
A summary of the automatic evaluation metric for natural language generation (NLG) applications.
The human evaluation considers the aspects of adequacy, fidelity, and fluency, but it is quite expensive.
- Adequacy: Does the output convey the same meaning as the input sentence? Is part of the message lost, added, or distorted?
- Fluency: Is the output good fluent English? This involves both grammatical correctness and idiomatic word choices.
Thus, a useful metric for automatic evaluation in NLG applications holds the promise, such as machine translation, text summarization, image captioning, dialogue generation, poetry/story generation, etc.
Goals for evaluation metrics:
- Low cost: reduce time and money cost.
- Tunable: automatically optimize system performance towards metric.
- Meaningful: give the intuitive interpretation of quality.
- Consistent: repeated use of metric should provide the same results.
- Correct: The metric must rank better systems higher.
Evaluation task: for NLG tasks, given candidate hypothesis and human references, compute the similarity between them and provide the corresponding score.
BLEU (ACL 2002)
Designing for machine translation evaluation, BiLingual Evaluation Understudy (BLEU) [1] measures the $n$-gram overlap between translation output and reference, by computing the precision for n-grams of size 1 to N (N=4).
BLEU take the geometric mean of the test corpus’s modified $n$-gram precision scores , using $n$-grams up to length $N$ and positive weights summing to one. To compute the modified $n$-gram precision, all candidate $n$-gram counts and their corresponding maximum reference counts are collected. The candidate counts are clipped by their corresponding reference maximum value, summed and divided by the total number of candidate $n$-grams. In other words, truncating the $n$-gram counts in candidate with the corresponding maximum in the reference.
Then multiply by an exponential brevity penalty (BP) factor, given $c$ as the length of the candidate translation and $r$ as the effective reference corpus length (summing the best match lengths, i.e., the closest reference sentence length, forr each candidate sentence in the corpus).
Thus,
where $N=4$, and is usually uniform weights. That is,
- The BLEU score ranges from 0 to 1.
- 1-gram tends to satisfy adequacy, whereas large $n$-gram accounts for fluency.
- BLEU treats all systems similarly and uses multiple human translators with different styles to circumvent the variety differences such as “East Asian economy” with the reference “economy of East Asia”[1].
METEOR (WMT@ACL 2004)
Meteor[2] evaluates translation candidates in a more flexible way and calculates the sentence-level similarity scores. For a hypothesis-reference pair, the alignment is constructed by exhaustively identifying all possible matches between the sentences as follows:
- Exact: identical surface forms.
- Stem: same stem words (using Snoball Stemmer toolkit).
- Synonym: share membership in any synonym set in WordNet database.
- Paraphrase: match if they are paraphrases.
The final alignment solution using a beam search follows:
- Each word in each sentence is covered by zero or one match.
- Maximize the number of covered words across both sentences.
- Minimize the number of chunks, where a chunk is a series of contiguous and identically ordered words in both sentences.
- Minimize the sum of absolute distances between match start indices in the two sentences.
Content and function words are identical in the hypothesis and reference accoring to the function word list (any word whose relative frequency above 10^-3). For matches , count the number of content and function words in hypothesis and reference . Calculate weighted precision and recall using matcher weights and content-function word weight $\delta$:
To account for gaps and differences in word order, a fracmentation penalty uses the total number of match words $m$ and number of chunks ($ch$):
The Meteor score is calculated:
where parameters ${ \alpha, \beta, \gamma, \delta, (w_i, \cdots, w_n)}$ are tuned to maximize correlatin with human judgements.
ROUGE (ACL 2004)
Recall-Oriented Understudy for Gisting Evaluation (ROUGE)[3] is an automatic evaluation metric for text summarization, consisting of ROUGE-N, ROUGE-L, ROUGE-W, and ROUGE-S.
ROUGE-N: N-gram Co-Occurrence Statistics
ROUGE-N is an n-gram recall between a candidate summary and a set of reference summaries.
where represent the maximum number of n-grams co-occuring in candidate summry and a set of reference summaries. It is consistent with the intuition that a candidate summary that is more similar to many reference summaries is preferred.
vs. BLEU: BLEU is a precision-based measure whereas ROUGE-N is recall-based.
ROUGE-L: Longest Common Subsequence
Sentence-level LCS
Given a reference summary $X$ of length $m$, and a candidate summary sentence $Y$ of length $n$, the sentence level Longest Common Subsequence (LCS) is:
ROUGE-L
ROUGE-L takes the sentence-level normalized pairwise LCS.
ROUGE-W: Weighted LCS
It measures weighted LCS-based statistics that favor consecutive LCS.
ROUGE-S: Skip-bigram Co-Occurrence Statistics
ROUGE-S considers the skip-bigram-based F-measure:
where skip-bigram means any pair of words in the sentence regardless of the order and distance.
CIDEr (CVPR 2015)
Consensus-based Image Description Evaluation (CIDEr)[4] is proposed for evaluating the candidate sentence compared with reference for image image captioning. All words in both candidate and reference sentences are first mapped to their stem or root forms.
To penalize the commonly occurred words across all images, TF-IDF weighting for each $n$-gram is applied. Let the count that an $n$-gram occurs in a reference sentence be , and that of candidate sentence be . The TF-IDF weighting for each $n$-gram using:
where $\Omega$ is the vocabulary for all $n$-grams and $I$ is the image set. The second term (IDF) measures the word saliency by discounting popular words that are likely to be less visually informative.
The CIDErn score for $n$-grams uses the average cosine similarity between the candidate sentence and reference sentences:
where is a vector formed by corresponding to all $n$-grams of length $n$. So is . $w_n$ takes the uniform weights , $N=4$.
SPICE (ECCV 2016)
Previous evaluation methods are all $n$-gram based, sensitive to $n$-gram overlap. However, $n$-gram overlap is neither necessary nor sufficient for two sentences to convey the same meaning.
Semantic Propositional Image Caption Evaluation (SPICE)[5] measures the semantic meanings rather than $n$-gram based methods.
Given a candidate caption $c$ and a set of reference captions associated with an image $I$, the goal is to compute the score between $c$ and $S$. SPICE builds scene graph using Stanford Scene Graph Parser. A Probabilistic Context-Free Grammar (PCFG) dependency parser and additional linguistic rules are applied.
Given a set of object class $C$, a set of relation typles $R$, aset of attribute types $A$, a caption $c$, we parse $c$ to a scene graph:
where $O(c) \subseteq C $ is the set of object in $c$, $E(c) \subseteq O(c) \times R \times O(c)$ is the set of hyper-edges of relations, $K(c) \subseteq O(c) \times A$ ia the set of attributes of objects.
Define the function $T$ that returns logical tuples from a scene graph as:
The presicion $P$, recall $R$, SPICE are computed as:
where $\otimes$ denotes the binary matching that returns tha matching tuples in two scene graphs, using the WordNet synonym matching approach of Meteor.
SPICE is also bounded between 0 and 1.
BERTScore (ICLR 2020)
BERTScore[6]
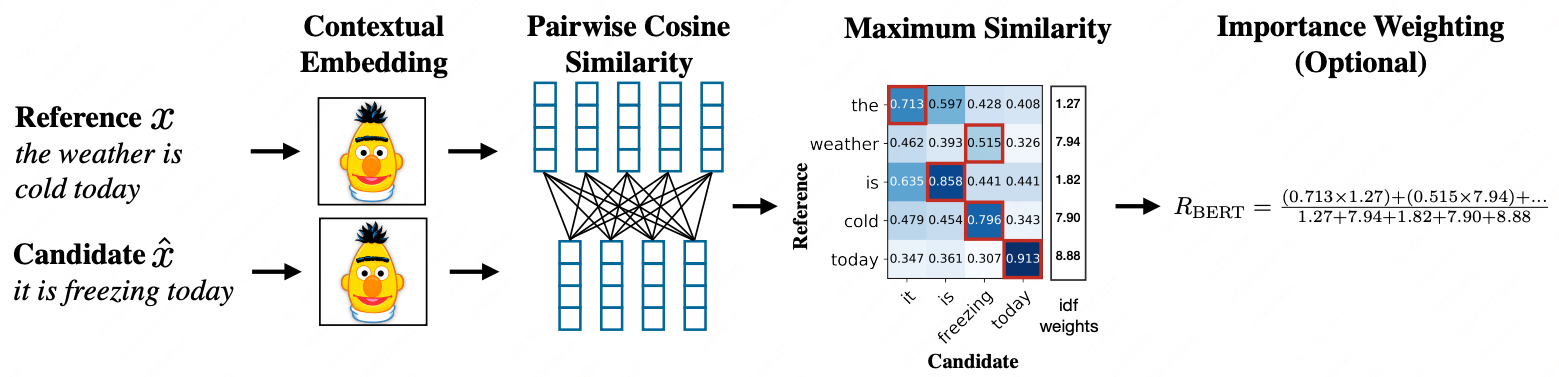
References
- 1.Papineni, K., Roukos, S., Ward, T., & Zhu, W. (2001). Bleu: a Method for Automatic Evaluation of Machine Translation. ACL. ↩
- 2.Denkowski, M.J., & Lavie, A. (2014). Meteor Universal: Language Specific Translation Evaluation for Any Target Language. WMT@ACL. ↩
- 3.Lin, C. (2004). ROUGE: A Package For Automatic Evaluation Of Summaries. ACL 2004. ↩
- 4.Vedantam, R., Zitnick, C.L., & Parikh, D. (2015). CIDEr: Consensus-based image description evaluation. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4566-4575. ↩
- 5.Anderson, P., Fernando, B., Johnson, M., & Gould, S. (2016). SPICE: Semantic Propositional Image Caption Evaluation. ECCV. ↩
- 6.Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q. and Artzi, Y., 2020. Bertscore: Evaluating text generation with bert. ICLR. ↩