
This is a concise introduction of Variational Autoencoder (VAE).
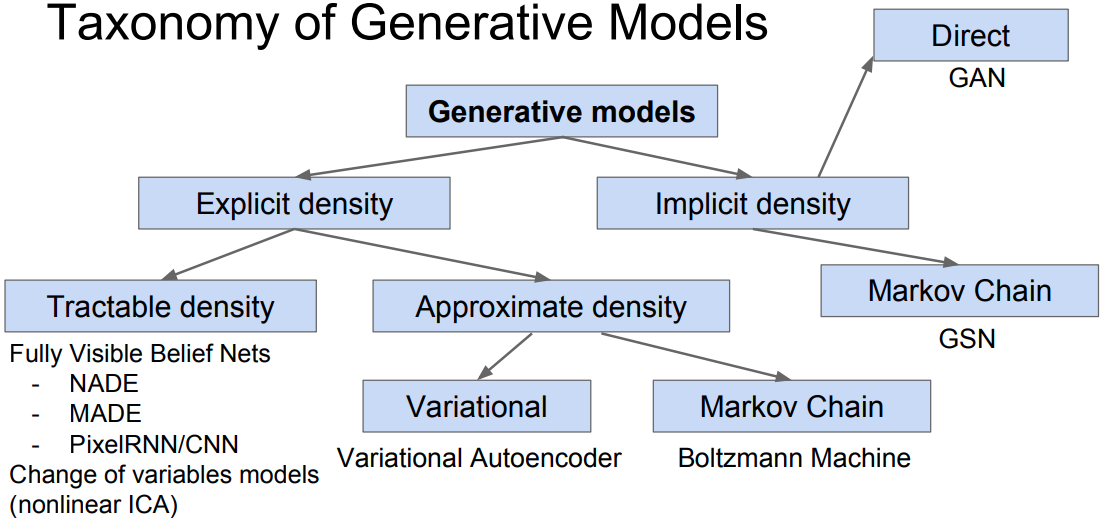
Background
PixelCNN define tractable density function with MLE:
VAE define the intractable density function with latent $\mathbf{z}$:
This cannot directly optimize, VAEs derive and optimize the lower bound on likelihood instead.
Autoencoder
Autoencoder (AE) encodes the inputs into latent representations $\mathbf{z}$ with dimension reduction to capture meaningful factors of variation in data. Then employ $\mathbf{z}$ to reconstruct original data by autoencoding itself.
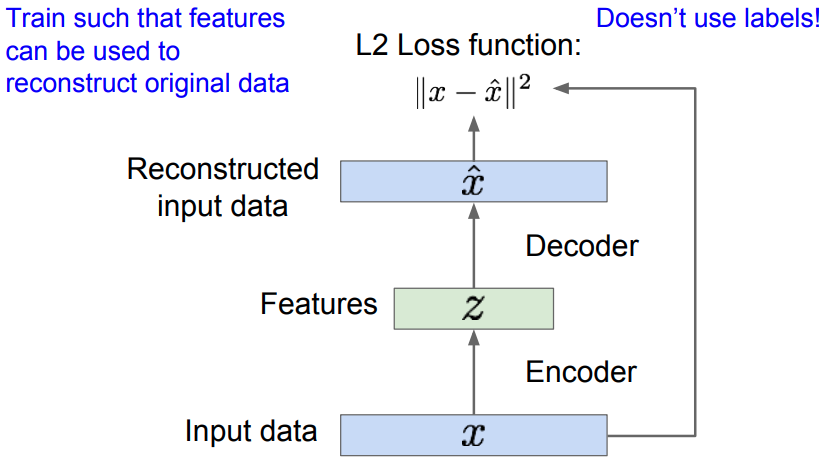
- After training, throw away the decoder and only retain the encoder.
- Encoder can be used to initialize the supervised model on downstream tasks.
Variational Autoencoder
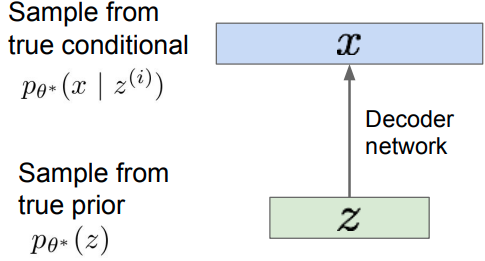
Assume training data is generated from underlying unobserved (latent) representation $\mathbf{z}$.
Intuition:
- $\mathbf{x}$ -> image
- $\mathbf{z}$ -> latent factors used to generate $\mathbf{x}$: attributes, orientation, pose, how much smile, etc. Choose prior $p(z)$ to be simple, e.g. Gaussian.
Training
Problem
Intractable integral to MLE of training data:
where it is intractable to compute $p(x \vert z)$ for every $z$, i.e. integral. The intractability is marked in red.
Thus, the posterior density is also intractable due to the intractable data likelihood:
Solution
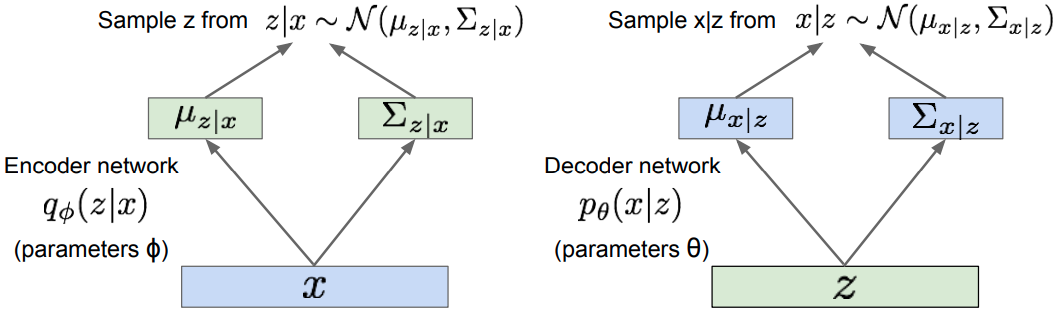
Encoder -> “recognition / inference” networks.
- Define encoder network that approximates the intractable true posterior . VAE makes the variational approximate posterior be a multivariate Gaussian with diagonal covariance for data point $\mathbf{x}^{(i)}$:
where
- For Gaussian MLP encoder or decoder[4],
Use NN to model $\log \sigma^2$ instead of $\sigma^2$ is because that $\log \sigma^2 \in (-\infty, \infty)$ whereas $\sigma^2 \geq 0$
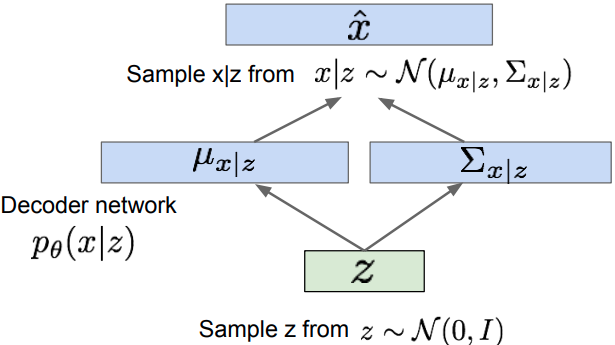
Decoder -> “generation” networks
- The first RHS term represents tractable lower bound , wherein and $\mathbb{KL}$ terms are differentiable.
- Thus, the variational lower bound (ELBO) is derived:
- Training: maximize lower bound
where
- the fist term : reconstruct the input data. It is a negative reconstruction error.
- the second term make approximate posterior distribution close to the prior. It acts as a regularizer.
The derived estimator when using isotropic multivariate Gaussian :
where and , and denote the $j$-th element of mean and variance vectors.
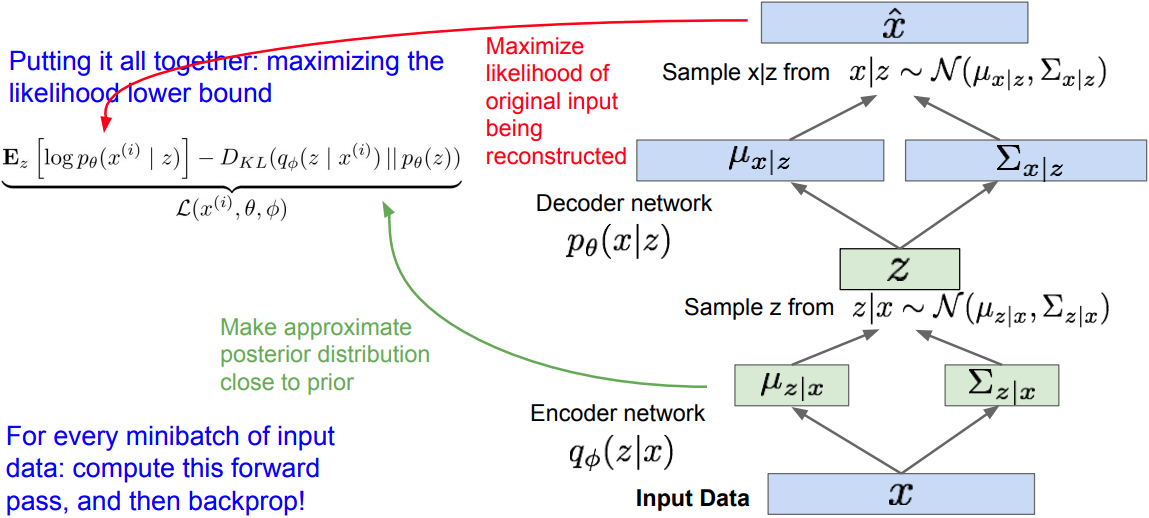
Reparameterization trick
Given the deterministic mapping , we know that
Thus,
Take the univariate Gaussian case for example: $z \sim p(z \vert x) = \mathcal{N}(\mu, \sigma^2)$, the valid reparameterization is: $z = \mu + \sigma \epsilon$, where the auxiliary noise variable $\epsilon \sim \mathcal{N}(0,1)$.
Thus,
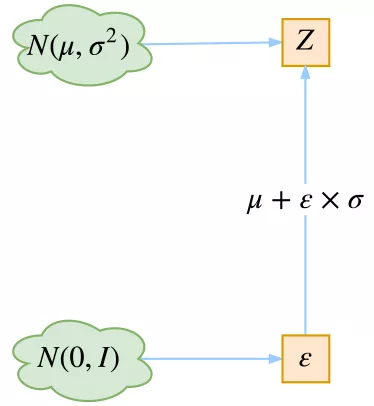
Generation
- After training, remove the encoder network, and use decoder network to generate.
- Sample $z$ from prior as the input!
- Diagonal prior on $z$ -> independent latent variables!
- Different dimensions of $z$ encode interpretable factors of variation.
- Good feature representation that can be computed using
![]()

Pros & cons
- Probabilistic spin to traditional autoencoders => allows generating data
- Defines an intractable density => derive and optimize a (variational) lower bound
Pros:
- Principles approach to generative models
- Allows inference of $q(z \vert x)$, can be useful feature representation for downstream tasks
Cons:
- Maximizes lower bound of likelihood: okay, but not as good evalution as PixelRNN / PixelCNN!
- loert quality compared to the sota (GANs)
Variational Graph Auto-Encoder (VGAE)
Definition
Given an undirected, unweighted graph $\mathcal{G}=(\mathcal{V}, \mathcal{E})$ with $N=|V|$ nodes, the ajacency matrix $\mathbf{A}$ with self-connection (i.e., the diagonal is set to 1), degree matrix $\mathbf{D}$, stochastic latent variable in matrix $\mathbf{Z} \in \mathbb{R}^{N \times F}$, node features $\mathbf{X} \in \mathbb{R}^{N \times D}$. [7]
Inference model
Apply a 2-layer Graph Convolutional Networks (GCN) to for parameterization:
where
- Mean:
- Variance:
The two-layer GCN is defined as
where is the semmetrically normalized adjacency matrix.
Generative model
The generative model applies an inner product between latent variables:
where are elements of ajacency matrix $\mathbf{A}$ and $\sigma(\cdot)$ represents the sigmoid function.
Learning
Optimize the variational lower bound (ELBO) w.r.t the variational parameters :
where the Gaussian prior
References
- 1.Stanford cs231n: Generative models ↩
- 2.I. Goodfellow et. al, Deep Learning ↩
- 3.Goodfellow, I. (2016). Tutorial: Generative adversarial networks. In NIPS. ↩
- 4.Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114. ↩
- 5.Doersch, C. (2016). Tutorial on Variational Autoencoders. ArXiv, abs/1606.05908. ↩
- 6.cs236 VAE notes ↩
- 7.Kipf, T., & Welling, M. (2016). Variational Graph Auto-Encoders. ArXiv, abs/1611.07308. ↩