
A guide to calculate the number of trainable parameters by hand.
Feed-forward NN
FFNN
Given
- $\pmb{i}$ input size
- $\pmb{o}$ output size
For each FFNN layer
RNN
Given
- $\pmb{n}$ # of FFNN in each unit
- RNN: 1
- GRU: 3
- LSTM: 4
- $\pmb{i}$ input size
- $\pmb{h}$ hidden size
For each FFNN, the input state and previous hidden state are concatenated, thus each FFFN has $\pmb{(h+i) \times h} + \pmb{h}$ parameters.
The total # of params is
- LSTM:
- GRU:
- RNN:
LSTMs

">[2]</span></a></sup>](/notes/images/lstms.png)
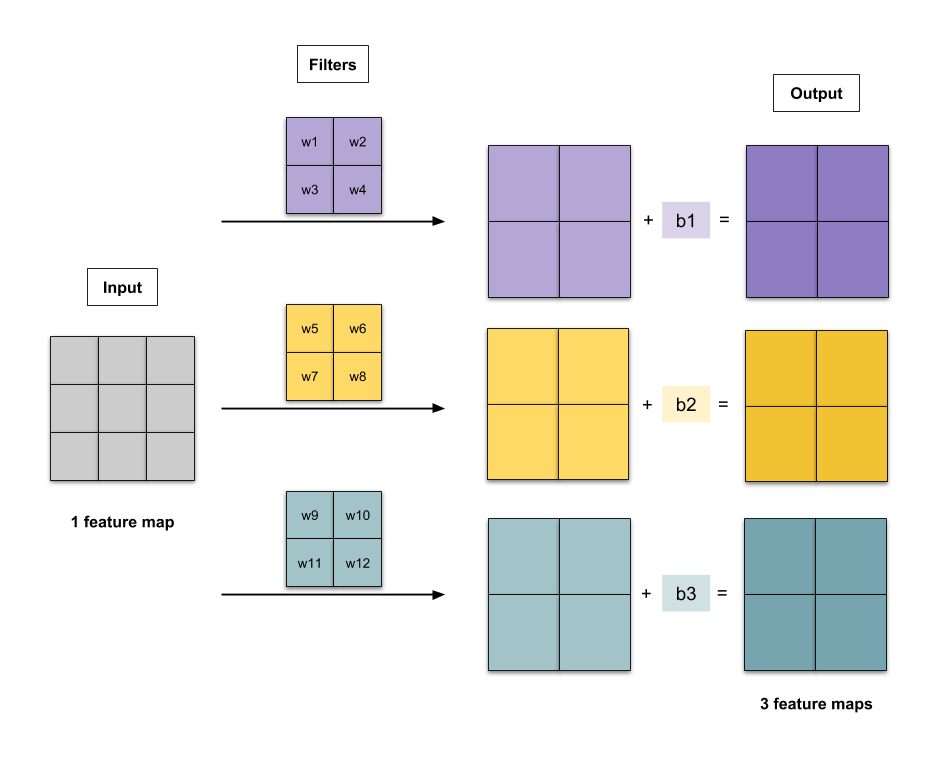
CNN
Given
- $\pmb{i}$ input channel
- $\pmb{f}$ filter size
- $\pmb{o}$ output channel (i.e. # of filters)
Transformers
Given
- $\pmb{x}$ denotes the embedding dim == model dimension == output dimension
MHDPA
. In Advances in neural information processing systems (pp. 5998-6008).">[3]</span></a></sup>](/notes/images/multi-head.png)
- Scaled dot product
Multi-head dot product attention (MHDPA)
Overall, MHDPA has 4 linear connections (i.e., K, V, Q, output after concat). There are $4 \times \left[ (\pmb{x} \times \pmb{x}) + \pmb{x} \right]$ trainable parameters.
Transformer Encoder
. In Advances in neural information processing systems (pp. 5998-6008).">[3]</span></a></sup>](/notes/images/transformer-encoder.png)
Given
$\pmb{m}$ is # of encoder stacks
Layer normalization
the param number of single layer norm is sum the count of weights $\gamma$ and biases $\beta$: $\pmb{x}+\pmb{x}$
FFNN: param number of two linear layers = $(\pmb{x} \times \pmb{4x} + \pmb{4x}) + (\pmb{4x} \times \pmb{x} + \pmb{x})$
Thus the total number of transformer encoder is: sum the number of 1 MHDPA, 2 Layer norm, 1 two-layer FFNN, times the stack number $\pmb{m}$:
Transformer Decoder
Given
- $\pmb{n}$ is # of decoder stacks
![]()
The total number of transformer decoder is: sum the number of 2 MHDPA, 3 Layer norm, 1 two-layer FFNN, times the stack number $\pmb{n}$:
References
- 1.Towards data science: Counting No. of Parameters in Deep Learning Models by Hand ↩
- 2.Towards data science: Animated RNN, LSTM and GRU ↩
- 3.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008). ↩