
Flow models are used to learn continuous data.
Discrete autoregressive models tractably learn the joint distribution by decomposing it into a product of conditionals using the probability chain rule according to a fixed ordering over dimensions.
The sequential nature limits its computational efficiency:
- its sampling procedure is sequential and non-parallelizable;
- there is no natural latent representation associated with autoregressive models.
To sum up:
- Pros:
- fast evaluation of p(x)
- great compression performance
- good samples with carefully designed dependency structure
- Cons:
- slow sampling (without significant engineering)
- discrete data only
Flows explanation
Ideas: instead of using a pdf over $\mathbf{x}$, work with a flow from $\mathbf{x}$ to $\mathbf{z}$
Flows in 1D
Flow from $\mathbf{x}$ to $\mathbf{z}$ : an invertible differentiable mapping $f$ from $\mathbf{x}$ (data) to $\mathbf{z}$ (noise):
Training
- $\mathbf{x}$ to $\mathbf{z}$: transform the data distribution into a base distribution p(z)
- common choices: uniform, std Gaussian
- Training the CDF is equivalent to the PDF:
Ancestral sampling (a.k.a forward sampling):
- $\mathbf{z}$ to $\mathbf{x}$: mapping $\mathbf{z} \sim p(\mathbf{z})$ through the flow’s inverse will yield the data distribution $\mathbf{x}=f_\theta^{-1}(\mathbf{z})$

Change of variables:
Fitting flows:
- fit with MLE:
- is the density of $x$ under the sampling process and is calculated using Change of variables.
CDF flows:
- Recover the original objective with CDF flows:
- Flows can be more general than CDFs.
Flows in high dimensions
For high-dimensional data, $x$ and $z$ have the same dimension.

Change of variables: For $z \sim p(z)$, ancestral sampling process f-1 linearly transforms a small cube $dz$ to a small parallelepiped $dx$.
Intuition: $x$ is likely if it maps to a “large” region in $z$ space.
Training
Train with MLE:
where the Jacobian determinant must be easy to calculate and differentiate!
Constructing flows: composition
- Fows[5] can be composed:
Affine flows (multivariate Gaussian)
Affine flows (multivariate Gaussian)
- Parameters: an invertible matrix $A$ and a vector $b$
- $f(x) = A^{-1} (x-b)$
Sampling: $x= Az + b$, where $z \sim \mathcal{N}(0,1)$
Log likelihood is expensive when dimension is large:
- the Jacobian of $f$ is $A^{-1}$
- Log likelihood involves calculating $\text{det}(A)$
Elementwise flows
- flexible: it can use elementwise affine functions or CDF flows
The Jacobian is diaganal, so the determinant is easy to evaluate:
More flow types
Coupling layers (NICE[1]/RealNVP[2]), directed graphical models, invertible 1x1 convs[9], FFJORD
NICE
A good representation is one in which the distribution of the data is easy to model.
Consider the problem of learning a pdf from a parametric family of densities over finite dataset $\mathcal{D}$ of $N$ samples, of each in a space $\chi$, typically $\chi=\mathbb{R}^D$
Non-linear Independent Component Estimation (NICE)[1] learns a non-linear deterministic transformation $h=f(\mathbf{x})$ to map the input $\mathbf{x}$ into the latent space with a factorized distribution, i.e. independent latent variables :
Apply the change of variables $h=f(x)$, assuming that $f$ is invertible and differentiable, the dimension of $h$ and $x$ are the same in order to fit the distribution :
where is the Jocobian matrix of function $f$ at $x$.
where , the prior distribution, is a predefined PDF, e.g. isotropic Gaussian. If the prior distribution is factorial (i.e. with independent dimensions), then we have the deterministic transform of a factorial distribution:
where
NICE can be viewed as an invertible preprocessing transform of the dataset.
- Invertible preprocessings can increase likelihood arbitrarily simply by contracting the data. The factorized prior encourages to discover meaningful structures in the dataset.
Coupling layer
Given $x \in \chi$, , are partitions of $[1,D]$ such that $d=|I_1|$ and $m$ is a function. Define where:
where g: is the coupling law. If and , the Jacobian is:
where is the identity matrix of size $d$, thus
The inverted mapping is:
Additive coupling layer
NICE applies so that taking and :
RealNVP
Real-valued non-volume preserving (real NVP)
Affine coupling layer
- Given a $D$ dimensional input $x$ and $d<D$, the output $y$ of an affine coupling layer follows:where $s$ and $t$ represent scale and translation functions from $\mathbb{R}^{d} \rightarrow \mathbb{R}^{D-d}$.
The Jocobian is:
The determinant can be computed as:
Masked convolution
Partitioning adopts the binary mask $b$:
where $s(\cdot)$ and $t(\cdot)$ are rectified CNNs.
Two partitioning are applied:
- spatial checkerboard patterns
- channel-wise masking
![upload successful]()

Autoregressive flows
Construct flows from directed acyclic graphs.
Autoregressive flows:
- The sampling process of a Bayes net is a flow:
- if autoregressive, called autoregressive flow:
- Sampling is an invertible mapping from $z$ to $x$
- The DAG structure causes the Jacobian to be triangular, when variables are ordered by topological sort.
*How to fit autoregressive flow?
- map $\mathbf{x}$ to $\mathbf{z}$
- fully parallelizable
Variational lossy autoencoder (VLAE)
Variational Lossy Autoencoder (VLAE)[6] force the global latent code to discard irrelevant information and thus encode the data in a lossy fassion.
For an autoregressive flow $f$, some continuous noise source $\epsilon$ is transformed into latent code $\mathbf{z}$: $\mathbf{z} = f(\epsilon)$. Assuming the density function for noise source is $u(\epsilon)$, then $\log p(\mathbf{z}) = \log u(\epsilon) + \log \text{det}\frac{d \epsilon}{d \mathbf{z}}$
Masked autoregressive flow (MAF)
Considering an AR model whose conditionals are parameterized as single Gaussians, i.e., the $i$-th conditional is given by:
where and are unconstrained scalar functions that compute the mean and log standard deviation of the $i$-th conditional given all previous variables
Thus the data can be generated by:
- The vector of random numbers (with
randn()) is used to generate data.
Given data point $\mathbf{x}$, the random number vector $\mathbf{u}$ is:
- where and .
Due to the AR structure, the Jacobian of $f^{-1}$ is triangular by design, hence:
- where .
- This can be equivalently interpreted as a normalizing flow.
Masking
- The functions are with masking, like MADE.
It is derived that MAF and IAF has the theoretical equivalence (See [7]).
Inverse autoregressive flow (IAF)
Inverse autoregressive flow (IAF)[8] is the inverse of an AR flow:
- $\mathbf{x} \rightarrow \mathbf{z}$ has the same structure as the sampling in an AR model
- has the same structure as loglikelihood computation of an AR model. Thus, IAF sampling is fast

IAF approximates the posterior $q(\mathbf{z} \vert \mathbf{x})$ with the chain. At $t$-th step of the flow, IAFapply the AR NN with inputs $\mathbf{z}_{t-1}$ and $\mathbf{h}$, and outputs and . (See the figure)
The density at $T$-th step:
The output of autogressive NN:
- where
Pseudocode
Given:
- $\mathbf{x}$: a datapoint
- $\mathbf{\theta}$: NN parameters
- $\textrm{EncoderNN}(\mathbf{x}; \mathbf{\theta})$: encoder network, with output $\mathbf{h}$
- $\text{AutoregressiveNN}[*](\mathbf{z,h;\theta})$: autoregressive networks, with input $\mathbf{h}$
- let $l$ denote the scalar value of $\log q(\mathbf{z} \vert \mathbf{x})$, evaluated at sample $\mathbf{z}$
IAF algorithm:
- $[\mathbf{\mu},\sigma, \mathbf{h}] \leftarrow$ EncoderNN$(\mathbf{x; \theta})$
- $\mathbf{\epsilon} \sim \mathcal{N}(0, I)$
- $\mathbf{z} \leftarrow \sigma \odot \epsilon + \mu$
- $l \leftarrow -\text{ sum}(\log \sigma + \frac{1}{2}\epsilon^2) + \frac{1}{2}\log(2\pi)$
- for $t = {1,\cdots, T}$:
- $[\mathbf{m}, \mathbf{s}] \rightarrow \text{AutoregressiveNN}[t](\mathbf{z,h;\theta})$
- $\sigma \leftarrow \text{sigmoid}(\mathbf{s})$
- $\mathbf{z} \leftarrow \sigma \odot \mathbf{z} + (1-\sigma) \odot \mathbf{m}$
- $l \leftarrow -\text{sum}(\log \sigma) + l$
AF vs IAF
AF:
- Fast evaluation of $p(x)$ for arbitrary $x$
- Slow sampling
IAF:
- Slow evaluation of $p(x)$ for arbitrary $x$, so training directly by MLE is slow
- Fast sampling
- Fast evaluation of $p(x)$ if $x$ is a sample
Parallel WaveNet, IAF-VAE exploit IAF’s fast sampling.
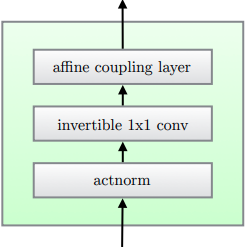
Glow
Glow[9]
- Activation norm
- Invertible 1x1 convolution
- Affine coupling layers
Flow++
Flow++[10]
- Dequantization via VI
- Improved coupling layers
- Apply CDF for a mixture of $K$ logistics
- stacking conv and multi-head self-attention
References
- 1.Dinh, L., Krueger, D., & Bengio, Y. (2014). NICE: Non-linear Independent Components Estimation. CoRR, abs/1410.8516. ↩
- 2.Dinh, L., Sohl-Dickstein, J., & Bengio, S. (2016). Density estimation using Real NVP. ArXiv, abs/1605.08803. ↩
- 3.CS294-158 Lecture 2c+3a slides ↩
- 4.CS228 notes: sampling methods ↩
- 5.Rezende, D.J., & Mohamed, S. (2015). Variational Inference with Normalizing Flows. ArXiv, abs/1505.05770. ↩
- 6.Chen, X., Kingma, D.P., Salimans, T., Duan, Y., Dhariwal, P., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Variational Lossy Autoencoder. ArXiv, abs/1611.02731. ↩
- 7.Papamakarios, G., Murray, I., & Pavlakou, T. (2017). Masked Autoregressive Flow for Density Estimation. NIPS. ↩
- 8.Kingma, D.P., Salimans, T., & Welling, M. (2017). Improved Variational Inference with Inverse Autoregressive Flow. ArXiv, abs/1606.04934. ↩
- 9.Kingma, D.P., & Dhariwal, P. (2018). Glow: Generative Flow with Invertible 1x1 Convolutions. NeurIPS. ↩
- 10.Ho, J., Chen, X., Srinivas, A., Duan, Y., & Abbeel, P. (2019). Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design. ICML. ↩
- 11.Müller, T., McWilliams, B., Rousselle, F., Gross, M., & Novák, J. (2018). Neural Importance Sampling. ACM Trans. Graph., 38, 145:1-145:19. ↩
- 12.Grathwohl, W., Chen, R.T., Bettencourt, J., Sutskever, I., & Duvenaud, D. (2018). FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models. ArXiv, abs/1810.01367. ↩
- 13.Huang, C., Krueger, D., Lacoste, A., & Courville, A.C. (2018). Neural Autoregressive Flows. ArXiv, abs/1804.00779. ↩
- 14.Oord, A.V., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K., Driessche, G.V., Lockhart, E., Cobo, L.C., Stimberg, F., Casagrande, N., Grewe, D., Noury, S., Dieleman, S., Elsen, E., Kalchbrenner, N., Zen, H., Graves, A., King, H., Walters, T., Belov, D., & Hassabis, D. (2017). Parallel WaveNet: Fast High-Fidelity Speech Synthesis. ArXiv, abs/1711.10433. ↩