
This is an introduction of recent BERT families.
Relevant notes:
LM pretraining background
Autoregressive Language Modeling
Given a text sequence , autoregressive (AR) language modeling factorizes the likelihood along a uni direction according to the product rule, either forward:
or backward:
The AR pretraining maximizes the likehood under the forward AR factorization:
where denotes the context representation by NNs, such as RNNs/Transformers; denotes the embedding of $x$.
It is not effective to model the deep bidirectional contexts.
Autoencoding based pretraining
Autoencoding (AE) based pretraining does not perform density estimation, but recover the original data from corrupted (masked) input.
Denosing autoencoding based pretraining, such as BERT can model the bidirectional contexts. Given a text sequence , it randomly masks a portion (15%) of tokens $\bar{\pmb{x}}$ in $\pmb{x}$. The training objective is to reconstruct randomly masked token $\bar{\pmb{x}}$ from corrupted sequence $\hat{\pmb{x}}$:
where
- means is masked;
- the Transformer encodes $\pmb{x}$ into hidden vectors
However, it relies on corrupting the input with masks. The drawbacks:
- Independent assumption: cannot model joint probability and assume the predicted tokens are independent of each other. It neglects the dependency between the masked positions
- pretrain-finetune discrepancy (input noise): the artificial symbols like [MASK] used by BERT does not exist during the training of downstream tasks.
XLNet
XLNet[1] (CMU & Google brain 2019) leverages both the advatage of AR and AE LM objectives and hinder their drawbacks.
- The permutation of the factorization order impedes the dependency between masked positions in BERT and still remains the AR-like objectives so as to prevent the pretrain-finetuning discrepancy.
- On the other hand, with permutation, it attends to the bi-contextual information as in BERT.
Permutation Language Model
XLNet[13] applies permutation language model by autoregressively pretraining bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization order.
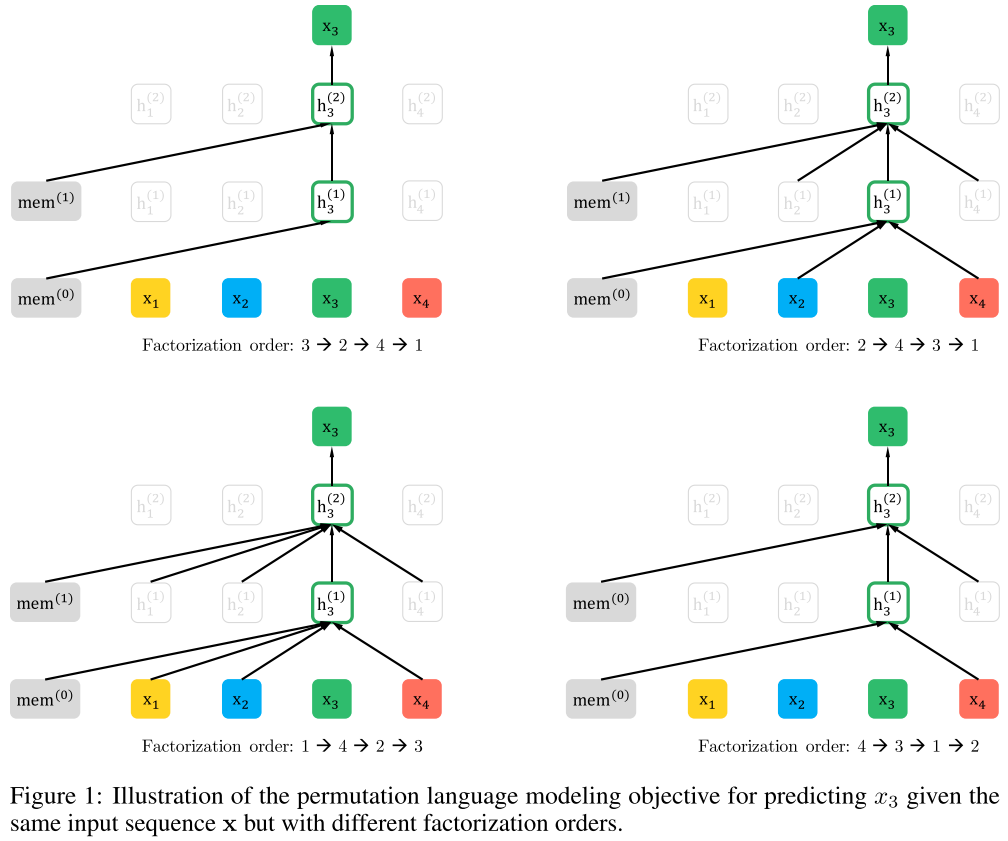
For a sequence $\pmb{x}$ of length $T$, there are $T!$ different orders to perform a valid AR factorization.
Permutation language modeling not only retains the benefits of AR models but also capture the bidirectional contexts as BERT. It only permutes the factorization order, rather than the sequence order.
Implementation
XLNet Implementation
1 | # XLNet implementation (tf) |
Huggingface Implementation
1 |
|
Two-stream self-attention
The next-token distribution with the standard softmax formulation:
where , abbr. , denotes content representation, which encodes both context and itself, as hidden states in Transformer, i.e. standard self-attention, see below figure(a).
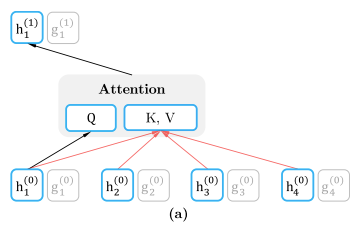
However, the previous $t-1$ sequence cannot implies the unique predicted target since different target words might have the same previous sequence in the permutated AR factorization. Hence, XLNet also consider the target position information:
where , abbr. denotes a query representation, only using the position and not the context , as below figure(b).
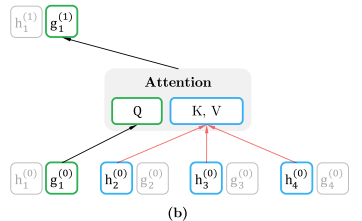
- query stream uses but cannot see :
- content stream uses both and :
Here $\pmb{Q}$,$\pmb{K}$,$\pmb{V}$ denot the query, key, value in an attention op.
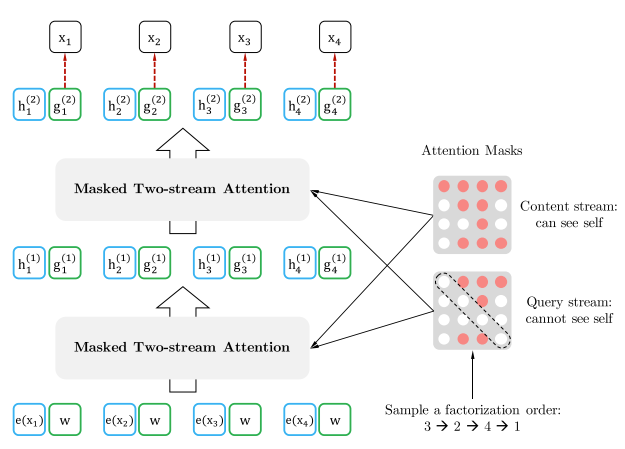
- During finetuning, we can simply drop the query stream and use the content stream as a normal Transformer(-XL).
- The permutation implementation is relying on the attention mask, as shown in the figure, which does not affect the original sequecen orders.
Transformer-XL
Borrow relative positional encoding and segment recurrence mechanism from Transformer-XL[2].
The next segment with memory is:
Relative segment encoding
XLnet only considers ‘’whether the two positions in segments are within the same segment as opposed to considering which specific segments they are from‘’.
The idea of relative encodings is only modeling the relationships between positions , denoting the segment encoding beween position i to j.
The attention weight , where is the query vector in std attention and $\mathbf{b}$ is a learnable head-specific bias vector. Finally add to the normal attention weight.
The advantage of relative segment encodings:
- to introduce inductive biases to improve generalization;
- to allow for the multiple input segments in finetuning on tasks.
RoBERTa: “BERT is undertrained”!
RoBERTa[5] (Fair & UW 2019) (Robustly optimized BERT approach) redesigned the BERT experiments[6], illustrating BERT is underfitted. It showed that BERT pretraining with a larger batch size over more data for more training steps could lead to a better pretraining results.
Recent works[1][5] questioned the effectiveness of Next Sentence Prediction (NSP) pretraining task proposed by BERT[6].
SpanBERT
SpanBERT[7] (UW & Fair) proposed a span-level pretraining approach by masking contiguous random spans rather than individual tokens as in BERT. It consistently surpass BERT and substantially outweights on span selection tasks involving question answering and coreference resolution. The NSP auxiliary objective is removed.
In comparison,
- The concurrent work ERNIE[8] (Baidu 2019) that masked linguistically-informed spans in Chinese, i.e. masking phrase and named entity, achieve improvements on Chinese NLP tasks.
Span masking
At each iteration, the span’s length is samplled from a geometric distribution $\mathscr{l} \sim Geo(p) = (1-p)^{(k-1)} p$; the starting point of spans are uniformly random selected from the sequence. (In SpanBERT, p=0.2, and clip .)
15% of tokens in span-level are masked: of which masking 80%, replacing 10% with noise, keeping the rest 10%.
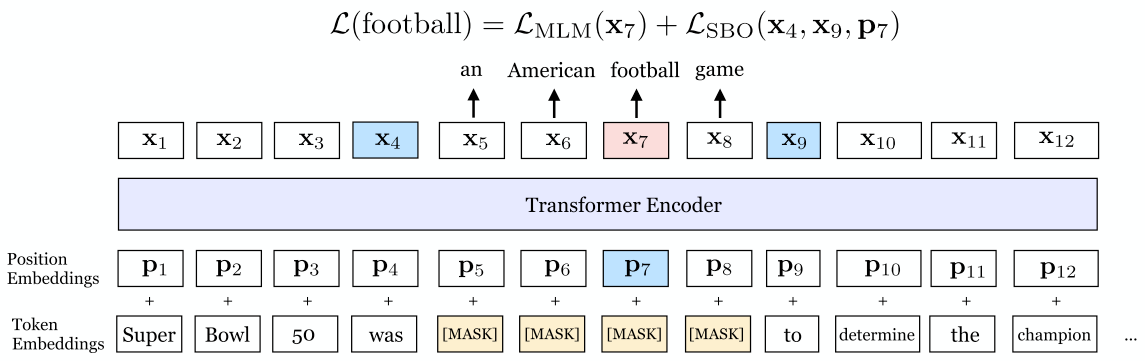
Span boundary objective (SBO)
Given a masked span , where (s,e) denotes the start and ending positions. Each token in the span are represented using the encodings of the outside boundary tokens and (i.e., and in the figure) and the target positional embedding of target token , that is:
where $f(\cdot)$ indicates the 2-layer FFNN with layer normalizations and Gelu activations.
The representions of span tokens is used to predict and compute the corss entropy loss like MLM objective in BERT.
ALBERT
ALBERT[9] (A Lite BERT) (Google 2019) adopted factorized embedding parameterization and cross-layer parameter sharing techiniques to reuduce the memory cost of BERT architecture.
Factorized embedding parameterization
ALBERT decomposed the embedding parameters with higher dimension to smaller matrices, by firstly projecting the inputs into a lower dimensional embedding of size E, followed by the second projection to the hidden space. The embedding paprameters are reduced from $O(V \times H)$ to $O(V \times E + E \times H)$, which is obvious when $H \gg E$
Cross-layer parameter sharing
All parameters across layers on both self-attentions and FFNs are shared. It is empirically showed that the L2 distance and cosine similarity between the input and output are oscillating rather than converging, which is different than that in Deep Equilibrium Model (DEQ)[10].
Sentence-order prediction (SOP)
ALBERT use two consecutive setences as positive samples as in NSP, and swap the order of the same ajacent segments directly as the negative samples, consistently showing a better results for multi-sentence encoding tasks.
ELECTRA
ELECTRA[11] (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) (Standford NLP) proposed a more sample-efficient pre-training approach, replaced token detection to efficiently boost the pretraining efficiency, which solves the pretraining-finetuning discrepancy led by [MASK] symbols.
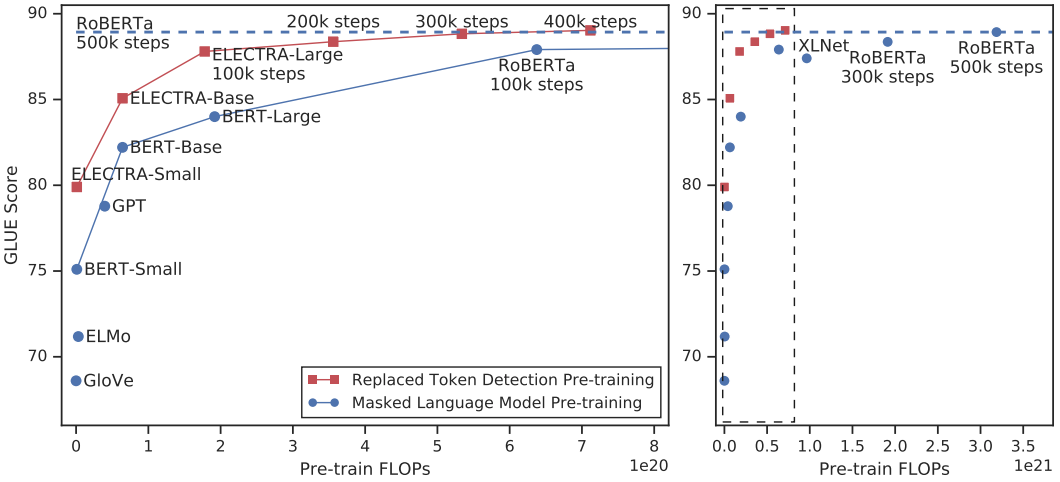
Replaced token detection
- Rather than randomly masked tokens with the probability 15% as in BERT, replaced token detection replaces tokens with plausible alternatives that sampled from the output of a small generator network.
- Then adopt a discriminator to predict whether each token was corrupted with a sampled replacement.
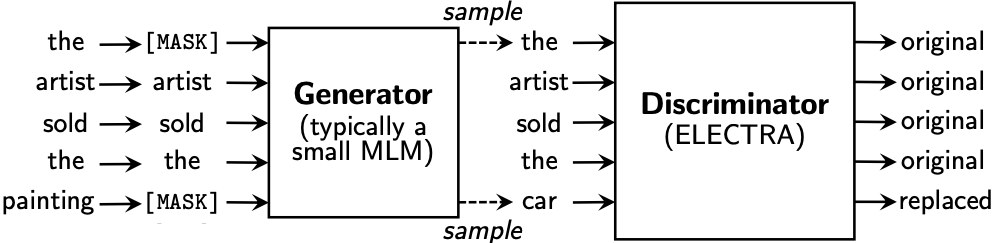
ELECTRA trains two NNs, a generator $G$ and a discriminator $D$. Each one primarily consists of an encoder that maps a sequence on input tokens into the contextual representation .
The generator is used to to do Masked Language Model (MLM) as in BERT[6]. For the position $t$, the generator outputs the distribution of via a softmax layer:
where $e$ is the word embeddings.
For the discriminator $\mathscr{D}$, it discriminates whether the token at position $t$ is replaced.
- MLM of BERT first randomly selects the positions to mask , wherein tokens at masked positions are replaced with a [MASK] token:
- In contrast, the replaced token detection uses the generator G to learn the MLE of masked tokens whilst the discriminator D is applied to detect the fakeness.
Loss function
The loss functions are:
The combined loss is minimized:
where $\chi$ denotes the corpus.
Training
Weight sharing
- Share the embeddings (both token embeddings and position embeddings) of the generator and discriminator.
- Weight tying strategy[12] -> only tied embeddings.
Two-stage training
- Train only the geenrator with for $n$ steps
- Initialize the weights of the $D$ with $G$ and train $D$ with for $n$ steps, keeping the generator’s weight frozen.
After pretraining, throw away the generator and fine-tune the discriminator on downstream tasks.
References
- 1.Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237. ↩
- 2.Dai, Z., Yang, Z., Yang, Y., Cohen, W. W., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860. ↩
- 3.Shaw, P., Uszkoreit, J., & Vaswani, A. (2018). Self-attention with relative position representations. arXiv preprint arXiv:1803.02155. ↩
- 4.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). ↩
- 5.Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692. ↩
- 6.Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. ↩
- 7.Joshi, M., Chen, D., Liu, Y., Weld, D. S., Zettlemoyer, L., & Levy, O. (2019). Spanbert: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529. ↩
- 8.Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., ... & Wu, H. (2019). ERNIE: Enhanced Representation through Knowledge Integration. arXiv preprint arXiv:1904.09223. ↩
- 9.Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942. ↩
- 10.Deep Equilibrium Models. arXiv 2019 ↩
- 11.ELECTRA: Pre-training Text Encoders as Discriminators rather than Generators ↩
- 12.Press, O., & Wolf, L. (2016). Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859. ↩
- 13.GitHub: XLNet ↩