1. Very long sequence. 2. Less meaningful individual tokens
subword-based
WordPiece BPE Unigram
1.Good balance the vocabulary size and the sequence length; 2.Help identify similar syntactic or semantic situations in texts; 3.Can identify start of word tokens.
Need training additional subword tokenizer.
Why subword?
Subword-based tokenization lies between character- and word-based tokenization, which arises from the idea that:
Frequently used words should not be split into smaller subwords; Rare words should be decomposed into meaningful subwords.
Subwords help identify similar syntactic or semantic situations in texts, such as same prefix or sufix.
Subword tokenization can identify start of word tokens, such as “##” in WordPiece (BERT).
Summary
It can be seen from the table that:
OpenAI and Facebook favor BPE tokenization whereas Google prefers self-proposed WordPiece and Unigram methods. ;)
Model
Tokenization
#Vocab
Corpus
Org.
GPT
BPE [Spacy/ftfy pre-tokenizer]
40,478
BooksCorpus
OpenAI
GPT-2
BBPE
50,257
WebText (40GB)
OpenAI
GPT-3
BBPE
50,257
Common Crawl, WebText2, Books1/2, Wikipedia
OpenAI
GPT-4
BBPE
100,256
Public corpus, third-party data
OpenAI
GPT-4o
BBPE
200k
-
OpenAI
Gemini
BPE
256k
A large sample of the entire training corpus.
Google
code-davinci-001/002
BBPE
50,281
-
OpenAI
text-davinci-003
BBPE
50,281
-
OpenAI
gpt-3.5-turbo
BBPE
100,256
-
OpenAI
RoBERTa
BBPE
50,257
BooksCorpus, enwiki
Facebook
BART
BBPE
50,257
BooksCorpus, enwiki
Facebook
BERT
WordPiece (30k)
30k
BooksCorpus, enwiki
Google
T5
WordPiece (spm)
32k
C4
Google
XLNet
Unigram (spm)
32k
BooksCorpus, enwiki, Giga5, ClueWeb 201-B, Common Crawl
Google
ELECTRA
WordPiece
30k
base: same as BERT; large: same as XLNet
Google
ALBERT
Unigram (spm)
30k
BooksCorpus, enwiki
Google
Gopher
Unigram (spm)
32k
MassiveText
DeepMind
Chinchilla
Unigram (spm)
32k
MassiveText
DeepMind
PaLM
Unigram (spm)
256k
dataset from LamDA, GLaM, and code
Google
LaMDA
BPE (spm)
32k
2.97B documents, 1.12B dialogs, and 13.39B dialog utterances.
Google
Galactica
BPE
50k
Papers, reference material, encyclopedias and other scientific sources
WordPiece $\Uparrow$(probability-based)merges tokens based on bigram likelihood. It uses a language model to evaluate the likelihood of subword pair mergence during each iteration, incrementally merging the neighbor unit pairs.
Byte Pair Encoding (BPE) $\Uparrow$(frequency-based)merges tokens based on bigram frequency. It uses the subword pair co-occurrence to greedily merge neighbor pairs, which can effiectively balance the vocabulary size and the sequence length. It is based on the greedy longest-match-first algorithm (deterministic symbol replacement), which cannot generate multiple segmentations with probabilities.
Unigram Language Model $\Downarrow$(subword regularization)prunes tokens based on unigram LM perplexity, which can be viewed as a probabilistic mixture of characters, subwords, and word segmentations, where the mixture probabiilty is computed using EM algorithm. It reduces the subword using a unigram LM with likelihood reduction.
Tokenization
#Vocab
Update method
New symbols
WordPiece
↑
Bottom-up merge
✔
BPE
↑
Bottom-up merge
✔
Unigram
↓
Prune
✘
Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE)[8] firstly adopts a pre-tokenizer to split the text sequence into words, then curates a base vocabulary consisting of all character symbol sets in the training data for frequency-based merge.
Pre-tokenization The pre-tokenization can be:
Space tokenization, e.g. GPT-2, RoBERTa.
Rule-based tokenization (Moses), e.g. XLM.
Spacy and ftfy: GPT.
Frequency-based Merge Starting with the base vocabulary, BPE counts the frequency of each neighbor pair and selects the unit pair that occurs most frequently to the base vocabulary. Then it searches for the next unit pair that occurs the most frequently.
# count the frequency of all adjacent symbol pairs (bigrams) in the vocabulary defget_stats(vocab): pairs = collections.defaultdict(int) # Dictionary to store bigram frequencies for word, freq in vocab.items(): symbols = word.split() # Split the word into a list of symbols for i inrange(len(symbols) - 1): # Count the frequency of each bigram pairs[symbols[i], symbols[i + 1]] += freq return pairs
# Function to merge the most frequent bigram into a single symbol in the vocabulary defmerge_vocab(pair, v_in): v_out = {} # New vocabulary after merging bigram = re.escape(' '.join(pair)) # Escape special characters for regex # Compile a regex pattern to match the bigram only when it appears as a standalone pair p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') for word in v_in: # Replace the matched bigram with the merged symbol w_out = p.sub(''.join(pair), word) v_out[w_out] = v_in[word] # Update the new vocabulary return v_out
# Initial vocabulary with words and their frequencies vocab = { 'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3 }
# Number of merges to perform num_merges = 10
# Perform BPE merges iteratively for i inrange(num_merges): pairs = get_stats(vocab) # Get frequencies of all bigrams ifnot pairs: break# Stop if no more pairs can be merged best = max(pairs, key=pairs.get) # Find the most frequent bigram vocab = merge_vocab(best, vocab) # Merge the bigram and update the vocabulary print(f"Merge {i + 1}: Merge pair {best} -> New vocab: {vocab}")
# Print the final vocabulary print("\nFinal vocabulary:") for word, freq in vocab.items(): print(f"{word}: {freq}")
Unicode: Unicode is an encoding for textual characters which is able to represent characters from different languages. Each character is represented by a unicode code point. Unicode consists of a total of 137,929 characters.
Byte: 8 bits is called a byte. One byte character set can contain 256 characters.
Unicode code point contains 130k+ points to cover the full space of textual characters, which can increase the base vocabulary size of BPE. Thus, Applying BPE to the byte sequence of language is a great idea proposed in GPT-2[14] to reduce the vocabulary size. However, directly applying byte-level BPE can result in suboptimum because the greedy frequency-based heuristic in BPE tend to merge common words into neighbors to generate overfit sub-tokens, such as “-ing.”, “-ing!”, “-ing?”.
To avoid this, GPT-2[14] prevents BPE from merging across different character categories for any byte sequence except space. With byte-level subwords, BBPE can represent any texts using moderate vocabulary size without out-of-vocabulary problem. Moreover, it will increase the byte sequence length to x4 maximum.
BBPE
The base vocabulary contains all possible base characters in the training data. It can become large if all unicode characters are included. Thus, GPT-2[14] used Byte-level BPE (BBPE) by resorting to byte sequence of texts instead of unicode character strings for base vocabulary construction. It is also adopted by RoBERTa, BART, GPT-2, and GPT-3.
Vocabulary Size The final vocabulary size is the size of base vocabulary plus the # of merges, where the # of merges is a hyperparameter. For instance,
GPT (character-level BPE) has 40,478 vocabularies: 478 base vocabularies + 40k merges.
GPT-2 (byte-level BPE) has 50,257 vocabularies: 256 base vocabularies + 1 [EOS] token + 50k merges.
""" GPT-2 & RoBERTa Byte pair encoding utilities from GPT-2. Original source: https://github.com/openai/gpt-2/blob/master/src/encoder.py Original license: MIT """
import json from functools import lru_cache
@lru_cache() defbytes_to_unicode(): """ Returns list of utf-8 byte and a corresponding list of unicode strings. The reversible bpe codes work on unicode strings. This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. This is a signficant percentage of your normal, say, 32K bpe vocab. To avoid that, we want lookup tables between utf-8 bytes and unicode strings. And avoids mapping to whitespace/control characters the bpe code barfs on. """ bs = ( list(range(ord("!"), ord("~") + 1)) + list(range(ord("¡"), ord("¬") + 1)) + list(range(ord("®"), ord("ÿ") + 1)) ) cs = bs[:] n = 0 for b inrange(2 ** 8): if b notin bs: bs.append(b) cs.append(2 ** 8 + n) n += 1 cs = [chr(n) for n in cs] returndict(zip(bs, cs))
defget_pairs(word): """Return set of symbol pairs in a word. Word is represented as tuple of symbols (symbols being variable-length strings). """ pairs = set() prev_char = word[0] for char in word[1:]: pairs.add((prev_char, char)) prev_char = char return pairs
classEncoder: def__init__(self, encoder, bpe_merges, errors="replace"): self.encoder = encoder # bpe-vocab.json -> {subword:id} self.decoder = {v: k for k, v in self.encoder.items()} # {id: subword} self.errors = errors # how to handle errors in decoding # {byte: unicode} self.byte_encoder = bytes_to_unicode() self.byte_decoder = {v: k for k, v in self.byte_encoder.items()} # {unicode: byte} # bpe-merges.txt -> {tuple: rank} self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges)))) self.cache = {}
try: import regex as re self.re = re except ImportError: raise ImportError("Please install regex with: pip install regex")
# Should have added re.IGNORECASE so BPE merges # can happen for capitalized versions of contractions self.pat = self.re.compile( r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""" )
defbpe(self, token): # check if already processed if token in self.cache: return self.cache[token] word = tuple(token) pairs = get_pairs(word) # count bigrams
ifnot pairs: return token
whileTrue: bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf"))) if bigram notin self.bpe_ranks: break first, second = bigram new_word = [] i = 0 # find all possible merges for a bigram while i < len(word): try: j = word.index(first, i) new_word.extend(word[i:j]) i = j except: # no further merge new_word.extend(word[i:]) break
# bigram match & satisfy length limit if word[i] == first and i < len(word) - 1and word[i + 1] == second: new_word.append(first + second) i += 2 else: new_word.append(word[i]) i += 1 new_word = tuple(new_word) word = new_word # update merged tokens iflen(word) == 1: break else: pairs = get_pairs(word) # new possible pairs word = " ".join(word) self.cache[token] = word # cache raw tokens return word
defencode(self, text): bpe_tokens = [] for token in self.re.findall(self.pat, text): token = "".join(self.byte_encoder[b] for b in token.encode("utf-8")) bpe_tokens.extend( self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" ") ) return bpe_tokens
defdecode(self, tokens): text = "".join([self.decoder.get(token, token) for token in tokens]) text = bytearray([self.byte_decoder[c] for c in text]).decode( "utf-8", errors=self.errors ) return text
defget_encoder(encoder_json_path:"bpe-vocab.json", vocab_bpe_path:"bpe-merge.txt"): withopen(encoder_json_path, "r") as f: encoder = json.load(f) withopen(vocab_bpe_path, "r", encoding="utf-8") as f: bpe_data = f.read() bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split("\n")[1:-1]] return Encoder( encoder=encoder, bpe_merges=bpe_merges, )
# RoBERTa source code. import argparse import contextlib import sys from collections import Counter from multiprocessing import Pool
defmain(): """ Helper script to encode raw text with the GPT-2 BPE using multiple processes. The encoder.json and vocab.bpe files can be obtained here: - https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json - https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe """ parser = argparse.ArgumentParser() parser.add_argument( "--encoder-json", help="path to encoder.json", ) parser.add_argument( "--vocab-bpe", type=str, help="path to vocab.bpe", ) parser.add_argument( "--inputs", nargs="+", default=["-"], help="input files to filter/encode", ) parser.add_argument( "--outputs", nargs="+", default=["-"], help="path to save encoded outputs", ) parser.add_argument( "--keep-empty", action="store_true", help="keep empty lines", ) parser.add_argument("--workers", type=int, default=20) args = parser.parse_args()
assertlen(args.inputs) == len( args.outputs ), "number of input and output paths should match" with contextlib.ExitStack() as stack: inputs = [ stack.enter_context(open(input, "r", encoding="utf-8")) ifinput != "-" else sys.stdin forinputin args.inputs ] outputs = [ stack.enter_context(open(output, "w", encoding="utf-8")) if output != "-" else sys.stdout for output in args.outputs ]
encoder = MultiprocessingEncoder(args) pool = Pool(args.workers, initializer=encoder.initializer) encoded_lines = pool.imap(encoder.encode_lines, zip(*inputs), 100) stats = Counter() for i, (filt, enc_lines) inenumerate(encoded_lines, start=1): if filt == "PASS": for enc_line, output_h inzip(enc_lines, outputs): print(enc_line, file=output_h) else: stats["num_filtered_" + filt] += 1 if i % 10000 == 0: print("processed {} lines".format(i), file=sys.stderr)
for k, v in stats.most_common(): print("[{}] filtered {} lines".format(k, v), file=sys.stderr)
definitializer(self): global bpe bpe = get_encoder(self.args.encoder_json, self.args.vocab_bpe)
defencode(self, line): global bpe ids = bpe.encode(line) returnlist(map(str, ids))
defdecode(self, tokens): global bpe return bpe.decode(tokens)
defencode_lines(self, lines): """ Encode a set of lines. All lines will be encoded together. """ enc_lines = [] for line in lines: line = line.strip() iflen(line) == 0andnot self.args.keep_empty: return ["EMPTY", None] tokens = self.encode(line) enc_lines.append(" ".join(tokens)) return ["PASS", enc_lines]
defdecode_lines(self, lines): dec_lines = [] for line in lines: tokens = map(int, line.strip().split()) dec_lines.append(self.decode(tokens)) return ["PASS", dec_lines]
import collections import itertools from typing importOptional
import regex
# pip3 install tiktoken>=0.4.0 import tiktoken
classSimpleBytePairEncoding: def__init__(self, *, pat_str: str, mergeable_ranks: dict[bytes, int]) -> None: """Creates an Encoding object.""" # A regex pattern string that is used to split the input text self.pat_str = pat_str # A dictionary mapping token bytes to their ranks. The ranks correspond to merge priority self.mergeable_ranks = mergeable_ranks
self._decoder = {token: token_bytes for token_bytes, token in mergeable_ranks.items()} self._pat = regex.compile(pat_str)
defencode(self, text: str, visualise: Optional[str] = "colour") -> list[int]: """Encodes a string into tokens. >>> enc.encode("hello world") [388, 372] """ # Use the regex to split the text into (approximately) words words = self._pat.findall(text) tokens = [] for word in words: # Turn each word into tokens, using the byte pair encoding algorithm word_bytes = word.encode("utf-8") word_tokens = bpe_encode(self.mergeable_ranks, word_bytes, visualise=visualise) tokens.extend(word_tokens) return tokens
defdecode_bytes(self, tokens: list[int]) -> bytes: """Decodes a list of tokens into bytes. >>> enc.decode_bytes([388, 372]) b'hello world' """ returnb"".join(self._decoder[token] for token in tokens)
defdecode(self, tokens: list[int]) -> str: """Decodes a list of tokens into a string. Decoded bytes are not guaranteed to be valid UTF-8. In that case, we replace the invalid bytes with the replacement character "�". >>> enc.decode([388, 372]) 'hello world' """ return self.decode_bytes(tokens).decode("utf-8", errors="replace")
defdecode_tokens_bytes(self, tokens: list[int]) -> list[bytes]: """Decodes a list of tokens into a list of bytes. Useful for visualising how a string is tokenised. >>> enc.decode_tokens_bytes([388, 372]) [b'hello', b' world'] """ return [self._decoder[token] for token in tokens]
@staticmethod deftrain(training_data: str, vocab_size: int, pat_str: str): """Train a BPE tokeniser on some data!""" mergeable_ranks = bpe_train(data=training_data, vocab_size=vocab_size, pat_str=pat_str) return SimpleBytePairEncoding(pat_str=pat_str, mergeable_ranks=mergeable_ranks)
defbpe_encode( mergeable_ranks: dict[bytes, int], input: bytes, visualise: Optional[str] = "colour" ) -> list[int]: parts = [bytes([b]) for b ininput] whileTrue: # See the intermediate merges play out! if visualise: if visualise in ["colour", "color"]: visualise_tokens(parts) elif visualise == "simple": print(parts)
# Iterate over all pairs and find the pair we want to merge the most min_idx = None min_rank = None for i, pair inenumerate(zip(parts[:-1], parts[1:])): rank = mergeable_ranks.get(pair[0] + pair[1]) if rank isnotNoneand (min_rank isNoneor rank < min_rank): min_idx = i min_rank = rank
# If there were no pairs we could merge, we're done! if min_rank isNone: break assert min_idx isnotNone
# Otherwise, merge that pair and leave the rest unchanged. Then repeat. parts = parts[:min_idx] + [parts[min_idx] + parts[min_idx + 1]] + parts[min_idx + 2 :]
if visualise: print()
tokens = [mergeable_ranks[part] for part in parts] return tokens
defbpe_train( data: str, vocab_size: int, pat_str: str, visualise: Optional[str] = "colour" ) -> dict[bytes, int]: # First, add tokens for each individual byte value if vocab_size < 2**8: raise ValueError("vocab_size must be at least 256, so we can encode all bytes") ranks = {} for i inrange(2**8): ranks[bytes([i])] = i
# Splinter up our data into lists of bytes # data = "Hello world" # words = [ # [b'H', b'e', b'l', b'l', b'o'], # [b' ', b'w', b'o', b'r', b'l', b'd'] # ] words: list[list[bytes]] = [ [bytes([b]) for b in word.encode("utf-8")] for word in regex.findall(pat_str, data) ]
# Now, use our data to figure out which merges we should make whilelen(ranks) < vocab_size: # Find the most common pair. This will become our next token stats = collections.Counter() for piece in words: for pair inzip(piece[:-1], piece[1:]): stats[pair] += 1
# Now merge that most common pair in all the words. That is, update our training data # to reflect our decision to make that pair into a new token. new_words = [] for word in words: new_word = [] i = 0 while i < len(word) - 1: if (word[i], word[i + 1]) == most_common_pair: # We found our pair! Merge it new_word.append(token_bytes) i += 2 else: new_word.append(word[i]) i += 1 if i == len(word) - 1: new_word.append(word[i]) new_words.append(new_word) words = new_words
# See the intermediate merges play out! if visualise: print(f"The current most common pair is {most_common_pair[0]} + {most_common_pair[1]}") print(f"So we made {token_bytes} our {len(ranks)}th token") if visualise in ["colour", "color"]: print("Now the first fifty words in our training data look like:") visualise_tokens([token for word in words[:50] for token in word]) elif visualise == "simple": print("Now the first twenty words in our training data look like:") for word in words[:20]: print(word) print("\n")
return ranks
defvisualise_tokens(token_values: list[bytes]) -> None: backgrounds = itertools.cycle( [f"\u001b[48;5;{i}m".encode() for i in [167, 179, 185, 77, 80, 68, 134]] ) interleaved = itertools.chain.from_iterable(zip(backgrounds, token_values)) print((b"".join(interleaved) + "\u001b[0m".encode()).decode("utf-8"))
deftrain_simple_encoding(): gpt2_pattern = ( r"""'s|'t|'re|'ve|'m|'ll|'d| ?[\p{L}]+| ?[\p{N}]+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""" ) withopen(__file__, "r") as f: data = f.read()
print("This is the sequence of merges performed in order to encode 'hello world':") tokens = enc.encode("hello world") assert enc.decode(tokens) == "hello world" assert enc.decode_bytes(tokens) == b"hello world" assert enc.decode_tokens_bytes(tokens) == [b"hello", b" world"]
return enc
# Train a BPE tokeniser on a small amount of text enc = train_simple_encoding()
# Visualise how the GPT-4 encoder encodes text enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base") y = enc.encode("hello world aaaaaaaaaaaa") print(f"{y}")
WordPiece
WordPiece[9][10] can be viewed as a language-modeling based BPE variant. It trains with similar process to the BPE but uses disparate merge rule: WordPiece select the unit pair that maximizes the likelihood of training data at utmost, rather than choose the most frequent pair. WordPiece chooses the subword pair that has the maximum mutual information value.
WordPiece scores the likelihood of possible pairs using an n-gram LM. [9] mentioned that training LMs for every possible merge is prohibit, they used aggressive heuristics to reduce the budget. However, the public training implementation is unavailable.
The BERT tokenization applies two tokenizers one after another:
BasicTokenizer:
Convert text to unicode.
Clean text: invalid character removal and whitespace cleanup.
Use whitespace to seperate Chinese characters.
Whitespace tokenization.
Lowercase & Strips accents.
Split punctuations.
WordpieceTokenizer:
Convert texts to unicode.
Apply WordPiece, a greedy longest-match-first algorithm to perform tokenization given vocabulary.
All Chinese inputs are split into characters as if no wordpiece applied.
def__init__(self, vocab_file, do_lower_case=True): self.vocab = load_vocab(vocab_file) self.inv_vocab = {v: k for k, v in self.vocab.items()} self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case) self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
deftokenize(self, text): split_tokens = [] for token in self.basic_tokenizer.tokenize(text): for sub_token in self.wordpiece_tokenizer.tokenize(token): split_tokens.append(sub_token)
def__init__(self, do_lower_case=True): """Constructs a BasicTokenizer. Args: do_lower_case: Whether to lower case the input. """ self.do_lower_case = do_lower_case
deftokenize(self, text): """Tokenizes a piece of text.""" text = convert_to_unicode(text) text = self._clean_text(text)
# This was added on November 1st, 2018 for the multilingual and Chinese # models. This is also applied to the English models now, but it doesn't # matter since the English models were not trained on any Chinese data # and generally don't have any Chinese data in them (there are Chinese # characters in the vocabulary because Wikipedia does have some Chinese # words in the English Wikipedia.). text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text) split_tokens = [] for token in orig_tokens: if self.do_lower_case: token = token.lower() token = self._run_strip_accents(token) split_tokens.extend(self._run_split_on_punc(token))
def_run_strip_accents(self, text): """Strips accents from a piece of text.""" text = unicodedata.normalize("NFD", text) output = [] for char in text: cat = unicodedata.category(char) if cat == "Mn": continue output.append(char) return"".join(output)
def_run_split_on_punc(self, text): """Splits punctuation on a piece of text.""" chars = list(text) i = 0 start_new_word = True output = [] while i < len(chars): char = chars[i] if _is_punctuation(char): output.append([char]) start_new_word = True else: if start_new_word: output.append([]) start_new_word = False output[-1].append(char) i += 1
return ["".join(x) for x in output]
def_tokenize_chinese_chars(self, text): """Adds whitespace around any CJK character.""" output = [] for char in text: cp = ord(char) if self._is_chinese_char(cp): output.append(" ") output.append(char) output.append(" ") else: output.append(char) return"".join(output)
def_is_chinese_char(self, cp): """Checks whether CP is the codepoint of a CJK character.""" # This defines a "chinese character" as anything in the CJK Unicode block: # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block) # # Note that the CJK Unicode block is NOT all Japanese and Korean characters, # despite its name. The modern Korean Hangul alphabet is a different block, # as is Japanese Hiragana and Katakana. Those alphabets are used to write # space-separated words, so they are not treated specially and handled # like the all of the other languages. if ((cp >= 0x4E00and cp <= 0x9FFF) or# (cp >= 0x3400and cp <= 0x4DBF) or# (cp >= 0x20000and cp <= 0x2A6DF) or# (cp >= 0x2A700and cp <= 0x2B73F) or# (cp >= 0x2B740and cp <= 0x2B81F) or# (cp >= 0x2B820and cp <= 0x2CEAF) or (cp >= 0xF900and cp <= 0xFAFF) or# (cp >= 0x2F800and cp <= 0x2FA1F)): # returnTrue
returnFalse
def_clean_text(self, text): """Performs invalid character removal and whitespace cleanup on text.""" output = [] for char in text: cp = ord(char) if cp == 0or cp == 0xfffdor _is_control(char): continue if _is_whitespace(char): output.append(" ") else: output.append(char) return"".join(output)
deftokenize(self, text): """Tokenizes a piece of text into its word pieces. This uses a greedy longest-match-first algorithm to perform tokenization using the given vocabulary. For example: input = "unaffable" output = ["un", "##aff", "##able"] Args: text: A single token or whitespace separated tokens. This should have already been passed through `BasicTokenizer. Returns: A list of wordpiece tokens. """
text = convert_to_unicode(text)
output_tokens = [] for token in whitespace_tokenize(text): chars = list(token) iflen(chars) > self.max_input_chars_per_word: output_tokens.append(self.unk_token) continue
is_bad = False start = 0 sub_tokens = [] while start < len(chars): end = len(chars) cur_substr = None while start < end: substr = "".join(chars[start:end]) if start > 0: substr = "##" + substr if substr in self.vocab: cur_substr = substr break end -= 1 if cur_substr isNone: is_bad = True break sub_tokens.append(cur_substr) start = end
if is_bad: output_tokens.append(self.unk_token) else: output_tokens.extend(sub_tokens) return output_tokens
def_is_whitespace(char): """Checks whether `chars` is a whitespace character.""" # \t, \n, and \r are technically contorl characters but we treat them # as whitespace since they are generally considered as such. if char == " "or char == "\t"or char == "\n"or char == "\r": returnTrue cat = unicodedata.category(char) if cat == "Zs": returnTrue returnFalse
def_is_control(char): """Checks whether `chars` is a control character.""" # These are technically control characters but we count them as whitespace # characters. if char == "\t"or char == "\n"or char == "\r": returnFalse cat = unicodedata.category(char) if cat in ("Cc", "Cf"): returnTrue returnFalse
def_is_punctuation(char): """Checks whether `chars` is a punctuation character.""" cp = ord(char) # We treat all non-letter/number ASCII as punctuation. # Characters such as "^", "$", and "`" are not in the Unicode # Punctuation class but we treat them as punctuation anyways, for # consistency. if ((cp >= 33and cp <= 47) or (cp >= 58and cp <= 64) or (cp >= 91and cp <= 96) or (cp >= 123and cp <= 126)): returnTrue cat = unicodedata.category(char) if cat.startswith("P"): returnTrue returnFalse
if __name__ == "__main__": vocab_file="./cased_L-12_H-768_A-12/vocab.txt" tokenizer = FullTokenizer(vocab_file=vocab_file, do_lower_case=True) output_tokens = tokenizer.tokenize("""This text is included to make sure Unicode is handled properly: 力加勝北区ᴵᴺᵀᵃছজটডণত""")
Unigram Language Model
Unigram Language Model[11] initializes its base vocabulary with a large # of vocabulary and gradually removes a portion (e.g., 20%) of units according to the likelihood change. It use a unigram LM to evaluate the likelihood increase after subword removal, where the probability of each unit is computed using EM algorithm. The drop process will stop until reach the pre-defined vocabulary size.
Since unigram is not based on merge rules (in contrast to BPE and WordPiece), there has several ways of tokenizing new text after training. Therefore, unigram also saves the probability of each token in the training corpus on top of saving the vocabulary so that the probability of each possible tokenization can be computed after training. It simply picks the most likely tokenization in practice, but also offers the possibility to sample a possible tokenization according to their possibilities.
Assume that the set of all possible tokenizations for a word $x_i$ is defined as $S(x_i)$, the overall loss is defined as:
import re import os import collections import numpy as np from scipy.special import digamma
# To efficiently determine the next possible words # We need a Trie data structure classTrie: def__init__(self): self.root = {}
defadd(self, word, value): node = self.root for ch in word: if ch notin node: node[ch] = {} node = node[ch] node['<END>'] = value
defget_value(self, word): node = self.root for ch in word: if ch notin node: return0 node = node[ch] if'<END>'notin node: return0 return node['<END>']
defset_value(self, word, value): node = self.root for ch in word: if ch notin node: raise ValueError("word not in trie") node = node[ch] if'<END>'notin node: raise ValueError("word not in trie") node['<END>'] = value
maxlen = 0 for tok, val in tokens.items(): trie.add(tok, digamma(val)-logsum) maxlen = max(maxlen, len(tok))
return trie, maxlen
defforward_step(self, text, trie): N = len(text)
# d[i] contains the maximum log_prob of any tokenization # of text[:i], initialized to 0 (i.e. log(0)=-infty) d = [-np.inf]*(N+1)
# p[i] (stands for parent) contains the number of characters of # the final token in the most likely sequence that ends at index i p = [None]*(N+1) d[0]=0
for i inrange(1, N+1):
# find all possible final words. Have to look back # a distance set by the length of the longest token for j inrange(max(i-self.maxlen, 0), i):
# if the current ending word has a higher log-probability, # save that value and store the word (i.e. # chars to backtrack) if final_value and d[j]+final_value > d[i]: d[i] = d[j]+final_value p[i] = len(final_token) if p[i] isNone: raise ValueError(f"Encountered unknown token '{text[i-1]}'.")
loss = d[-1] return loss, p
defbackward_step(self, text, p): idx = len(p) tokenization = [] while idx > 1: # move back the number of steps p tells you to next_idx = idx-p[idx-1]
# extract the final token tok = text[next_idx-1:idx-1] tokenization.append(tok)
defE_step(self, tokenization, trie): # get the new token counts based on updated tokenization counts = collections.Counter(tokenization) norm = sum(list(counts.values()))
# Bayesianify them: https://cs.stanford.edu/~pliang/papers/tutorial-acl2007-talk.pdf # https://github.com/google/sentencepiece/blob/master/src/unigram_model_trainer.cc # we are returning the log probabilties here (alpha=0 prior) logsum = digamma(norm) for k, v in counts.items(): counts[k] = digamma(v)-logsum
for k, v in counts.items(): trie.set_value(k, v) return trie
defM_step(self, text, trie): loss, p = self.forward_step(text, trie) tokenization = self.backward_step(text, p) return tokenization, loss
defprune_tokens(self, tokens, characters, vocab_size, trim_frac=0.2): """ Tokens are passed by reference and modified in place. Returns: True: to indicate to caller that more rounds are needed False: to indicate we successfully hit the target vocab size ValueError: if the vocab size cannot be reached.""" sorted_tokens = tokens.most_common() N = len(sorted_tokens) n_trim = int(trim_frac*N) for i inreversed(range(N)): if N <= vocab_size: returnFalse if n_trim <= 0: returnTrue tok = sorted_tokens[i][0] if tok notin characters: self.trie.set_value(tok, 0) # we need to delete it from the trie (that sticks around) tokens.pop(tok) # also need to delete from tokens, so the next round doesn't see it n_trim -= 1 N -= 1 if n_trim > 0: raise ValueError('Could not reduce tokens further. Please increase vocab size') returnFalse
deffit(self, text, tokens, characters, vocab_size, delta=0.01, max_iter=5, max_rounds=5): """ To turn off pruning, just set max_rounds=1 """ text = re.sub(' ', '_', text) if vocab_size > len(tokens): raise ValueError(f"Vocab size is larger than the availble number of tokens {len(tokens)}.") self.trie, self.maxlen = self._initialize_trie(tokens) for i inrange(1, max_rounds+1): print(f"--- Round {i}. Vocab size: {len(tokens)} ---") self.EM_round(text, tokens, delta, max_iter) ifnot self.prune_tokens(tokens, characters, vocab_size): break self.vocab_size = len(tokens)
defgeneralized_forward_step(self, text, trie, nbest_size=1): N = len(text) d = [-np.inf]*(N+1) p = [None]*(N+1) d[0]=0 for i inrange(1, N+1): d_queue = [] p_queue = [] for j inrange(max(i-self.maxlen, 0), i): final_token = text[j:i] final_value = trie.get_value(final_token) if final_value: curr_d = d[j]+final_value curr_p = len(final_token) d[i] = max(d[i], curr_d) d_queue.append(curr_d) p_queue.append(curr_p) ids = np.argsort(d_queue)[-nbest_size:] p[i] = [p_queue[z] for z in ids] return p
deftokenize(self, text, nbest_size=1): text = re.sub(' ', '_', text) if self.trie isNone: raise ValueError("Trainer has not yet been fit. Cannot tokenize.") p = self.generalized_forward_step(text, self.trie, nbest_size) tokenization = self.generalized_backward_step(text, p) return tokenization
SentencePiece[12][17] includes the space in the base vocabulary then use BPE or unigram algorithm to tokenize. XLNet, T5, ALBERT use SentencePiece for subword tokenization. It uses the unigram by default.
1 2 3 4 5 6 7 8
# SentencePiece --byte_fallback: (type: bool, default: false) decompose unknown pieces into UTF-8 byte pieces. Note: need to set --character_coverage less than 1.0, otherwise byte-fall-backed tokens may not appear in the training data. --character_coverage: (type: double; default:0.9995) character coverage of determining the minimal symbols. # see: https://github.com/google/sentencepiece/blob/master/doc/options.md
Pros:
C++ implementations makes it blazingly fast to tokenize.
It is whitespace agnostic, supporting to train non-whitespace delineated languages, such as Chinese and Japanese with the same ease as English or French.[18]
It works at the byte level.
Basic usage
1 2 3
# env / data pip install sentencepiece wget https://raw.githubusercontent.com/google/sentencepiece/master/data/botchan.txt
# train sentencepiece model from `botchan.txt` and makes `m.model` and `m.vocab` # `m.vocab` is just a reference. not used in the segmentation. spm.SentencePieceTrainer.train('--input=botchan.txt --model_prefix=m --vocab_size=2000')
# makes segmenter instance and loads the model file (m.model) sp = spm.SentencePieceProcessor() sp.load('m.model')
# encode: text => id print(sp.encode_as_pieces('This is a test')) print(sp.encode_as_ids('This is a test'))
# decode: id => text print(sp.decode_pieces(['▁This', '▁is', '▁a', '▁t', 'est'])) print(sp.decode_ids([209, 31, 9, 375, 586]))
# returns vocab size print(sp.get_piece_size())
# id <=> piece conversion print(sp.id_to_piece(209)) print(sp.piece_to_id('▁This'))
# returns 0 for unknown tokens (we can change the id for UNK) print(sp.piece_to_id('__MUST_BE_UNKNOWN__'))
# <unk>, <s>, </s> are defined by default. Their ids are (0, 1, 2) # <s> and </s> are defined as 'control' symbol. foridinrange(3): print(sp.id_to_piece(id), sp.is_control(id))
User defined and control symbols
1 2 3 4 5 6 7 8 9 10 11 12 13 14
## Example of user defined symbols spm.SentencePieceTrainer.train('--input=botchan.txt --model_prefix=m_user --user_defined_symbols=<sep>,<cls> --vocab_size=2000')
# ids are reserved in both mode. # <unk>=0, <s>=1, </s>=2, <sep>=3, <cls>=4 # user defined symbols allow these symbol to apper in the text. print(sp_user.encode_as_pieces('this is a test<sep> hello world<cls>')) print(sp_user.piece_to_id('<sep>')) # 3 print(sp_user.piece_to_id('<cls>')) # 4 print('3=', sp_user.decode_ids([3])) # decoded to <sep> print('4=', sp_user.decode_ids([4])) # decoded to <cls>
Unigram: sampling and nbest segmentation for subword regularization
When --model_type=unigram (default) is used, we can perform sampling and n-best segmentation for data augmentation. See subword regularization paper[11] for more detail. nbest_size is the number of highest-ranked groups of tokens to sample from at each time, where -1 means all of the possibilities.
# Can obtain different segmentations per request. # There are two hyperparamenters for sampling (nbest_size and inverse temperature). see the paper [kudo18] for detail. for n inrange(10): print(sp.sample_encode_as_pieces('hello world', -1, 0.1)) for n inrange(10): print(sp.sample_encode_as_ids('hello world', -1, 0.1))
1 2 3 4
# sample for _ inrange(10): result = sp.encode('This is a test', out_type=str, enable_sampling=True, alpha=0.1, nbest_size=-1) print(result)
1 2 3
# get 10 best print(sp.nbest_encode_as_pieces('hello world', 10)) print(sp.nbest_encode_as_ids('hello world', 10))
BPE model
Sentencepiece also supports BPE (byte pair encoding) model by setting --model_type=bpe. The BPE model does not support sampling and n-best segmentation.
Sentencepiece supports character and word segmentation with --model_type=char and --model_type=character flags. In word segmentation, sentencepiece just segments tokens with whitespaces, so the input text must be pre-tokenized. We can apply different segmentation algorithm transparently without changing pre/post processors.
1 2 3 4 5 6 7 8
# char model spm.SentencePieceTrainer.train('--input=botchan.txt --model_prefix=m_char --model_type=char --vocab_size=400')
sp = spm.SentencePieceProcessor() # m.model embeds the normalization rule compiled into an FST. sp.load('m.model') print(sp.encode_as_pieces("I'm busy")) # normalzied to `I am busy' print(sp.encode_as_pieces("I don't know it.")) # normalized to 'I do not know it.'
Vocabulary restriction
We can encode the text only using the tokens specified with set_vocabulary method.
# Gets all tokens as Python list. vocabs = [sp.id_to_piece(id) foridinrange(sp.get_piece_size())]
# Aggregates the frequency of each token in the training data. freq = {} withopen('botchan.txt', 'r') as f: for line in f: line = line.rstrip() for piece in sp.encode_as_pieces(line): freq.setdefault(piece, 0) freq[piece] += 1 # only uses the token appearing more than 1000 times in the training data. vocabs = list(filter(lambda x : x in freq and freq[x] > 1000, vocabs)) sp.set_vocabulary(vocabs) print(sp.encode_as_pieces('this is a test.'))
# reset the restriction sp.reset_vocabulary() print(sp.encode_as_pieces('this is a test.'))
Extracting crossing-words pieces
Sentencepieces does not extract pieces crossing multiple words (here the word means the space delimited tokens). The piece will never contain the whitespace marker (_) in the middle.
--split_by_whtespace=false disables this restriction and allows to extract pieces crossing multiple words. In CJK (Chinese/Japanese/Korean), this flag will not affect the final segmentation results so much as words are not tokenized with whitespaces in CJK.
# Gets all tokens as Python list. vocabs = [sp.id_to_piece(id) foridinrange(sp.get_piece_size())]
for piece in vocabs[0:500]: if re.match('\w+▁\w+', piece): print(piece)
Getting byte offsets of tokens
Sentencepiece keeps track of byte offset (span) of each token, which is useful for highlighting the token on top of unnormalized text.
We first need to install protobuf module and sentencepiece_pb2.py as the byte offsets and all other meta data for segementation are encoded in protocol buffer. encode_as_serialized_proto method resturns serialized SentencePieceText proto. You can get the deserialized object by calling ParseFromString method.
For the need of expanding new special tokens to pre-trained sentencepiece model, such as [MASK0-99], [DOMAIN0-99], and so on. Ref: [19]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
## Run this code in google/sentencepiece/python/ # Load pre-trained sentencepiece model import sentencepiece_model_pb2 as model m = model.ModelProto() m.ParseFromString(open("old.model", "rb").read())
# Prepare the list of new tokens want to add special_tokens = open("special_tokens.txt", "r").read().split("\n")
# Add new tokens to sentencepiece model for token in special_tokens: new_token = model.ModelProto().SentencePiece() new_token.piece = token new_token.score = 0 m.pieces.append(new_token) # Save new sentencepiece model withopen('new.model', 'wb') as f: f.write(m.SerializeToString())
--remove_extra_whitespaces=false # In addition, newlines are all normalized whitespaces internally by default. You can stop all normalizations with --normalization_rule_name=identity
% cd src % protoc --python_out=. sentencepiece_model.proto
>>> import sentencepiece_model_pb2 as model >>> m = model.ModelProto() >>> m.ParseFromString(open('../python/test/test_ja_model.model', 'rb').read()) 352301 >>> for p in m.pieces: ... p.score += 10.0 ... >>> with open('new.model', 'wb') as f: ... f.write(m.SerializeToString())
Unigram aligns better than char-based BPE does in morphology.[15] argued that Unigram LM tokenization can recover subword units that align with morphology much better than BPE do, using SentencePiece[12] implementation on English and Japanese Wikipedia.
It can be seen from the below figure that Unigram tends to produce longer subword units than BPE on average and have more tokens of moderate frequency.
As shown in the table, BPE tokenization tends to merge common tokens, such as English inflectional suffixes and Japanese particles, into their neighbors even though resulting units are not semantically meaningful. This may be due to the greedy construction of BPE tokenization.
[15] found that segmentations produced by Unigram LM align more closely to the morphological references in both English and Japanese.
Models using Unigram outperform counterparts using BPE in finetuning downstream tasks.[15] claimed that fine-tuning models pretrained with unigram LM tokenization produces better performance than with BPE tokenization for experimented tasks.
For attribution in academic contexts, please cite this work as:
1 2 3 4 5 6
@misc{chai2021tokenization-PTMs, author = {Chai, Yekun}, title = {{Word Tokenization for Pre-trained Models}}, year = {2021}, howpublished = {\url{https://cyk1337.github.io/notes/2021/11/29/Subword-Tokenization-in-NLP/}}, }

![BPE algorithm <small>[15]</small>](/notes/images/BPE-algorithm.png)


![Ungram LM algorithm <small>[11]</small>](/notes/images/Unigram-LM-tokenization.png)
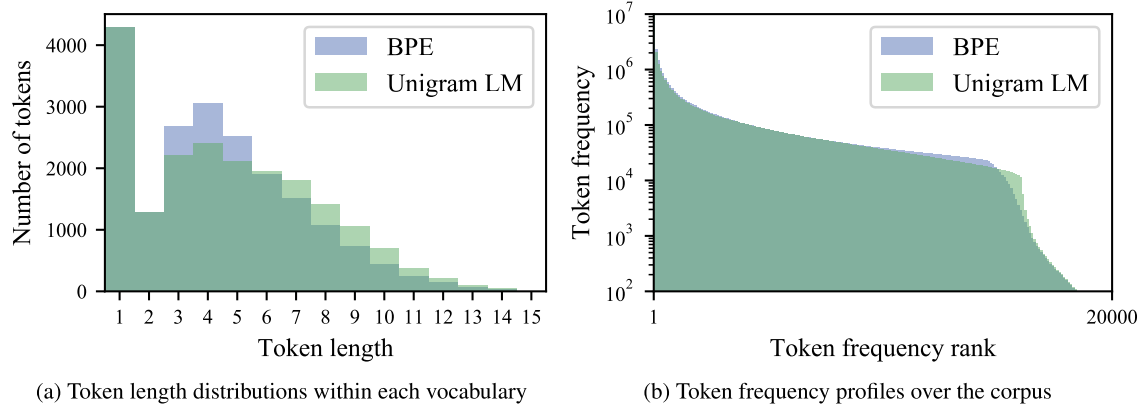
![Unigram vs char-based BPE tokenization <small>[11]</small>](/notes/images/Unigram-vs-BPE-evaluation.png)