
An introduction to key concepts and terminology in reinforcement learning.
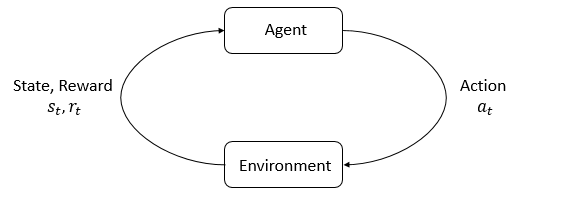
Environment and agent
The main components of RL are environment and agent.
- The environment is the world that the agent lives in and interacts with. At every step of interaction, the agent sees a (possibly partial) observation of the state of the word, then decide on an action to take. The environment changes when the agent acts on it, but my also change on its own.
- The agent also perceives a reward signal from the environment, a number that tells it how good or bad the current world state is. The goal of the agent is to maximize its cumulative reward, called return.
State and observations
State:
- A state $s$ is a complete description of the state of the world. There is no information which is hidden from the state.
Observation:
- An observation $o$ is a partial description of a state, which may omit information.
State and observations are almost a real-valued vector, matrix, higher-order tensor in deep RL.
- When the agent can observe the complete state of the environment, we say the environment is
fully observed. - When the agent can only see a partial observation, the environment is
partially observed(c.f. POMDP).
In practice, RL state $s$ is more appropriate to use observation $o$. Specifically, we often signal in notation that the action is conditioned on the state, when in practice, the action is conditioned on the observation because the agent does not have the access to the state. In notation, also use standard notation $s$, rather than $o$.
Action spaces
- Action space: the set of all valid actions in a given environment.
- Discrete action space: only a finite number of moves are available to the agent, e.g. Atari, Go.
- Continuous action space: actions are real-valued vectors, e.g. robot walk control.
Policies
A policy is a rule used by an agent to decide what actions to take. It is the agent’s brain. It is common to substitute the word “policy” for “agent”, e.g. saying “The policy is trying to maximize the reward”.
Deterministic policies
deterministic(denoted by $\mu$)
Tensorflow code snippet:1
2
3obs = tf.placeholder(shape=(None, obs_dim), dtype=tf.float32)
net = mlp(obs, hidden_dims=(64,64), activation=tf.tanh)
actions = tf.layers.dense(net, units=act_dim, activation=None)
where mlp represents MLP layers.
Stochastic policies
stochastic(denoted by $\pi$)
Two most common kinds of stochastic policies:
Categorical policies
- used in discrete action spaces
A categorical policy is like a classifier over discrete actions:
build the NN (the same as a classifier): input is the observation, followed by some layers (CNNs FC layers, depending on the kind of input). Then one dense layer gives the logits for each action, followed by a softmax to convert the logits to probabilities.
Sampling: Given probabilities for each action, frameworks like tensorflow has builtin tools for sampling. E.g.
tf.distributions.Categoricalortf.multinomialLog-likelihood: Denote the last layer of probabilities as . Treat the actions as the indices of the vector. The log likeligood for an action $a$ can then be obtained by indexing into the vector.
Diagonal Gaussian policies
- used in continuous action spaces
A diagonal Gaussian distribution is a special case of multivariate Gaussians where the covariance matrix only has entries on the diagonal, which can be represented as a vector.
NN maps from observations to mean actions, , in two different ways:
- The first way: there is a single vector of log standard deviations, $\text{log} \sigma$ are standalone parameters.
- The second way: NN maps from states to log standard deviations, . It may optionally share some layers with the mean network.
Both output log standard deviations instead of std deviations directly. Since log stds are free to take any values in $(-\infty, \infty)$, while stds must be non-negative. It’s easier to train parameters without such constraints.
Sampling: Given the mean action and std deviation , and a vector $z$ of noise from a spherical Gaussian $(z \sim ~ \mathcal{N}(0, \mathcal{I}))$, an action sample can be computed:
where $\odot$ denotes the element-wise product.
Log-likelihood: the log-likelihood of a $k$-dimensional action $a$, for a diagonal Gaussian with mean and std dev is:
Parameterized policies:
In deep RL, policies whose output are computable functions that depend on a set of parameters (e.g. the weights and biases in NNs).
Let $\theta$ or $\phi$ denotes the parameters, written as a subscript:
Trajectories(a.k.a Episodes, Rollouts)
A trajectory $\tau$ is a sequence of states and actions in the world:
The very first state of the world, is randomly sampled from the start-state distribution, sometimes denoted by
State transitions are governed by the natural laws of the environment, and depend only the most recent action . It is either deterministic,
or stochastic
Reward and return
The reward function $R$ depends on the current state of the world, the action just taken, and the next state of the world:
Although frequently this is simplified to just a dependence on the current state, , or state-action pair
The goal of the agent is to maximize some notation of cumulative reward over a trajectory, $R(\tau)$.
Two kinds of returns:
- Finite-horizon undiscounted return: the sum of rewards obtained in a fixed window of steps:
Infinite-horizon discounted return: the sumof all rewards ever obtained by the agent, but discounted by how far off in the future they’re obtained. This includes a discounted factor $\gamma \in (0,1)$:
- Intuition: “cash now is better than cash later”
- Mathematically: more convenient to converge. An infinite-horizon sum of rewards may not converge to a finite value, and is hard to deal with in equations. But with a discount factor and under reasonable conditions, the infinite sum converges.
The RL Problem
Whatever the choice of return measure and policy, the goal of RL is to select a policy which maximize expected return when the agent acts accordingly.
Let us suppose the environment transitions and the policy are stochastic. The probability of a $T$-step trajectory is:
The expected return denoted by $J(\pi)$ is:
The central optimization problem in RL is expressed as:
where being the optimal policy
Value Functions
Q-function
- Q-function: total reward from taking in
Value function
- Value function: total reward from
is the RL objective!
Idea: compute gradient to increase the probability of good actions a:
- If , then $\pmb{a}$ is better than average. (recall under )
- modify to increase the probability of $\pmb{a}$ if
By value, we mean the expected return if you start in that state or state-action pair, and then act according to a particular policy forever after. Value functions are used in almost every RL algorithm.
Four main functions:
On-policy value function, $V^\pi(s)$: give the expected return if you start in state $s$ and always act according to policy $\pi$
On-policy action-value function, $Q^\pi(s,a)$: gives the expected return if you start in state $s$, take an arbitrary action $a$, and then forever after act according to policy $\pi$:
- Optimal value function, $V^(s)$: give the expected reutrn if you *start in state $s$, and always act according to the optimal policy in the environment:
- Optimal action-value function, $Q^(s,a)$: give the expected return if you start in state $s$, take and arbitrary action $a$, and then forever after act according to the optimal* policy in the environment:
The optimal Q-function and the optimal action
Bellman equations
Basic idea: the value of your starting point is the reward you expect to get from being there, plus the value of wherever you land next.
Bellman equation for the on-policy value functions:
where $s’ \sim P$ is shorthand for $s’ \sim P(\cdot \vert s,a)$, indicating that the next state $s’$ is sampled from the environment’s transition rules; $a \sim \pi$ is shorthand for $a \sim \pi(\cdot \vert s)$ and $a’ \sim \pi$ is shorthand for $a’ \sim \pi(\cdot \vert s’)$
- Bellman equation for the optimal value functions:
Difference between the Bellman equations for the on-policy value functions and the optimal value functions: the absence or presence of the $\max$ over actions.
Advantage functions
Intuition: In RL, we want to know how much better it is than other on average, i.e the relative advantage of that action.
The advantage function $A^\pi (s,a)$ corresponding to a policy $\pi$ describes how much better it is to take a specific action $a$ in state $s$, over randomly selecting an action according to , assuming you act according to $\pi$ forever after.
Markov Decision Process
An MDP is a 5-tuple , where
- $S$ is the set of all valid states
- $A$ is the set of all valid actions
- $R$: $S \times A \times S \rightarrow \mathbb{R}$ is the reward function, with
- $P$: $S \times A \rightarrow \mathcal{P}(S)$ is the transition probability function, with $P(S’ \vert s,a)$ being the prob of transitioning into state $s’$ if you start in state $s$ and take action $a$
- is the starting state distribution.
Markov property:
- transitions only depend on the most recent state and action, and no prior history.