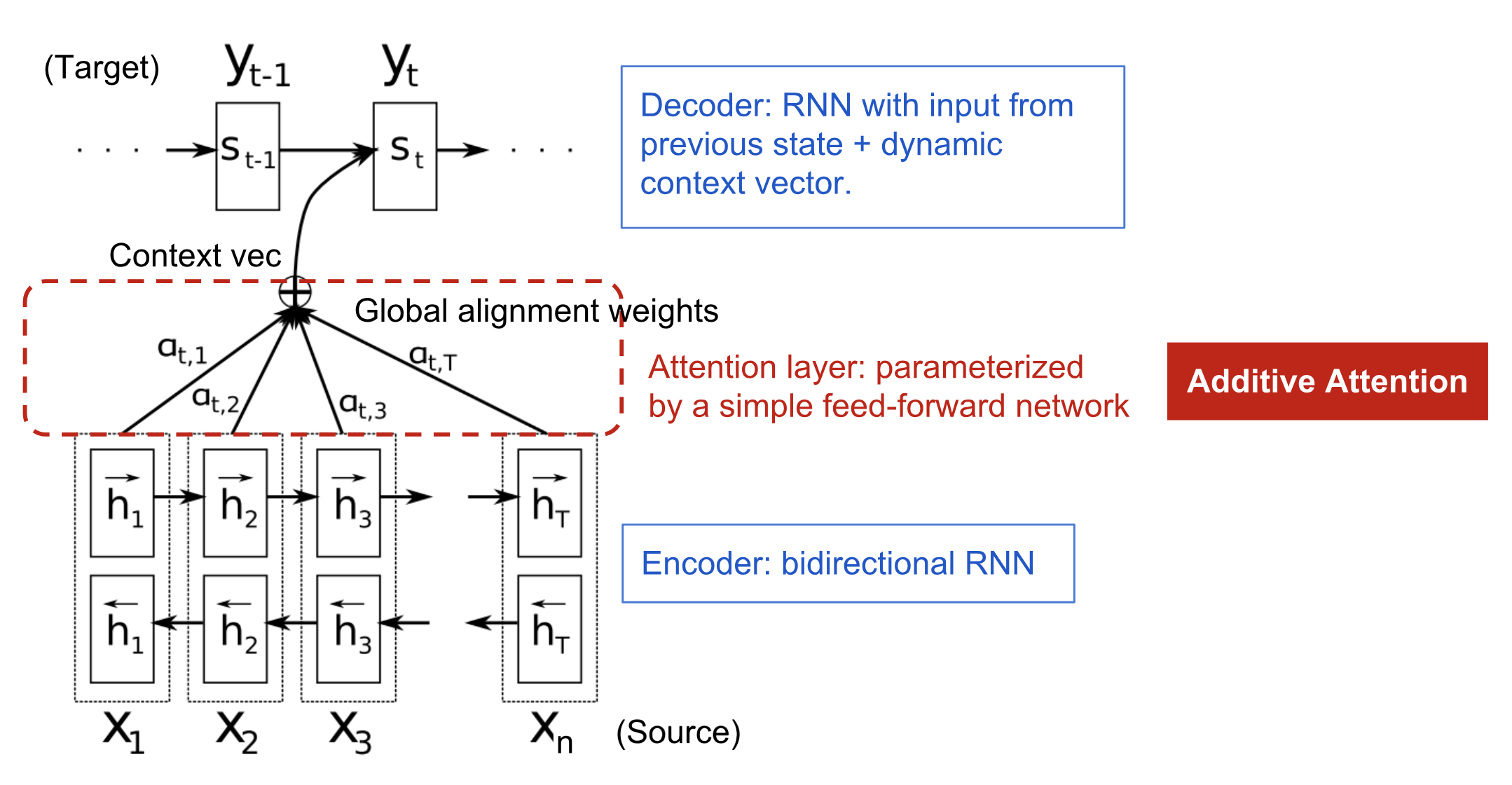
Unlike the basic encoder-decoder architecture, the probability of each output word is conditioned on a distinct context vector for each target word .
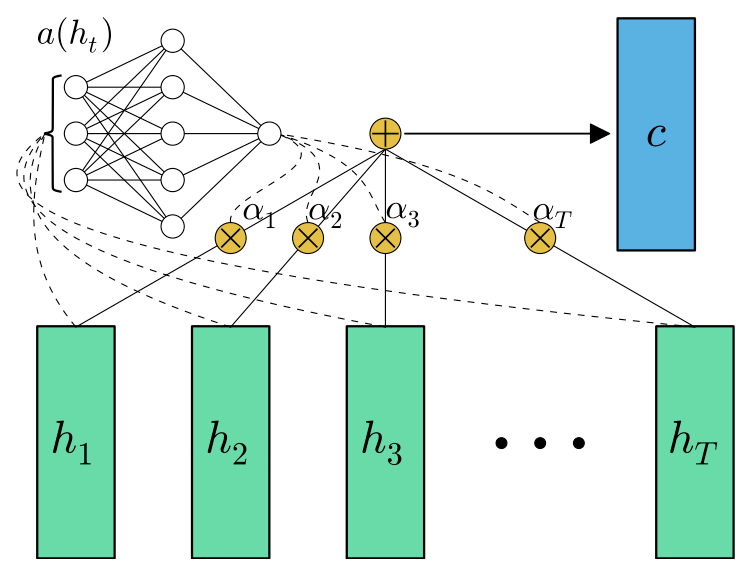
where is an alignment model which scores how well the input at the position $j$ and the output at position $i$ match [3]. Here $\text{score}$ is a simple FF-NN layer:
where and are learnable.
Attention zoo
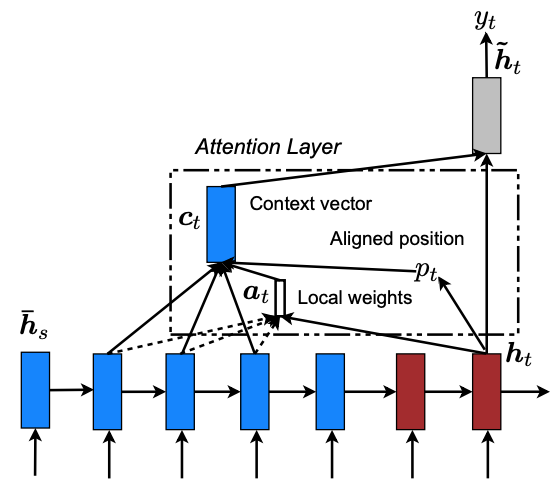
FF-FC attention(a.k.a additive attention)[9]
Transformer
Background
End2end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence. However, sequence-aligned RNNs preclude parallelization.
Model architecture
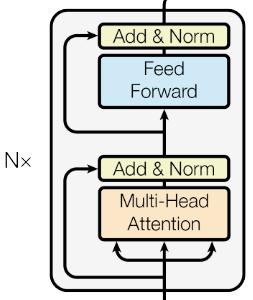
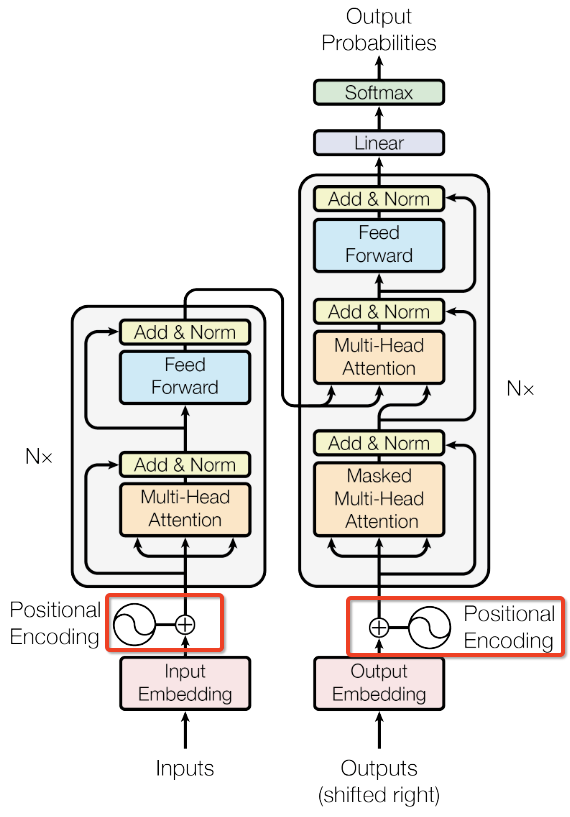
Architecture: stacked self-attention + point-wise FC layer (with residual connection + layer normalization)
Encoder
The transformer encoder applies one multi-head attention followed by one FC-FF layer, adopting the residual connection and layer normalization trick:
1 | class SublayerConnection(nn.Module): |
Layer Normalization:
where $\gamma$ and $\beta$ are learnable affine transform parameters.
1 | class LayerNorm(nn.Module): |
- N = 6 stack transformer layers
- Output dimension $d_{model}$ = 512
1 | def clones(module, N): |
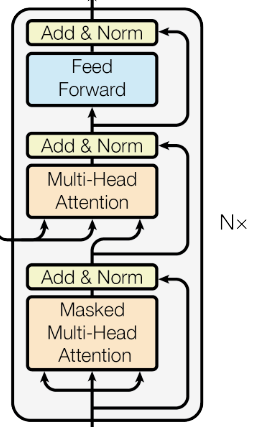
Decoder
Same as the encoder, N = 6 identical stacked layers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Decoder(nn.Module):
""" N layer decoder with masking"""
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = nn.LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
""" decoder"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublyer = utils.clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublyer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublyer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublyer[2](x, self.feed_forward)Difference
The first multi-head attention layer is masked to prevent positions from attending to subsequent positions, ensuring that the prediction output at position $i$ only depends on the known outputs at positions less than $i$, regardless of the future.
1 | def subsequent_mask(size): |
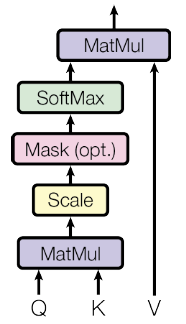
Multi-head attention
Transformer regarded encoded representation of input sequences as a set of key-value pairs (K,V), with dimension of input sequence length $n$. In MT context, encoder hidden states serve as (K, V) pairs. In the decoder the previous output is a query (with dimension $m$)
Scaled dot-product attention
where is the dimension of the key.
Q: Why dividing in dot-product operation?
- For small values of , the additive attention and dopt product attention perform similarly.
- For large values of , additive attention outperforms dot product attention without scaling.
- Interpretation: The dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. Assume $q$ and $k$ are independent random variables with mean 0 and variance 1. Their product has mean 0 and variance . Thus, scales the dot products by .
In conventional attention view:
Dot-product is faster and more space-efficient compared with additive attention (one FF layer) in practice.[6]
More precisely, for the input sequence , dot-product attention outputs the new sequence of the same length,
1 | def attention(query, key, value, mask=None, dropout=None): |
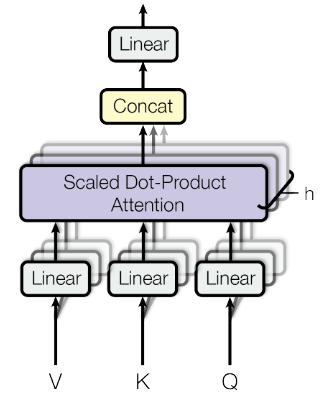
Multi-head attention
Multi-head: “linear project the $Q$, $K$ and $V$ $h$ times with different, learned linear projections to , and dimensions, respectively.”[6] Then concat all ($h$) the and use a linear layer to project to the final representation values.
Multi-head allows to “jointly attend to information from different representation subspaces at different positions“:
where , , ,
1 | class MultiHeadedAttention(nn.Module): |
Transformer attention:
- Mimic the conventional encoder-decoder attention mechanisms: $Q$ comes from previous decoder, $K$, $V$ come from the decoder output. This allows every position in the decoder to attend over all positions in the input sequence (as figure above).
- Encoder: K=V=Q, i.e. the output of previous layer. Each position in the encoder can attend to all positions in the previous layer of the encoder.
- Decoder: allow each position in the decoder to attend to all positions in the decoder up to and including that position.
Point-wise feed-forward nets
1 | class PositionwiseFeedForward(nn.Module): |
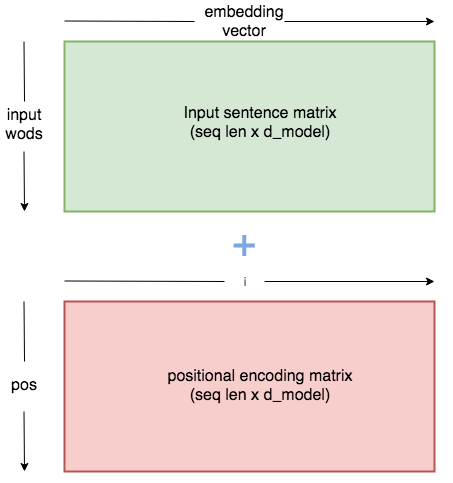
Positional encoding
Drawbacks: self-attention cannot capture the order information of input sequences.
Positional embeddings can be learned or pre-fixed [8].
RNNs solution: inherently model the sequential information, but preclude parallelization.
- Residual connections help propagate position information to higher layers.
Absolute Positional Encoding
Transformer solution: use sinusoidal timing signal as positional encoding (PE).
where $\text{pos}$ is the position in the sentence and $i$ is the order along the embedding vector dimension. Assume this allows to learn to attend by relative positions, since for and fixed offset $k$, can be represented as the linear function of [6]
1 | # positional encoding layer in PyTorch |
Usage: before stacked encoder/decoder, take the sum of PE and input embeddings (as figure below).
1 | class Embeddings(nn.Module): |
Relative Positional Representation(RPR)
- Relation-aware self-attn
Consider the pairwise relationships between input elements, which can be seen as a labeled, directed fully-connected graph. Let represent the edge between input elements and .
Then add the pairwise information to the sublayer output:
- Clip RPR
$k$ denotes the maximum relative position. The relative position information beyond $k$ will be clipped to the maximum value, which generalizes to the unseen sequence lengths during training.[14] In other words, RPR only considers context in a fixed window size $2k+1$, indicating $k$ elements on the l.h.s, and $k$ elements on the r.h.s, as well as itself.
where rpr and are learnable.
Trainable param number:
- MADPA:
MADPA with RPR:
PyTorch implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102class MultiHeadedAttention_RPR(nn.Module):
""" @ author: Yekun CHAI """
def __init__(self, d_model, h, max_relative_position, dropout=.0):
"""
multi-head attention
:param h: nhead
:param d_model: d_model
:param dropout: float
"""
super(MultiHeadedAttention_RPR, self).__init__()
assert d_model % h == 0
# assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = utils.clones(nn.Linear(d_model, d_model), 4)
self.dropout = nn.Dropout(p=dropout)
self.max_relative_position = max_relative_position
self.vocab_size = max_relative_position * 2 + 1
self.embed_K = nn.Embedding(self.vocab_size, self.d_k)
self.embed_V = nn.Embedding(self.vocab_size, self.d_k)
def forward(self, query, key, value, mask=None):
"""
---------------------------
L : target sequence length
S : source sequence length:
N : batch size
E : embedding dim
---------------------------
:param query: (N,L,E)
:param key: (N,S,E)
:param value: (N,S,E)
:param mask:
"""
nbatches = query.size(0) # batch size
seq_len = query.size(1)
# 1) split embedding dim to h heads : from d_model => h * d_k
# dim: (nbatch, h, seq_length, d_model//h)
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) rpr
relation_keys = self.generate_relative_positions_embeddings(seq_len, seq_len, self.embed_K)
relation_values = self.generate_relative_positions_embeddings(seq_len, seq_len, self.embed_V)
logits = self._relative_attn_inner(query, key, relation_keys, True)
weights = self.dropout(F.softmax(logits, -1))
x = self._relative_attn_inner(weights, value, relation_values, False)
# 3) "Concat" using a view and apply a final linear.
# dim: (nbatch, h, d_model)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
def _generate_relative_positions_matrix(self, len_q, len_k):
"""
genetate rpr matrix
---------------------------
:param len_q: seq_len
:param len_k: seq_len
:return: rpr matrix, dim: (len_q, len_q)
"""
assert len_q == len_k
range_vec_q = range_vec_k = torch.arange(len_q)
distance_mat = range_vec_k.unsqueeze(0) - range_vec_q.unsqueeze(-1)
disntance_mat_clipped = torch.clamp(distance_mat, -self.max_relative_position, self.max_relative_position)
return disntance_mat_clipped + self.max_relative_position
def generate_relative_positions_embeddings(self, len_q, len_k, embedding_table):
"""
generate relative position embedding
----------------------
:param len_q:
:param len_k:
:return: rpr embedding, dim: (len_q, len_q, d_k)
"""
relative_position_matrix = self._generate_relative_positions_matrix(len_q, len_k)
return embedding_table(relative_position_matrix)
def _relative_attn_inner(self, x, y, z, transpose):
"""
efficient implementation
------------------------
:param x:
:param y:
:param z:
:param transpose:
:return:
"""
nbatches = x.size(0)
heads = x.size(1)
seq_len = x.size(2)
# (N, h, s, s)
xy_matmul = torch.matmul(x, y.transpose(-1, -2) if transpose else y)
# (s, N, h, d) => (s, N*h, d)
x_t_v = x.permute(2, 0, 1, 3).contiguous().view(seq_len, nbatches * heads, -1)
# (s, N*h, d) @ (s, d, s) => (s, N*h, s)
x_tz_matmul = torch.matmul(x_t_v, z.transpose(-1, -2) if transpose else z)
# (N, h, s, s)
x_tz_matmul_v_t = x_tz_matmul.view(seq_len, nbatches, heads, -1).permute(1, 2, 0, 3)
return xy_matmul + x_tz_matmul_v_tTensorflow implementation: [16]
Thought: current attention mechanism is one round, and one dimension (at sequence dimension)
Citation
1 | @misc{chai2019attn-summary, |
References
- 1.Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112). ↩
- 2.Weng L. (2018, Jun 24). Attention? Attention! [Blog post]. Retrieved from https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html ↩
- 3.Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. CoRR, abs/1409.0473. ↩
- 4.Cho, K., Merrienboer, B.V., Bahdanau, D., & Bengio, Y. (2014). On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. SSST@EMNLP. ↩
- 5.Luong, T., Pham, H., & Manning, C.D. (2015). Effective Approaches to Attention-based Neural Machine Translation. EMNLP. ↩
- 6.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. NIPS. ↩
- 7.Cheng, J., Dong, L., & Lapata, M. (2016). Long Short-Term Memory-Networks for Machine Reading. EMNLP. ↩
- 8.LeCun, Y., Bottou, L., & Bengio, Y. (2006). PROC OF THE IEEE NOVEMBER Gradient Based Learning Applied to Document Recognition. ↩
- 9.Raffel, C., & Ellis, D.P. (2015). Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. CoRR, abs/1512.08756. ↩
- 10.Towards Data Science: How to code the transformer in PyTorch ↩
- 11.Harvard nlp: the annotated Transformer ↩
- 12.Illustrated Transformer ↩
- 13.Medium: How Self-Attention with Relative Position Representations works ↩
- 14.Shaw, P., Uszkoreit, J., & Vaswani, A. (2018). Self-attention with relative position representations. arXiv preprint arXiv:1803.02155. ↩
- 15.RPR blog (in Chinese) ↩
- 16.Tensor2Tensor tensorflow code ↩
- 17.Attn: Illustrated Attention ↩