Given the fully observed variable of which $i$ indicates the $i$-th variable, be the hidden or missing variables. The objective is to maximize the log likelihood of observed data:
It is hard to direct optimize due to the $\log$ cannot be merged into the inner sum.
EM define the complete data log likelihood as:
This also cannot be computed since is unknown.
Then EM defines the expected complete data log likelihood as:
where $t$ is the current iteratio number, $Q$ is the auxiliary function. The expectation is take w.r.t the old parameters $\theta^{t-1}$ and the observed data $\mathcal{D}$.
In the E-step, compute the expected sufficient statistics (ESS)
In the M-step, the Q function is optimized w.r.t $\theta$:
To perform MAP estimation, the M step is modified as:
EM algorithm monotonically increase the log likelihood of the observed data (plus the log prior when doing MAP)
EM for GMMs
Let $K$ be the # of mixture components.
Auxiliary function
the expected complete data log likelihood is:
where is the responsibility that cluster $k$ takes for data point $i$, which is computed at E-step.
E step
M step
In the M step, EM optimizes $Q$ w.r.t $\pi$ and :
where is the weighted number of points assigned to cluster $k$.
The log likelihood:
Thus,
After computing such new estimates, set for $k=1:K$ and go to the next $E$ step.
The mean of cluster $k$ is just the weighted average of all poitns assigned to cluster $k$.
The covariance is proportional to the weighted empirical scatter matrix.
defupdate(self, points, n_iters=1000, TOLERANCE=1e-8): prev_ll = - np.inf with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) for i inrange(n_iters): cur_ll, _ = sess.run( [self.mean_ll, self.train_op], feed_dict={self.points: points} )
if i > 0: difference = np.abs(cur_ll - prev_ll) print(f'GMM step-{i}:\t mean likelihood {cur_ll} \t difference {difference}') if difference < TOLERANCE: break else: print(f'GMM step-{i}:\t mean likelihood {cur_ll}') prev_ll = cur_ll mu = self.mu.eval(sess) var = self.var.eval(sess) return mu, var
if __name__ == '__main__': import numpy as np n_points = 200 n_clusters = 3 D = 100 points = np.random.uniform(0, 10, (n_points, D)) # random cluster = GMM(D, n_clusters, init_centroids=None) mu, var = cluster.update(points)
Multiplying multiple small probabilities can cause the arithmetic underflow, i.e.
To circumvent this, a common trick called log sum exponential trick:
K-means
K-means algorithm is a variant of EM algorithm for GMM, which can be seen as a GMM with such assumptions: and are fixed, only the cluster centers will be estimated.
In the E step,
where , which is also called hard EM since K-means makes the hard assignment of the points to clusters.
E step
Since the equal spherical convariance matrix is assumed, the most probable cluster for can be computed using the Euclidian distance between $N$ data points and $K$ cluster centroids:
This is equivalence to minimizing the pairwise squared deviations of points in the same cluster.
M step
Given the hard cluster assignments, the M step update the cluster centroid by computing the mean of all points assigned to it:
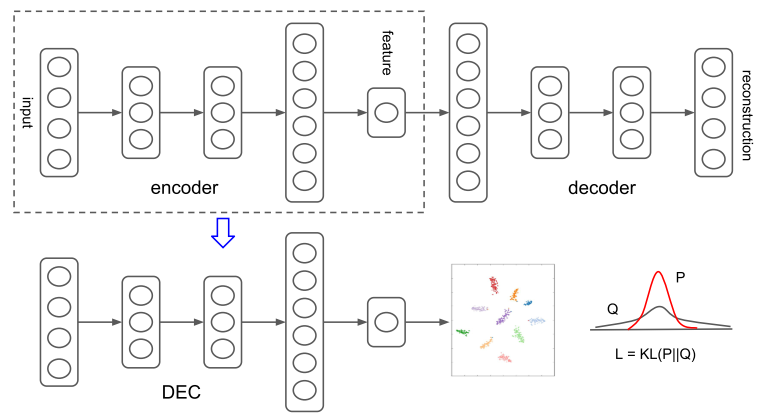
parametrize initialization with a deep autoencoder
clustering, by computing an auxiliary target distribution and minimize KL divergence.
DEC Clustering
Given initial cluster centroids , DEC firstly computes the soft assignment between the embedded points and the cluster centroids; afterwards, update the deep mapping with Stochastic Gradient Descent and refine the cluster centroids using an auxiliary target distribution. This process is repeated until convergence.
Soft Assignment
DEC applies Student’s $t$-distribution as a kernel to measure the similarity between embedded point and centroid :
where corresponds to after embedding, $\alpha$ (set to 1) are the degrees of freedom of the Student’s $t$-distribution and can be interpreted as the probability of assigning sample $i$ to cluster $j$ (i.e., soft assignment).
KL Divergence
DEC iteratively refines the clusters by learning from their high confidence assignments with the auxiliary target distribution. KL divergence is computed beween the soft assignments and the auxiliary distribution :
The choice of target distribution $P$ is critical.