
The mathematical foundations of policy gradient algorithms.
Policy Gradient preliminaries
Policy gradient estimates the gradients with the form:[10]
where may be the following forms:
where (6) yields the lowest possible variance:
The advantage function
- Intuitional interpretation: a step in policy gradient direction should increase the probability of better-than-average actions and decrease the probability of worse-than-average actions. The advantage function measures whether or not the action is better or worse than the policy’s default behavior (expection).
Vanilla Policy Gradient
The goal of RL
Objective
- Infinite horizon
- Finite horizon
Evaluating the objective
Direct differentiation
A convenient identity:
Overall,
- Comparison to Maximum likelihood:
Drawbacks: variance
- Reducing variance
- Future does not affect the past
- Casuality: policy at time $t’$ cannot affect reard at time t when $t<t’$
where denotes the reward to go:
Baselines
where
proof:
- Substracting abseline is
unbiased in expectation Average reward is not the best baseline, but it’s pretty good.
Optimal baseline:
Hence,
We get:
This is just the expected reward, weighted by gradient magnitudes.
Deriving the simplest policy gradient (Spinning Up)
Consider the case of a stochastic, parameterized policy, . We maximize the expected return
Optimize the policy by gradient descent:
Step by step:
Probability of a Trajectory. The probability of a trajectory given that actions come from is:
The log-derivative trick.
Log-probability of a trajectory:
- Gradients of environment functions
The environment has no dependence on $\theta$, so gradients of , and $R(\tau)$ are zero. - Grad-log-prob of a trajectory.
The gradient of the log-prob of a trajectory is thus
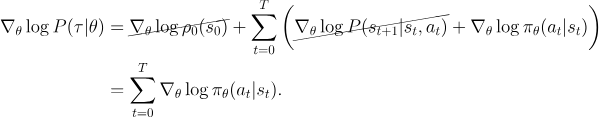
Overall:
We can estimate the expectation with a sample mean. If we collect a set of trajectories where each trajectory is obtained by letting the agent act in the environment using the policy , the policy gradient can be estimated as:
where $|\mathcal{D}|$ is the # of trajectories in $\mathcal{D}$

REINFORCE
REINFORCE(Monte-Carlo policy gradient) is a Monte-Carlo algorithm using the complete return from the time $t$, which includes future rewards up until the end of episode. [3]
- Intuition: the update increases the paramer vector in this distribution proportional to the return, and inversely proportional to the action probability.
REINFORCE algorithm:
- Initialize policy parameter $\theta$ at random;
- For each episode:
- Generate an episode , following $\pi(\cdot \vert \cdot, \theta)$
- Loop for each step of the episode $t=0,1,\cdots, T-1$:
- $ G \leftarrow \sum_{k=t+1}^T \gamma^{k-t-1} R_k $
- $\theta \leftarrow \theta + \alpha \gamma^t G \nabla \ln \pi (A_t \vert S-t, \theta)$
- Drawbacks: REINFORCE has a high variance and thus produces slow learning.
REINFORCE with Baseline
A variant of REINFORCE is to substract a baseline value from the return $G_t$ to reduce the variance of policy gradient while keeping the bias unchanged.[3]
Actor-Critic
Actor-Critic consists of two components
Actor-Critic algorithms:
- Initialize policy parameter $\pmb{\theta} \in \mathbb{R}^{d’}$ and state-value weights $\pmb{w} \in \mathbb{R}^d$
- For each episode:
- Initilize the first state of episode $ S \leftarrow 1$
- While $S$ != TERMINAL (for each time step):
- $A \sim \pi(\cdot \vert S,\theta) $
- Take action $A$, observe $S’$, $R$
- $\delta \leftarrow R + \gamma \hat{v}(S’,\pmb{w}) - \hat{v}(S,\pmb{w})$ (If $S’$ is terminal, then $\hat{v}(S’, \pmb{w})=0$)
- $\pmb{w} \leftarrow \pmb{w} + \alpha^{\pmb{w}} \delta \nabla \hat{v}(S,\pmb{w})$
- $\pmb{\theta} \leftarrow \pmb{\theta} + \alpha^{\theta} I \delta \nabla \ln \pi(A \vert S,\theta)$
- $I \leftarrow \gamma I$
- $S \leftarrow S’$
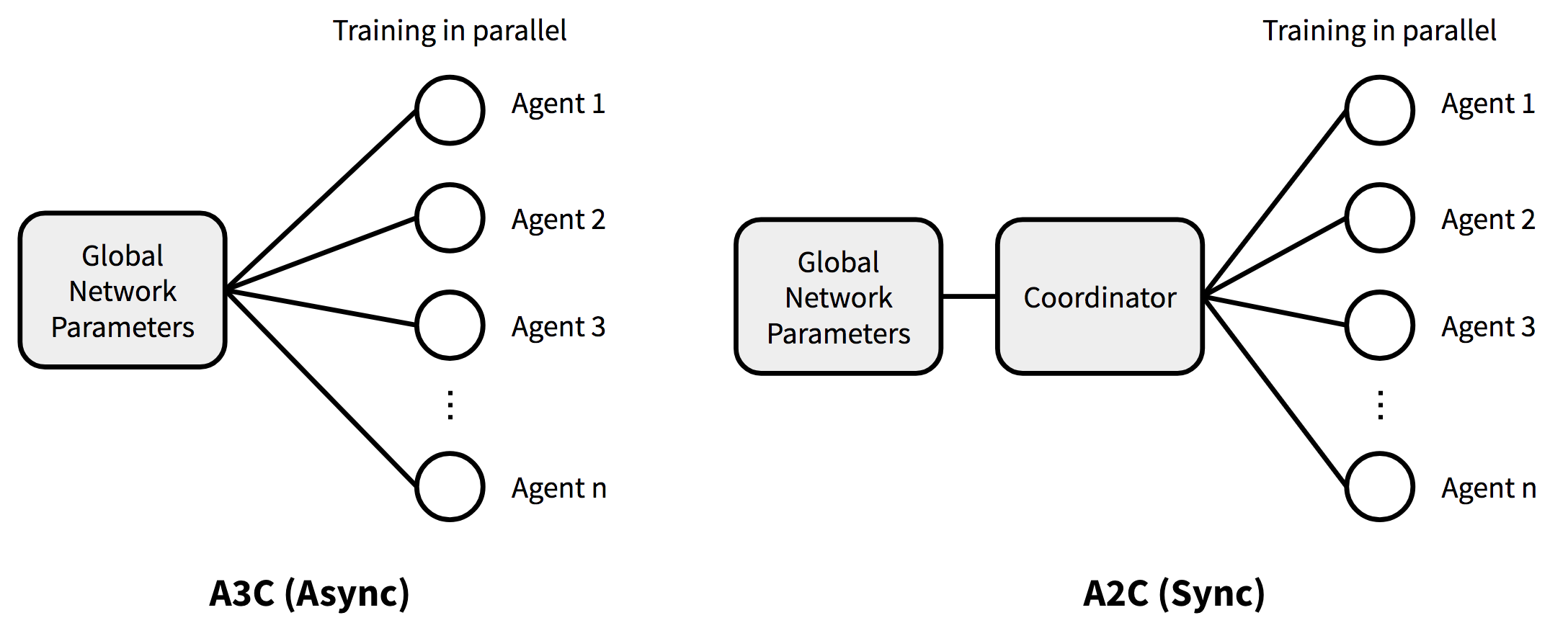
Asynchronous Advantage Actor-Critic(A3C)
Mnih et.al(2016) [1] proposed an asynchronous gradient descent for optimization of deep neural networks, showing that parallel actor-learners have a stabilizing effect on training, greatly reducing the training time with a single multi-core CPU instead of GPU.
- Instead of experience replay, they asynchronously execute multiple agents in parallel on multiple instances of the environment. This parallelism also decorrelates the agents’ data into a more stationary process, since at any given time-step the parallel agents will be experiencing a variety of different states.
- Apply different exploration policies in each actor-learner to maximize the diversity. By running different exploration policies in different threads, the overall updates of parameters are likely to be less correlated in time than a single agent applying online updates.
- The gradient accumulation in parallelism can be seen as a prarallized minibatch of stochastic gradient update, where the parameters update thread-by-thread in the direction of each thread independently.[2]
A3C pseudocode for each actor-learner thread:
- Assume global shared parameter vectors $\theta$ and and global shared counter $T=0$, thread-specified parameter vectors $\theta’$ and $\theta’_v$
- Initialize the thread step count $t \leftarrow 1$
- While :
- Reset gradients: $d\theta \leftarrow 0$ and $d\theta_v \leftarrow 0$
- Synchronize thread-specific parameters $\theta’=\theta$ and $\theta’_v = \theta_v$
- $t_\text{start} = t$
- sample state
- while ( != TERMINAL and ):
- Perform the action
- Receive reward and new state ;
- $t \leftarrow t+1$
- $T \leftarrow T+1$
- The return estimation:
- For do
- $R \leftarrow \gamma R + R_i$; here $R$ is a MC measure of
- Accumulate gradients w.r.t $\theta’$:
- Accumulate gradients w.r.t
- Perform asynchronous update of $\theta$ using $d\theta$ and of using
Advantage Actor-Critic (A2C)
Removing the first “A”(Asynchronous) from A3C, we get advantage actor-critic (A2C). A3C updates the global parameters independently, thus thread-specific agents updates the policy with different versions and aggregated updates could not be optimal.
A2C waits for each actor to finish its segment of experience before performing an update, averaging over all of the actors. In the next iteration, parallel actors starts from the same policy. A2C is more cost-effective than A3C when using single-GPU machines, and is faster than a CPU-only A3C implementation when using larger policies. [4]
Trust Region Policy Optimization (TRPO)
Trust Region Policy Optimization (TRPO) enforces a KL divergence constraint at every point in the state space.
TRPO minimizes a certain surrogate obejctive fuction guarateeing policy improvement with non-trivial step sizes, giving monotonic improvements with little tuning of hyperparameters at each update[5].
- Let $\tilde{\pi}$ denote the expected return of another policy $\tilde{\pi}$ in terms of the advantage over the policy $\pi$
- denotes discounted visitation frequency: .
The aforementioned update does not give any guidance on the step size to update.
Conservative policy iterationprovides explicit lower bounds on the improvements of $\eta$.
Let denote the current policy and , the new policy is:
where the lower bound:
Replace $\alpha$ with the distance measure between $\pi$ and $\tilde{\pi}$, total vairation divergence: for discrete distributions $p,q$.
Define
Since , Let , we get:
Let , then:
Therefore,
This guarantees that the true objective $\eta$ is non-decreasing.
Afterwards, we improve the true objective $\eta$. Let represent , and $\theta$ represent .
Thus, we use a constraint on the KL divergence beween the new policy and the old policy, i.e., a trust region constraint:
By heuristic approximation, we consider the average KL divergence to replace the $\max$ KL divergence:
- Expand :
- Replace the sum over actions by an important sampling estimator:
- Replace with expectation ; replace the advantage values by the $Q$-values . Finally, we get
Proximal Policy Optimization (PPO)
Problems: TRPO is relatively complicated, and is not compatible with architectures that include noise (e.g. dropout) or parameter sharing (between the policy and value function, or with auxiliary tasks).[8]
PPO with clipped surrogate objective performs better than that with KL penalty.
PPO-clip *
Clipped surrogate objective
- Let , so . TRPO maimize a surrogate objective with conservative policy iteration (CPI). Without the constraint, maximization of $L^{\text{CPI}}$ would lead to excessively large policy update.
- PPO pernalize changes to the policy that move away from 1:
where $\epsilon$ is a hyperparameter, say, $\epsilon=0.2$. The intuition is to take the minimum of the clipped and unclipped objective, thus the final objective is a lower bound (i.e. a pessimistic bound) on the unclipped objective.
PPO-penalty
Adaptive KL pernalty coefficient
- Variant: add a penalty on KL divergence
- With mini-batch SGD, optimize the KL-penalized objective:
- Compute
- If $d < d_\text{target}/1.5, \beta \leftarrow \beta/2$
- If $d > d_\text{target} \times 1.5, \beta \leftarrow \beta \times 2$
PPO algorithms
Finally, the objective function is augmented with an error term on the value estimation and an entropy term to encourage sufficient exploration.
where , are constant coefficients.
- Settings:
- RNN
- Adam
- mini-batch SGD
PPO algorithms with Actor-Critic style:
- for iteration=$1,2,,\cdots$:
- for actor=$1,2,,\cdots, N$:
- run policy in environment for $T$ timesteps;
- Compute advantage estimates ;
- Optimize surrogate $L$ w.r.t $\theta$, with $K$ epochs and mini-batch size $M \leq NT$
- $\theta_\text{old} \leftarrow \theta$
- for actor=$1,2,,\cdots, N$:
Distributed PPO
Let $W$ denote # of workers; $D$ sets a threshold for the # of workers whose gredients must be available to update the parameters; $M$, $B$ is the # of sub-iterations with policy and baseline updates given a batch of datapoints.[9]
The distributed PPO-penalty algorithms:


Experiments indicates that averaging gradients and applying them synchronously leads to better results than asynchronously in practice.
Generalized Advantage Estimation(GAE)
Challenges:
- Requires a large number of samples;
- Difficulty of obtaining stable and steady improvement despite the non-stationarity of the incoming data.
credit reward problemin RL (a.k.a distal reward problem in the behavioral literature): long time delay on rewards.
Solution:[10]
- Use value functions to reduce the variance of policy gradient estimates at the cost of some bias, with an exponentially-weighted estimator of advantage function that is analogous to TD($\lambda$);
- Use TRPO for both policy and value function with NNs.
Advantage function estimation
The advantage has the form:
Now take the form of $k$ of $\delta$ terms, denoted by :
With $k \rightarrow \infty$, the bias generally becomes smaller:
which is simply the empirical returns minus the value function baseline.
GAE
GAE is defined as the exponentially-weighted average of these $k$-step estimators:
Now consider two special cases:
- when $\lambda \rightarrow 0$:
- when $\lambda \rightarrow 1$:
It shows that GAE($\gamma,1$) has high variance due to the sum of terms; GAE($\gamma,0$) induces bias but with lower variance. The GAE with $\lambda \in (0,1)$ reaches a tradeoff between the bias and variance.
Interpretation as Reward Shaping
Reward shaping refers to the following reward transformation of MDP:
where $\Phi: \mathcal{S} \rightarrow \mathbb{R}$ is an arbitrary scalar-valued function on the state space.
Let $\tilde{Q}^{\pi, \gamma}$, $\tilde{V}^{\pi, \gamma}$, $\tilde{A}^{\pi, \gamma}$ be the value and advatage functions of the transformed MDP:
Let $\Phi = V$, then
Value function estimation
Constrain the average KL divergence between the previous value function and new value function to be smaller than $\epsilon$:
Actor-Critic with Experience Replay(ACER)
Actor-Critic with Experience Replay(ACER)[12] employs truncated importance sampling with bias correction, stochastic dueling network architectures, and a new TRPO method.
Importance weight truncation with bias correction
where , with importance weight
Efficient TRPO
ACER maintains an average policy network that represents a running average of past policies and forces the updated policy to not deviate far from the average.
Update the parameter of the average policy net work “softly” after each update:
The policy gradient w.r.t $\phi$:


ACKTR
Soft Q-learning
Soft Q-learning(SQL) expresses the optimal policy via Boltzmann distribution (a.k.a Gibbs distribution).
- Soft Q-learning fomulates a stochastic policy as a (conditional) energy-based model (EBM), with the energy function corresponding to the “soft” Q-function obtained when optimizing the maximum entropy objective.
- “The entropy regularized actor-critic algorithms can be viewed as approaximate Q-learning methods, with the actor serving the role of an approimate sampler from an intrctable posterior” [14].
Contributions:
- Improved exploration performance is with multi-modal reward landscapes, where conventional deterministic or unimodal methods are at high risk of falling into suboptimal local optima.
- Stochastic energy-based policies can provide a much better initialization for learning new skills than either random policies or policies pretrained with maximum expected reward objectives.
Maximum Entropy RL
- Conventional RL objectives to learn a policy :
- Maximum entropy RL augments the entropy term to maximize its entropy at each visited state:where $\alpha$ is used to determine the relative importance of entropy and reward.
Energy-based models (EBM)
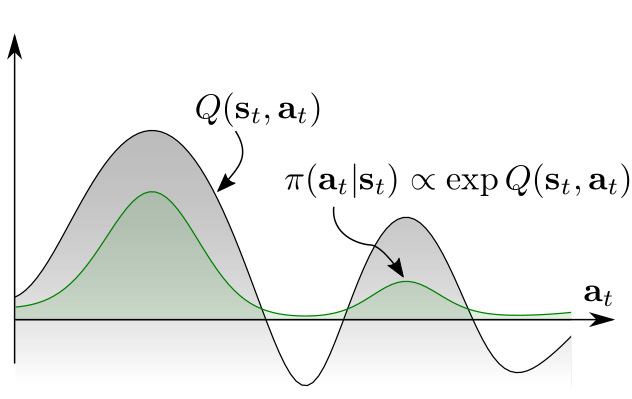
As the figure below, the conventional RL specifies a unimodal policy distribution, centered at the maimal Q-value and extending toe the neighboring actions to provide noise for exploration (as red distribution). The exploration is biased towards the upper mode, RL ignores the lower mode completely.[15]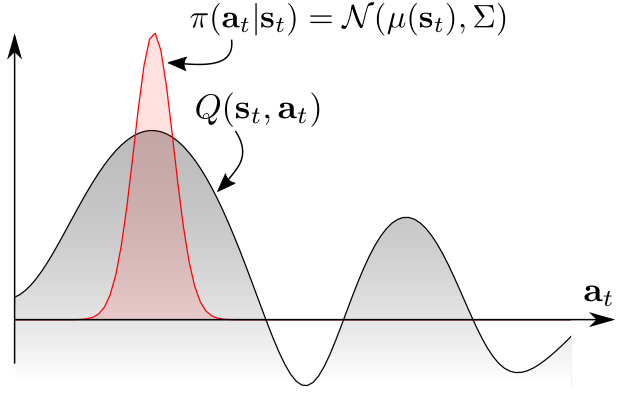
To ensure the agent to explore all promising states while prioritizing the more promising mode, Soft Q-learning definesthe policy w.r.t exponentiated Q-values (see green distribution):
where $\mathcal{Q}$ is an energy function, that could be represented by NNs.
Soft value functions
The soft Bellman equation:
where
The soft Q-function is:
The soft value function:
Then the optimal policy is:
Proofs
- Define the optimal policy with the EBM form:where $Z$ is the sum of the numerator.
- Minimize the KL divergence:
Soft Q-learning
- Soft Bellman-backup
This cannot be performed exactly in countinuous or large state and action spaces. Sampling from the energy-based model is intractable in general.
Sampling
Importance sampling
where can be an arbitrary distribution over the action space.
It can also be equivalent as minimizing:
where is the target $Q$-value.
Stein Variational Gradient Descent (SVGD)
- How to approximately sample from the soft Q-funtion?
- MCMC based sampling
- learn a stochastic sampling network trained to output approximate samples from the target distribution
Soft Q-learning applies the sampling network based on Stein variational gradient descent (SVGD) and amortized SVGD.
- Learn a state-conditioned stochastic NN that maps noise samples $\xi$ drawn from an arbitrary distribution into unbiased action samples from the target EBM of .
- The induced distribution of the actions approximates the energy-based distribution w.r.t KL divergence:
- SVGD provides the most greedy directions as a functional:Update the policy networks:
Algorithms
$\mathcal{D} \leftarrow$ empty replay memory
Assign target parameters: $\bar{\theta} \leftarrow \theta$, $ \bar{\phi} \leftarrow \phi $
- for each epoch:
- for each t do:
- Collect experience
Sample an action for using $f^\phi$: where $\xi \sim (0; I)$
Sample next state from the environment:
Save the new experience in the replay memory: - Sample a mini-batch from the replay memory
- Update the soft Q-function parameters:
Sample for each
Compute empirical soft values in Compute empirical gradient of Update $\theta$ according to using Adam. - Update policy
Sample for each
Compute actions
Compute using empirical estimate of Compute empirical estimtate of of Update $\phi$ according to using Adam
- Collect experience
- If epoch $%$ update_interval == 0:
$\bar{\theta} \leftarrow \theta, \quad \bar{\phi} \leftarrow \phi $
- for each t do:
Benefits
- Better exploration. SQL provides an implicit exploration stategy by assgining each action a non-zero probability, shaped by the current belief about its value, effectively combining exploration and exploitation in a natural way.[15]
- Fine-tuning maximum entropy policies:
general-to-specific transfer.Pre-train policies for general purpose tasks, then use them as templates or initializations for more specific tasks. - Compositionality. Compose new skills from existing policies—even without any fine-tuning—by intersecting different skills.[15]

- Robustness. Maximum entropy formulation encourages to try all possible solutions, the agents learn to explore a large portion of the state space. Thus they learn to act in various situations, more robust against perturbations in the environment.

Soft Actor-Critic(SAC)
Soft Actor-Critic (SAC)[13] is an off-policy actor-critic algorithm based on the maximum entropy framework. Like SQL, SAC augments the conventional RL objectives with a maximum entropy objective:
where the $\alpha$ determines the relative importance of the entropy term against the reward, and thus controls the stochasticity of the optimal policy.
The maximum entropy terms
- Encourage to explore more widely, while giving up on clearly unpromising avenues;
- Capture multiple modes of near-optimal behavior.
- Improve learning speed and exploration.
Soft policy iteration
Policy evaluation
The soft-Q value of the policy $\pi$:
where the soft state value function:
Policy Improvement
For each state, we update the policy according to:
where the partitioning function normalizes the distribution.
SAC
Consider a parameterized state value function , soft Q-function and a tractable policy .
The soft value function is trained to minimize the squared residual error:
The soft Q-function can be trained to minimize the soft Bellman residual:
with
The policy can be optimized by the expected KL-divergence:
Minimizing with reparameterization trick.
- Reparameterize the policy with an NN transformation:where $\epsilon$ is an input noise vector, sampled from some fixed distribution.
Rewrite the previous objective as:
Employ two Q-functions to mitigate positive bias in the policy improvement step, using the minimum of the Q-functions for the value gradient and policy gradient.
Automatically adjusted temperature
SAC is brittle w.r.t the temperature parameter. Choosing the optimal temperature $\alpha$ is non-trival, and the temperature needs to be tuned for each task. [17]
SAC finds a stochastic policy with maximal expected return that satisfies a minimum expected entropy constraint.
where $\mathcal{H}$ is a desired minimum expected entropy.
- Rewite the objective as an iterated maximization
- Finally we get:
Algorithms
Update $\alpha$ with following objective:

Deterministic Policy Gradient (DPG)
Deep DPG (DDPG)
Distributed Distributional DDPG(D4PG)
Multi-Agent DDPG(MADDPG)
Twin Delayed Deep Deterministic PG(TD3)
References
- 1.Mnih, V., Badia, A.P., Mirza, M.P., Graves, A., Lillicrap, T.P., Harley, T., Silver, D., & Kavukcuoglu, K. (2016). Asynchronous Methods for Deep Reinforcement Learning. ICML. ↩
- 2.Policy gradient algorithms #A3C ↩
- 3.- Actor: updates the policy parameters $\theta$ for $\pi_\theta(a \vert s)$ in the direction suggested by the critic. - Critic: updates the value function parameter $w$ and could be action-value $Q_w(a \vert s)$ or state-value $V_w(s)$ ↩
- 3.Sutton, R.S., & Barto, A.G. (1988). Reinforcement Learning: An Introduction. IEEE Transactions on Neural Networks, 16, 285-286. ↩
- 4.A2C ↩
- 5.Schulman, J., Levine, S., Abbeel, P., Jordan, M.I., & Moritz, P. (2015). Trust Region Policy Optimization. ICML. ↩
- 6.TRPO blog 1 ↩
- 7.TRPO blog 2 ↩
- 8.Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. ArXiv, abs/1707.06347. ↩
- 9.Heess, N., Dhruva, T., Sriram, S., Lemmon, J., Merel, J., Wayne, G., Tassa, Y., Erez, T., Wang, Z., Eslami, S.M., Riedmiller, M.A., & Silver, D. (2017). Emergence of Locomotion Behaviours in Rich Environments. ArXiv, abs/1707.02286. ↩
- 10.Schulman, J., Moritz, P., Levine, S., Jordan, M.I., & Abbeel, P. (2016). High-Dimensional Continuous Control Using Generalized Advantage Estimation. CoRR, abs/1506.02438. ↩
- 11.Wu, Y., Mansimov, E., Grosse, R. B., Liao, S., & Ba, J. (2017). Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. In Advances in neural information processing systems (pp. 5279-5288). ↩
- 12.Wang, Z., Bapst, V., Heess, N., Mnih, V., Munos, R., Kavukcuoglu, K., & de Freitas, N. (2016). Sample efficient actor-critic with experience replay. arXiv preprint arXiv:1611.01224. ↩
- 13.Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290. ↩
- 14.Haarnoja, T., Tang, H., Abbeel, P., & Levine, S. (2017, August). Reinforcement learning with deep energy-based policies. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 (pp. 1352-1361). JMLR. org. ↩
- 15.Soft Q-learning, UC Berkeley blog ↩
- 16.Notes on the Generalized Advantage Estimation Paper ↩
- 17.Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., ... & Levine, S. (2018). Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905. ↩