
The brain has about 1014 synapses and we only live for about 109 seconds. So we have a lot more parameters than data. This motivates the idea that we must do a lot of unsupervised learning since the perceptual input (including proprioception) is the only place we can get 105 dimensions of constraint per second.
(Geoffrey Hinton)
Unsupervised learning can be used to capture rich patterns in raw data with deep networks in a label-free way.
- Generative models: recreate raw data distribution
- Goal: learn some underlying hidden structure of the data
- Self-supervised learning: “puzzle” tasks that require semantic understanding to improve downstream tasks.
- Examples: clustering , dimensionality reduction, compression, feature learning, density estimation
Main generative models:
- Autoregressive
- Normalizing flow
- Variational Autoencoder
- Generative Adversarial Networks
Real applications:
- generating data: synthesizing images, videos, speech, texts
- compressing data: constructing efficient codes
- anomaly detection
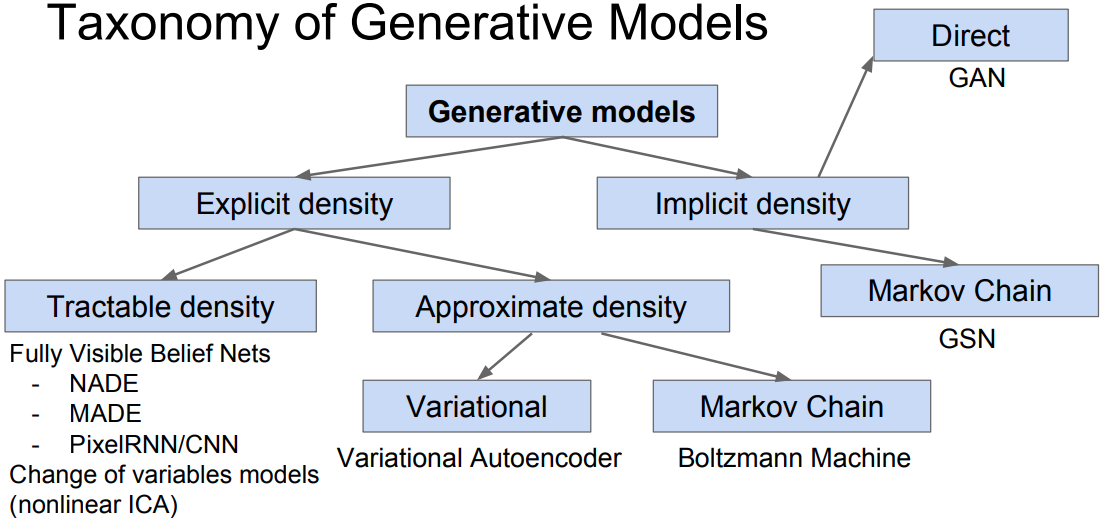
Likelihood-based models:
- estimate from samples
Given a dataset , find $\theta$ by solving the optimization problem:
which is equivalent to minimizing KL divergence between the empirical data distribution and the model:
- MLE + SGD
- p$\theta$ $\rightarrow$ NN
Autoregressive models
Autoregressive (AR) models share parameters among conditional distributions:
- RNNs
- Masking convolutions & attentions
The AR property is that each output only dependes on the previous input units , but not on the future:
AR models can only model discrete data.
RNN AR models
RNNs privode a compact, shared parameterization of a sequence of conditional distributions, shown to excel in handwriting generation, character prediction, machine translation, etc.
RNN LM
Given sequence of characters $\mathbf{x}$, $i$ indicates the position of characters:
Raw LSTM layers:
PixelRNN
Like in LM, AR models cast the joint distribution of pixels in the images to a product of conditional distributions, turning the joint modeling problem into a sequential problem with factorization, where one learns to predict the next pixel given all preivous generated pixels.
PixelRNN leverages two-dimensional RNNs and residual connections[1] in generative image modeling.
Pixel-by-pixel generation
The probability $p(\mathbf{x})$ to each image $\mathbf{x}$ of $n \times n$ pixels. The image $\mathbf{x}$ is tiled as 1-D sequence where pixels are taken from the image row by row. The joint distribution $p(\mathbf{x})$ is the product of the conditional probability over pixels:
where each pixel is conditioned on all the previous generated pixels, whose generation is in the raster scan order: row by row and pixel by pixel within each row.
Taking into account RGB color channels of each pixel, the distribution of pixel $x_i$ is:
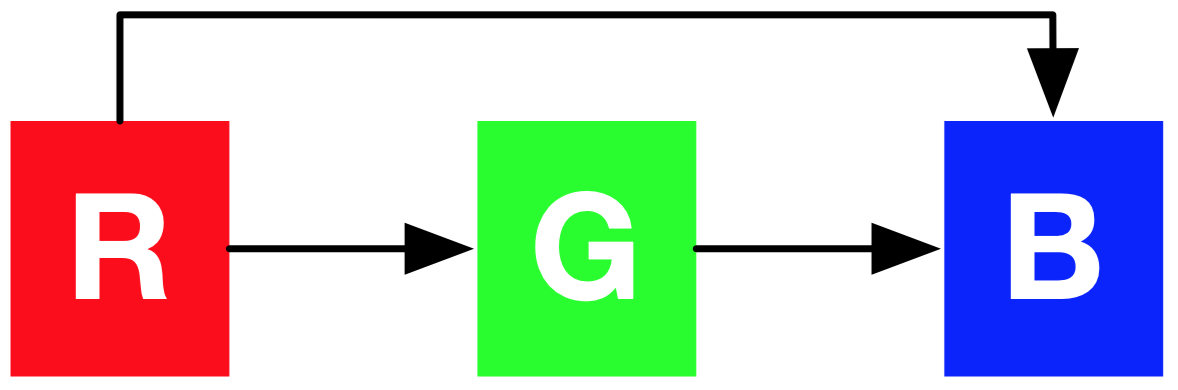
PixelRNN employs the discrete distribution with a 256-way softmax. Each channel variable takes the scalar values from 0 to 255. The advantages:
- to be arbitrarily multimodal without prior on the shape;
- achieve better results than continuous distribution and easy to learn.
- Training & evaluation -> the pixel distribution is parallel distribution (teacher forcing)
- Generation -> sequential, row by row and pixel by pixel.
![]()
Row LSTM
Row LSTM is a unidirectional LSTM layer that takes the image row by row from top down to bottom computing features with 1-D convolution for a whole row at once.
It captures a roughly “triangular context” above the pixel with kernel size of $k \times 1$ in temporal convolutions where $k \leq 3$, of which the larger kernel size captures the broader contexts and weight sharing guarantees the translation invariance.
- Row LSTMs have the triangular receptive field, unable capturing the entire available context.
The computation proceeds as follows.
- LSTM layers have an input-to-state (is) and recurrent state-to-state (ss) component that together determine the four gates inside the LSTM core.
- The input-to-state component is precomputed using 1-D masked convolution with kernel size $k \times 1$ horizontally, where , $h$ denotes the # of output feature maps.
- The row-wise state-to-state component of the LSTM layer takes the previous hidden and cell state and , where , the weights $\mathbf{K}^{ss}$ and $\mathbf{K}^{is}$ represent the kernel weights of state-to-state and input-to-state components, $\circledast$ denotes the convolution operation.
Diagonal BiLSTM
Diagonal BiLSTM is designed to impede the drawbacks of limited triangular receptive fields of Row LSTM and could capture the entire available context.
Diagonal BiLSTM skews the input $\mathbf{x} \in \mathbb{R}^{n \times n}$ into $\mathbb{R}^{n \times (2n-1)}$ by shifting the $i$-th row with $(i-1)$ position offsets, i.e. each row is one position right shift compared with the previous row (see below figure).
- The input-to-state components of each direction adopt a $1 \times 1$ convolution $K^\text{is}$, and the output of $(\mathbf{K}^\text{is} \circledast \mathbf{x}) \in \mathbb{R}^{4h \times n \times n}$
- The state-to-state recurrent component uses a column-wise 1D convolution $K^\text{ss}$ with kernel size $2 \times 1$.
Why 2x1? Larger sizes do not broaden the already global receptive fields. - For bi-LSTMs, the right-to-left directional LSTM is shifted down by one row and added to the left-to-right LSTM outputs.
![]()
- Train the pixelRNN of up to 12 layers of depth with residual connections and layer-to-output skip connections.
![]()
Masking-based AR models
Key property: parallelized computation of all conditions
- Masked MLP (MADE)
- Masked convolutions & self-attention (PixelCNN families and PixelSNAIL)
- also share parameters across time
![]()
MADE
Masked Autoencoder Distribution Estimator (MADE) (Deepmind & Iain Murray)[3] masks the autoencoder’s parameters to respect autoregressive properties that each input only reconstructed from previous input in a given ordering.
MADE zeros out the connections of layer connections by elementwise-multiplying a binary mask matrix on the weight matrices, setting the weight connectivities as 0s for removing.
For masked autoencoder with $L>1$ hidden layers, let
- $D$ denote the dimension of input $\mathbf{x}$, $\mathbf{M}$ denote the connection mask;
- in $l$-th layer, $K^l$ be the # of hidden states, $m^l(k)$ represent the maximum number of connected input of the $k$-th unit.
For $l$-th layer in masked autoencoders, the mask of weight matrices $\mathbf{W}$:
For the output mask of weight matrices $\mathbf{V}$:
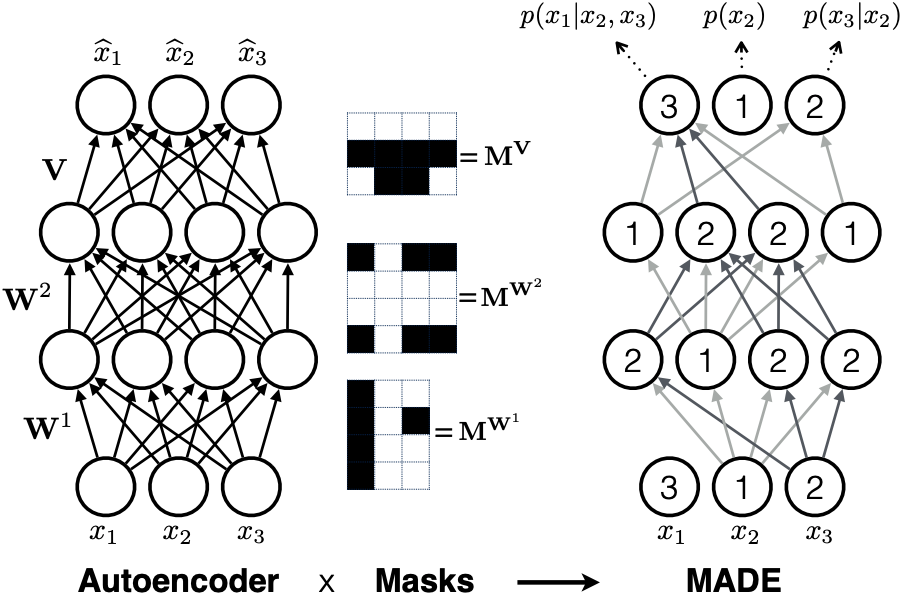
PixelCNN families
PixelCNN
PixelCNN[1] adopts multiple conv layers without pooling to preserve the spatial resolution and masks the future context.
- Drawbacks: PixelRNNs cannot consider the pixels on the right side of the current position (as Fig. below).
![]()
Gated PixelCNN
Gated PixelCNN takes into account both the vertical stack and the horizontal stack by combing both the pixels of region above and those on the left of the current row, wherein the convolutions of vertical stack are not masked. (See [5] for the tutorial.)
- advantages: deal with “blind spot” of the receptive field in PixelCNNs.
![]()
Gated PixelCNNs replace the ReLU between masked convolutions in the original pixelCNN with the gated activation function:
where $p$ represents the # of feature maps, $\circledast$ denotes convolution operations, where it is masked in horizontal stack but unmasked in the vertical stack.
![]()
Conditional PixelCNN
Given high-level latent representation $\mathbf{h}$, we model the conditional PixelCNN models:
Add terms pf $\mathbf{h}$ before the non-linearities:
where $k$ is the layer number.
Condition on what:
- class-dependent: $\mathbf{h} \rightarrow \text{1-hot}$, is equivalent to adding a class-dependent bias at each layer.
Condition on where:
- location-dependent: use Transposed convolution to map $\mathbf{h}$ to a spatial representation $\color{red}{\mathbf{s} = \text{deconv}(\mathbf{h})}$ to produce the output $\mathbf{s}$ of the same shape as the image. It can be seen as adding a location dependent bias:
PixelCNN++
Background:
- previous 256-way softmax is very costly and slow to compute, and makes the gradient w.r.t parameters very sparse.
- the model does not know that the value 128 is close to that of 127 and 129. Especially unobserved sub-pixels will be assigned with 0 probability.
PixelCNN++[6] assumes the latent color intensity $\nu$ with continuous distribution and takes the continuous univariate distribution to be a mixture of logistic distributions.
- $\sigma(x) = -1 / (1+ \exp(- x))$.
- For all sub-pixels except the edges 0 and 255:
- For edge cases,
- when $x=0$, set $x-0.5 \rightarrow -\infty$
- when $x=255$, set $x+0.5 \rightarrow +\infty$
Logistic distribution:
where the mean $ \mu \in (-\infty, +\infty)$, std deviation $s >0$
- PixelCNN++ does not use deep networks to model the relationship between color channels. For the pixel at the location $(i,j)$ in the image, with the contexts :
where $\alpha$, $\gamma$, $\beta$ are scalar coefficents depdenting on the mixture component and previous pixels.
- As shown in the figure, it applies convolutions of stride 2 for downsampling and transposed strided convolution for upsampling. It also uses shor-cut connections recover the information loss from convolutions in the lower layers, similar to VAE[8] and U-Net[7].
![]()
WaveNet
- Masked convolutions: masked convolution has limited receptive field and thus requires deep stacked layers of a linearly increased number. It requires expand the kernel size or incease the layer depth to enlarge the effective receptive fields. (see below figure)
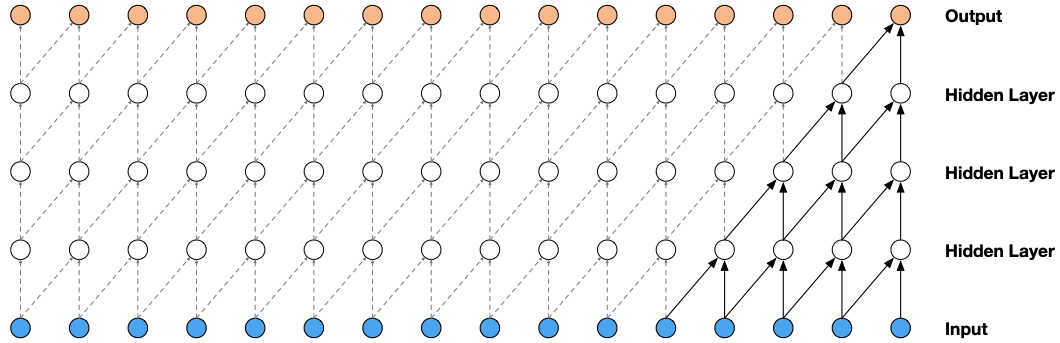
WaveNet[11][12] (van den Ood et al., DeepMind 2016) leverages dilated masked casual convolution to exponentially increase the receptive field. It is applied in TTS, ASR, music generation, audio modeling, etc.
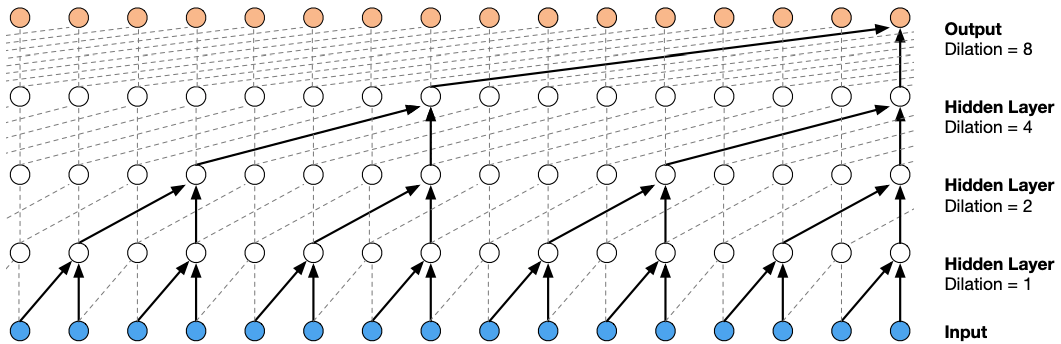
Model architecture
It uses the same gated activation unit in PixelCNN, outperforming ReLU:
The overall model structure is: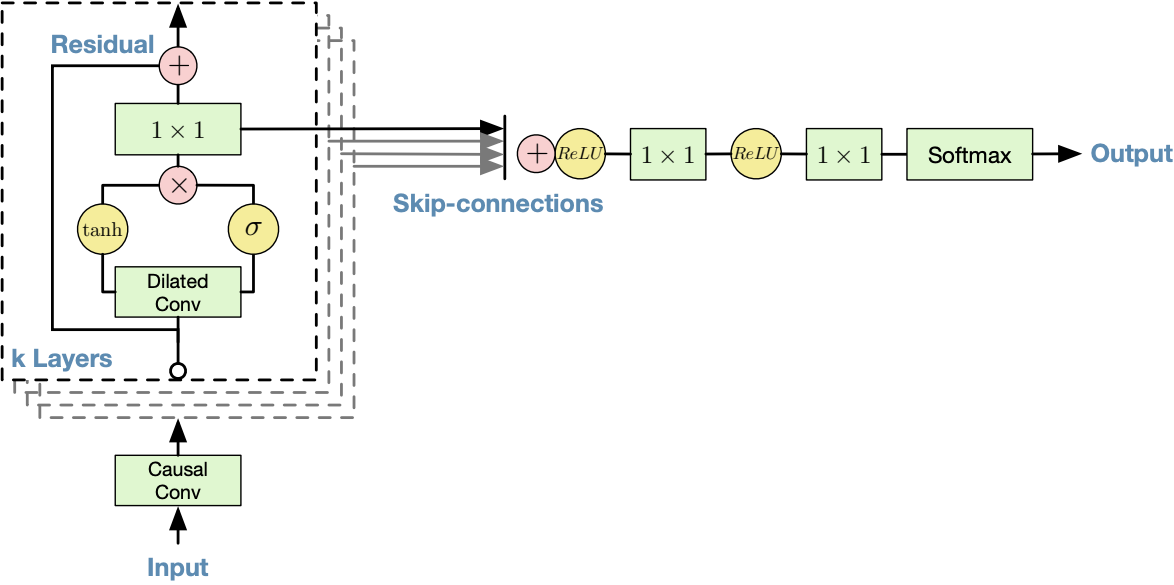
Conditional WaveNet
Like the conditional Gated PixelCNN, WaveNet can be also conditional on a hidden representation $\mathbf{h}$.
- Global conditioning on a single representation vector $\mathbf{h}$ that influences the output distribution of all timesteps, e.g. a speaker embedding in a TTS model:
- Local conditioning on a second timeseries , possibly with a lower sampling frequency than the audio, e.g. linguistic features in a TTS model. WaveNet learns the upsampling on this time series using a transposed convolution:
Softmax distribution
The raw audio output is stored as a sequence of 16-bit scalar values (one per time step), thus the softmax output is 216=65,536 probabilities per timestep. WaveNet applies a $\mu$-law companding transformation to the data and thenquantize it to 256 possible values:
where , $u=255$. The reconstruction signal after quantization sounded similar to the original.
Fast generation via caching
Problems: During generation, convolutional AR models redundantly compute states, impeding the speed of generation process. Such states can be cached and reused to expedite the generation.[14]
The convolutional autoregressive generative model could cache and reuse the previously computed hidden states to accelerate the generation.
The below figure shows the model with 2 convolutional and 2 transposed convolutional layers with strid of 2, wherein blue dots indicate the cached states and orange bots are computed in the current step. The computation process can be seen as:
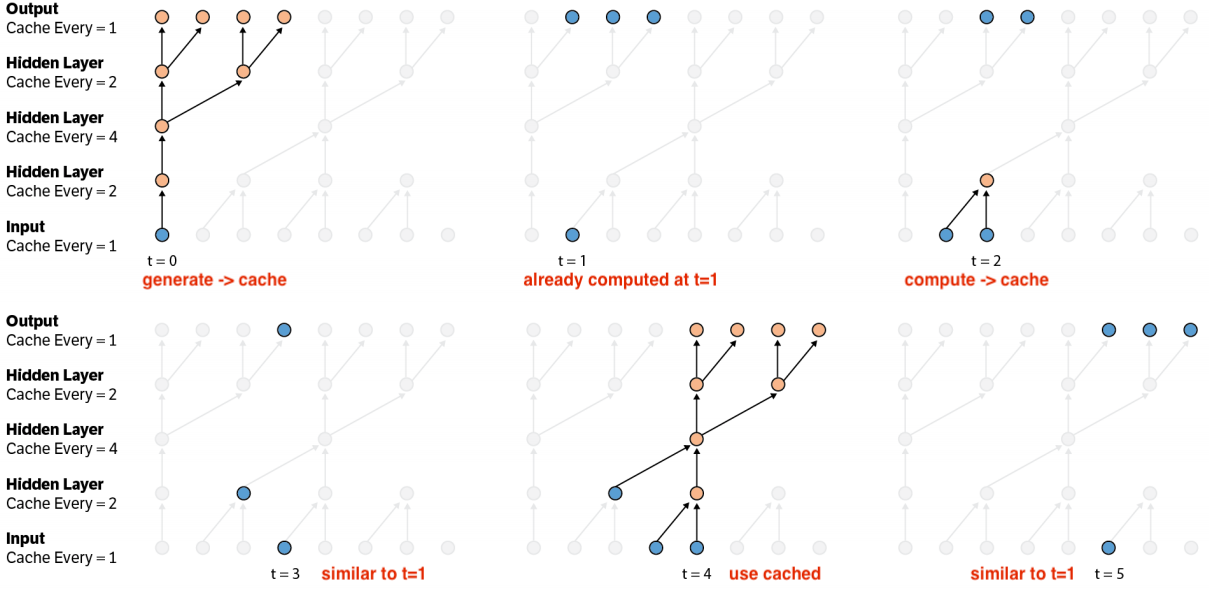
- This can also scale to 2D to apply on PixelCNN families[14].
PixelSNAIL
PixelSNAIL[10] adopt masked self-attention approaches inspired by SNAIL[9].
Model architecture
The overall model structure:
![]()
It uses the self-attention block with shape (see below figure):
- Key fk:
- Query fq:
Value fv(x):
Given 2D feature map $\mathbf{y}= {y_1, y_2, \cdots, y_N }$, the attention mapping is:
where the summation over all previous history, i.e. $j<i$.
![]()
- It applies 2D convolutions with gated activation functions as gated &PixelCNN* and residual connections as the figure.
![]()
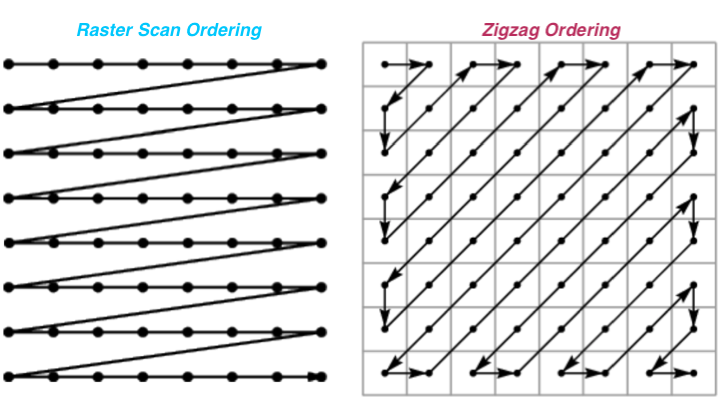
- It adopts the zigzag ordering rather than PixelCNN-like raster scan ordering.
- It employs the discretized mixture of logistics of PixelCNN++ as the output distribution.
In comparison,
- Gated PixelCNN and PixelCNN++ apply causal convolutions (dilated and strided conv, respectively) over the sequence, allowing the high-brandwidth access to the previous pixels. However, caual convolutions are limited to the receptive field due to their finite sizes.
- PixelSNAIL achieves a much larger receptive field size (see below figure).
![]()
Analysis
“The basic difference between AR models with Generative Adversarial Networks (GANs) is that GANs implicitly learn data distribution whereas AR models learn the explicit distribution governed by a prior. “[15]
Pros:
- expressivity (explicit learn): AR factorization is general; can explicitly compute likelihood $p(x)$
- explicit likelihood of training data gives good evaluation metric
- good samples
- generalization: meaningful parameter sharing has good inductive bias
- the training is more stable than GANs
- it works for both discrete and continuous data (It is hard to learn discrete data like text for GANs)
Cons:
- Sequential generation => slow!
- Low sampling efficency: sampling each pixel = 1 forward pass!
Reference
- 1.Oord, A. V. D., Kalchbrenner, N., & Kavukcuoglu, K. (2016). Pixel recurrent neural networks. (Google DeepMind). ICML 2016. ↩
- 2.The Unreasonable Effectiveness of Recurrent Neural Networks. Andrej Karpathy blog ↩
- 3.Germain, M., Gregor, K., Murray, I., & Larochelle, H. (2015, June). Made: Masked autoencoder for distribution estimation. In International Conference on Machine Learning (pp. 881-889). ↩
- 4.Van den Oord, A., Kalchbrenner, N., Espeholt, L., Vinyals, O., & Graves, A. (2016). Conditional image generation with pixelcnn decoders. In Advances in neural information processing systems (pp. 4790-4798). ↩
- 5.Tutorial: Gated PixelCNN ↩
- 6.Salimans, T., Karpathy, A., Chen, X., & Kingma, D. P. (2017). Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517. ↩
- 7.Ronneberger, O., Fischer, P., & Brox, T. (2015, October). U-net: Convolutional networks for biomedical image segmentation%E5%92%8CTiramisu. In International Conference on Medical image computing and computer-assisted intervention (pp. 234-241). Springer, Cham. ↩
- 8.Kingma, D. P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., & Welling, M. (2016). Improved variational inference with inverse autoregressive flow. In Advances in neural information processing systems (pp. 4743-4751). ↩
- 9.Mishra, N., Rohaninejad, M., Chen, X., & Abbeel, P. (2017). A simple neural attentive meta-learner. arXiv preprint arXiv:1707.03141. ↩
- 10.Chen, X., Mishra, N., Rohaninejad, M., & Abbeel, P. (2017). Pixelsnail: An improved autoregressive generative model. ICML 2018. ↩
- 11.Oord, A. V. D., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499. ↩
- 12.(DeepMind blog) WaveNet: A generative model for raw audio ↩
- 14.Ramachandran, P., Paine, T. L., Khorrami, P., Babaeizadeh, M., Chang, S., Zhang, Y., ... & Huang, T. S. (2017). Fast generation for convolutional autoregressive models. arXiv preprint arXiv:1704.06001. ↩
- 15.(TowardsDataScience blog) Auto-Regressive Generative Models (PixelRNN, PixelCNN++) [^16:] CS294-158 Lecture 2 slides ↩
- 17.Parallel Multiscale Autoregressive Density Estimation ↩
- 18.PixelCNN Models with Auxiliary Variables for Natural Image Modeling ↩
- 19.GENERATING HIGH FIDELITY IMAGES WITH SUBSCALE PIXEL NETWORKS AND MULTIDIMENSIONAL UPSCALING ↩
- 20.Stanford cs231n: Generative models ↩