
Dynamic Programming (DP) is ubiquitous in NLP, such as Minimum Edit Distance, Viterbi Decoding, forward/backward algorithm, CKY algorithm, etc.
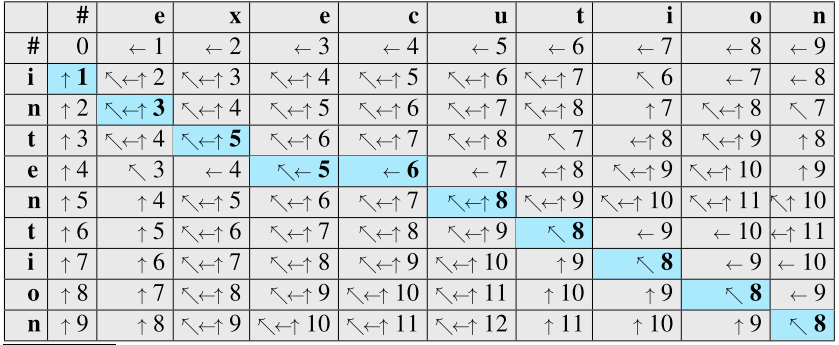
Minimum Edit Distance
Minimum Edit Distance (Levenshtein distance) is string metric for measuring the difference between two sequences.
Given two strings $a$ and $b$ (with length $|a|$ and $|b|$ respectively), define as the edit distance between $a[1 \cdots i]$ and $b[1 \cdots j]$, i.e. the first $i$ chars of $a$ and the first $j$ chars of $b$. The edit distance between two strings is $\text{D}(|a|, |b|)$.
Let the costs of insertion, deletion, substitution are 1,1 and 2, respectively.
That is,
Algorithms in Python:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Solution:
def minDistance(self, word1, word2):
"""
Levenshtein distance
:type word1: str
:type word2: str
:rtype: int
"""
m, n = len(word1) + 1, len(word2) + 1
dp = [[0 for _ in range(n)] for _ in range(m)]
for i in range(m):
dp[i][0] = i
for j in range(n):
dp[0][j] = j
for i in range(1, m):
for j in range(1, n):
# implementation 1
# --------------------------
# if word1[i - 1] == word2[j - 1]:
# sub_cost = 0
# else:
# sub_cost = 2
# dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1, dp[i - 1][j - 1] + sub_cost)
# implementation 2
# ===========================
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1, dp[i - 1][j - 1] + 2)
return dp[m - 1][n - 1]
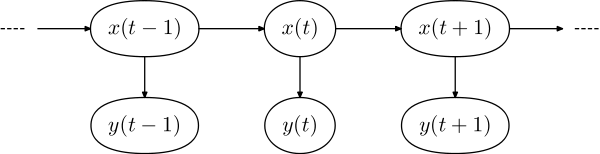
DP in HMMs
Hidden Markov Models (HMMs) describe the joint probability of its hidden(unobserved) and observed discrete random variables. It relies on the Markov assumption and output indenpendence.
- The observation sequence
- Let be a discrete random vriable with $K$ possible states. The transition matrix
- The initial state distribution(t=1) is
- The output/emission matrix
Thus the hidden markov chain can be defined by .
Forward algorithm
Forward algorithm is used to calculate the "belief state": the probability at time $t$, given the history of evidence.[1] Such process is also called filtering.
- The goal is to compute the joint probability , which requires marginalizing over all possible state sequence , the # of which grows exponentially with $t$.
- The conditional independence of HMM could help to perform calculation recursively.
- Time complexity: $O(K^2T)$
Forward algorithm:
- Init $t=0$, transition probabilities , emission probabilities , observed sequence $y_{1:t}$
for $t \leftarrow t+1, \cdots, T$:return
Viterbi Algorithm
Viterbi algorithm is to finding the most probable sequence of hidden states, i.e. Viterbi path.[2]
Input:
- The observation space
- state space
- initial probability array such that
- observation sequence
- transition matrix $A$ with size $K \times K$. stores the transition probability of transition from state to
- emission matrix $B$ of size $K \times N$, such that stores the probability of observing from state
Output:
- the most likely hidden state sequence
- Time complexity: $O(|S|^2T)$
- function Viterbi($O$,$S$, $\pi$, $Y$, $A$, $B$): returns $X$
- for state i = do
- Viterbi init step $0 \rightarrow 1$ :
- Backtrack init step $0 \rightarrow 1$ :
- for observation $j = 2,3,\cdots, T$:
- for state $i = 1,2,\cdots,K$:
- Viterbi records the best prob
- Backpointer saves the best backpointer
- for state $i = 1,2,\cdots,K$:
- best path prob.
- best path pointer
- for $j=T, T-1, \cdots, 2$:
- do back tracking $z_{j-1} \leftarrow T_2[z_j,j]$
- Prev hidden state
- return
- for state i = do
Baum-Welch algorithm
Baum-Welch algorithm, as a speciqal case of EM algorithms, uses the forward-backward algorithm to find the maximum likelihood estimate of the unknown parameters of a HMM given a set of observed feature vectors.
The local maximum
Forward process
Let represent the probability of the observation of :
backward process
Let denote the probability of the sequence starting at time $t$.
update
The prob. of being state $i$ at time $t$ given the observation $Y$ and parameters $\theta$
The prob. of being state $i$ and $j$ at times $t$ and $t+1$ respectively given the observation $Y$ and parameter $\theta$
Update the HMM $\theta$:
- $\pi$ at state $i$ at time 1:
- the transition matrix $A$.
the emission matrix $B$
- where
CKY algorithm
TBD