
Summary of common decoding strategies in language generation.
Preliminaries
Language Modeling
Auto-regressive language modeling can be distangled as the accumulated product of conditional probabilites of the next word:
where is the initial contextual sequences, $T$ is the generated variable sequence length.
Maximization-based Decoding
Conventional decoding strategies aim to maximize the likelihood of generated sequences. In this way, generated texts with the highest score for long passages are often generic, repetitive, and awkward.
It assumes that models assign a higher probability to higher quality text.[5]
Greedy Search
Greedy search selects the token with the highest probability at each step:
So short-sighted is the greedy 1-best search not to guarantee the optimal sequences with the highest probabilities.
Beam Search
As a heuristic graph search algorithm, beam search explores the decoding search space with a beam-first search in a greedy left-to-right manner, retaining only the best $B$ partial hypotheses and pruning the hypothesizes with low probabilities at each time step, where $B$ is the beam width.
Length bias
It is noticeable that such a strategy prefers shorter sentences since the accumulated multiplication of probabilities reduces the overall probability of the whole sentence.
Beam search with a larger beam size posses the length bias towards outputs with the shorter length.
- A heuristic solution is to normalize the log probability by the length of the target sentence, i.e.,, searching for the sentence with the highest average log probability per word.[9]
- Dividing by $\textrm{length}^\alpha$ with $0 < \alpha < 1$ where $\alpha$ is optimized on a dev set.[10]
- Dividing by manually designed
Lack of diversity / degenerate repetition
The outputs of beam search on image captioning are near-duplicates with similar shared paths and minor variations[1]. Most completions tend to stem from a single, highly valued beam.
Near-identical beams
Generated sentences with top-$B$ beams are computationally wasteful due to the slight variation and near-identity with the same repeated computations.
Loss-evaluation mismatchLoss-evaluation mismatch is that improvements in posterior-probabilities not necessarily corresponding to task-specific metrics. Tuning the beam size as a hyperparameter leads to reduced beam widths, resulting in the side effect of decoding mostly bland, generic, and ‘safe’ outputs.[1]
As shown in the figure, it shows a discrepancy between human- and model- generated word probabilities: repetition of text decoded by beam search w.r.t the probability of tokens generation, while that of human generated text is with variance.[5]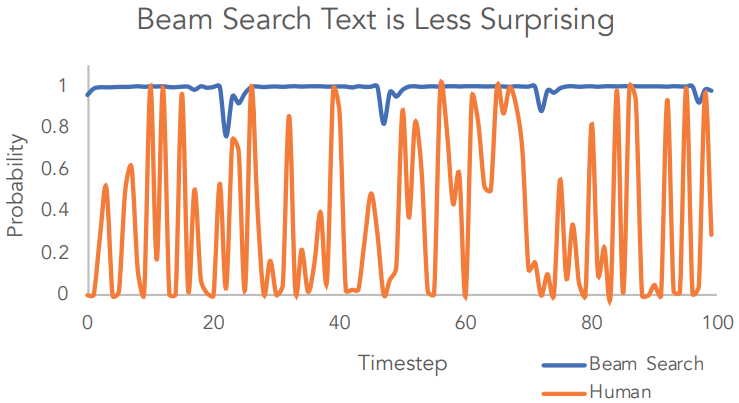
Q: Is the repetition truly due to the beam search?
Diverse Beam Search
Diverse Beam Search[1] divides the beam budget $B$ into $G$ groups and greedily optimize each group using beam search while holding previous groups fixed, with each group consisting of $B^{\prime} = B / G$ budgets.
An extra loss term is supplemented, where $\delta(\cdot, \cdot)$ is the measure of sequence dissimilarity, such as negative cost of co-occurring n-grams between two sentences. It is proved that Hamming distance achieves the best as the measurement.[1]
Noisy Parallel Approximate Decoding
Noisy Parallel Approximate Decoding (NPAD)[16] injects randomly sampled standard gaussian noise to the hidden state of the decoder at each step $t$. The Gaussian variance anneals from a starting $\sigma_0$ to $0$ as the decoding progresses. They applied linear annealing with .
Top-$g$ Capping
- At each step $t$, current hypotheses are grouped as $g$ groups according to the parental hypothesis they come from, keeping the top $g$ from each grouping.
- The resulting $B \times g$ candidates are ranked, and the top $B$ is selected as hypotheses for the next step.[15]
Clustered Beam Search
Clustered Beam Search[18] is applied for chatbots. It initially selects $B \times 2$ candidates according to the log probabilities. Afterward, K-means is used to cluster all candidates into $K$ clusters, keeping $B/K$ candidates in each cluster for the next step, wherein average word embeddings are adopted for clustering.
Clustering Post-Decoding
Clustering Post-Decoding(PDC)[15] leverages K-means clustering on sentence-level embeddings of BERT, chooses the highest-ranked candidate from each cluster after K-means clustering. Finally, remove groups with no greater than two hypotheses and sample a second candidate from each of the remaining clusters.
Contrastive Search
Sampling-based Decoding
Sampling strategies rely on the randomness of predicted word probabilities.
Multinomial Sampling
Simple sampling means directly sampling from probabilities predicted by the model, often leading to incoherent gibberish texts.
The unreliable tail that over-represented the relatively low-probability takes the blame for the degenerate sampling results.[5]
Temperature Sampling
Temperature Sampling[6] shapes the probability distribution via a temperature $T$ on logits $u$ to regulate the entropyu of the distribution:
Setting $t \in (0,1)$ warps the distribution towards high probability events, lowering the mass in the tail. Choosing a temperature higher than one leads to the output more random whilst making it less than one is similar to greedy sampling.[15]
Top-$k$ Sampling
Top-$k$ sampling method samples from a truncated fixed range of top-$k$ most probable choices.[6][13][14]
Top-$p$ (Nucleus) Sampling
Nucleus Sampling[5] leverages the shape of the probability distribution to scale the sampled probabilities. It selects from tokens whose cumulative probability mass exceeds the pre-chosen threshold $p$. Variable is its sampling size according to the shape of cumulative mass probabilities.
Given the top $p$ vocabulary as the subset:
Let . The original distribution is rescaled as:
- Top-$k$ sampling and Nucleus Sampling both sample from truncated regions of the original probability distribution, varying on different trustworthy prediction zone.
- Nucleus Sampling can be treated as a top-$k$ sampling with dynamically adjusted $k$.
1 | # https://github.com/facebookresearch/llama/blob/main/llama/generation.py |
Typical Sampling
$\eta$-Sampling
References
- 1.Vijayakumar, A. K., Cogswell, M., Selvaraju, R. R., Sun, Q., Lee, S., Crandall, D., & Batra, D. (2016). Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv preprint arXiv:1610.02424. ↩
- 2.Shao, L., Gouws, S., Britz, D., Goldie, A., Strope, B., & Kurzweil, R. (2017). Generating high-quality and informative conversation responses with sequence-to-sequence models. arXiv preprint arXiv:1701.03185. ↩
- 3.Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A. M. (2017). Opennmt: Open-source toolkit for neural machine translation. arXiv preprint arXiv:1701.02810. ↩
- 4.Paulus, R., Xiong, C., & Socher, R. (2017). A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304. ↩
- 5.Holtzman, A., Buys, J., Forbes, M., & Choi, Y. (2019). The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751. ↩
- 6.Fan, A., Lewis, M., & Dauphin, Y. (2018). Hierarchical neural story generation. arXiv preprint arXiv:1805.04833. ↩
- 7.Welleck, S., Kulikov, I., Roller, S., Dinan, E., Cho, K., & Weston, J. (2019). Neural text generation with unlikelihood training. arXiv preprint arXiv:1908.04319. ↩
- 8.Welleck, S., Kulikov, I., Kim, J., Pang, R. Y., & Cho, K. (2020). Consistency of a Recurrent Language Model With Respect to Incomplete Decoding. arXiv preprint arXiv:2002.02492. ↩
- 9.Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259. ↩
- 10.Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., ... & Klingner, J. (2016). Google's neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144. ↩
- 11.Li, J., Galley, M., Brockett, C., Gao, J., & Dolan, B. (2015). A diversity-promoting objective function for neural conversation models). arXiv preprint arXiv:1510.03055. ↩
- 12.Zhu, Y., Lu, S., Zheng, L., Guo, J., Zhang, W., Wang, J., & Yu, Y. (2018, June). Texygen: A benchmarking platform for text generation models. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval (pp. 1097-1100). ↩
- 13.Holtzman, A., Buys, J., Forbes, M., Bosselut, A., Golub, D., & Choi, Y. (2018). Learning to write with cooperative discriminators. arXiv preprint arXiv:1805.06087. ↩
- 14.Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9. ↩
- 15.Ippolito, D., Kriz, R., Kustikova, M., Sedoc, J., & Callison-Burch, C. (2019). Comparison of Diverse Decoding Methods from Conditional Language Models. arXiv preprint arXiv:1906.06362. ↩
- 16.Cho, K. (2016). Noisy parallel approximate decoding for conditional recurrent language model. arXiv preprint arXiv:1605.03835. ↩
- 17.Kulikov, I., Miller, A. H., Cho, K., & Weston, J. (2018). Importance of a search strategy in neural dialogue modelling. arXiv preprint arXiv:1811.00907. ↩
- 18.Tam, Y. C. (2020). Cluster-based beam search for pointer-generator chatbot grounded by knowledge. Computer Speech & Language, 101094. ↩