
Techniques of NN training. Keep updating.
NLP
Weight tying
Weight tying[1] is tying the input word embedding matrix $U$ (called input embedding) with topmost weight matrix $V$ (called output embedding) of neural network language models (NNLM), i.e., setting $U=V$. This technique can reduce the parameter size and therefore lead to less overfitting.
Press et. al (2016) showed that the weight typing
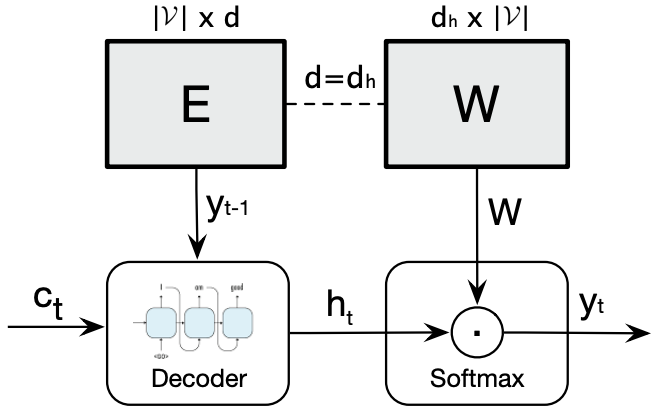
Untied NNLM
Give the word sequence at timestep t, and current output target word , the NLL loss is:
where , is the $k$-th row of $\mathbf{U}/\mathbf{V}$, $k$ is the corresponding word index, is the vector of activations of the topmost LSTM layers’ output at time t.
The update for row $k$ of input embedding $\mathbf{U}$ is:
For the output embedding $\mathbf{V}$, the $k$-th row update is:
Therefore, in the untied NNLM,
- the input embedding $\mathbf{U}$ only updates the current input word at $k$-th row, which denotes that the update times is correlated with its occurrence and thus rare words would be updated few times;
- the output embedding $\mathbf{V}$ updates every row at each timestep.
Tied NNLM
With weight tying, we set $\color{red}{\mathbf{U}=\mathbf{V}=S}$. Thus $S$ serves as the role of both the input and output embeddings, whose update of each row in $S$ would conducted through both of them.
- It can be seen that the update is mostly affected by the output embeddings and the tied weights perform similarly to output embedding $\mathbf{V}$ rather than input embedding $\mathbf{U}$ in the untied model.
- Projection regularization is used at large models, by inserting the projection matrix $\color{red}{P}$ before the output embedding $\mathbf{V}$: Then add the regularization term to the loss. $\lambda=0.15$ in our experiments.
References
- 1.Press, O., & Wolf, L. (2016). Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859. ↩