
Machine reading comprehension aims to answer questions given a passage or document.
Symbol matching models
Frame-Semantic parsing
Frame-semantic parsing identifies predicates and their arguments, i.e. “who did what to whom”.
Word Distance
Sum the distances of every word in $q$ to their nearest aligned word in $d$
Teaching Machines to Read and Comprehend
Deep LSTM Reader
In NMT, deep LSTMs have shown a remarkable ability to embed long sequences into a vector representation, which contains enough information to generate a full translation in another language.[2]
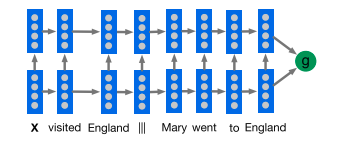
Deep LSTMs feed out documents one word at a time into a Deep LSTM encoder, after a delimiter, followed by a query ($d \oplus ||| \oplus q$, or $q \oplus ||| \oplus d$ ). The network predicts which token in the document answers the query.
Attentive Reader
Limitations of the Deep LSTM Reader:
- fixed width hidden vector
- Solution: the Attentive Reader employs a finer grained token level attention mechanism, where the tokens are embedded given their entire future and past context in the input documents.
Attentive Reader encodes the document $d$ and the query $q$ with two separate 1-layer bi-LSTMs.[2]
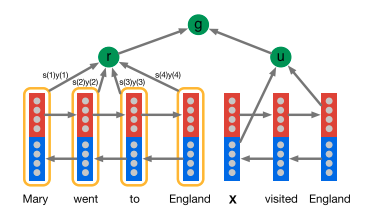
When encoding the query $q$, the encoding $u$ of a query with length $|q|$ is the concatenation of the final forward and backward outputs:
When encoding the document $d$, each token at position $t$ is:
The representation $r$ of $d$ is a weighted sum of these output vectors. The weights can be interpreted as the degree to which the network attends to a particular token in the document $d$ when answering the query:
Finally, the joint document and query embedding is:
Impatient Reader
The Attentive Reader focuses on the passage of a context document that are most likely to inform the answer to the query.
Impatient Reader can reread from the document as each query token is read.[2]
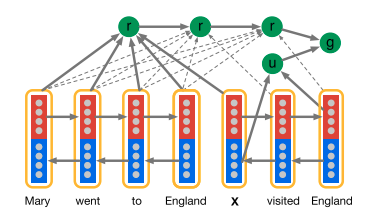
At each token $i$ of the query $q$, the model computes the document representation vector $r(i)$ with the bidirectional embedding :
The attention mechanism allows the model to recurrently accumulate information from the document as it sees each query token, ultimately outputting a final joint document query representation for the answer prediction
Attention Sum Reader
- For
cloze-styleQA. [6]
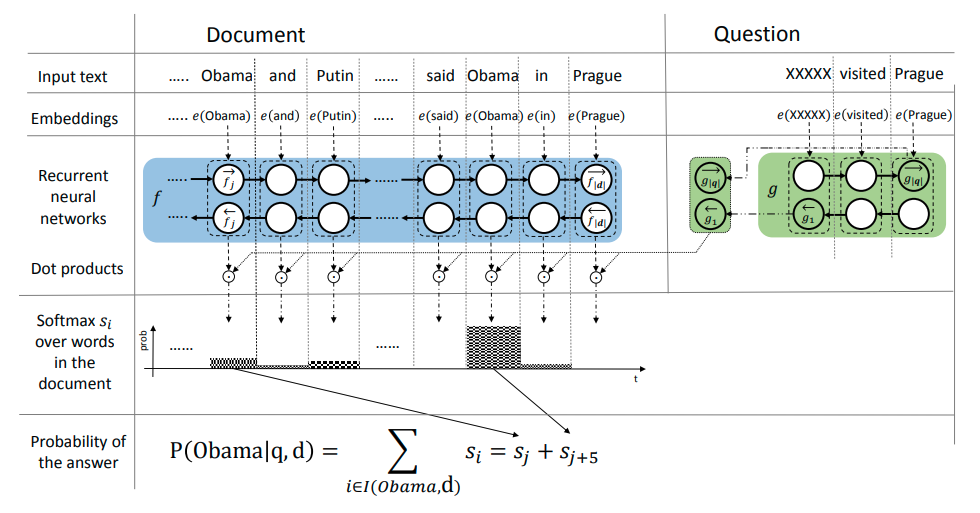
- Compute the vector embedding for the query.
- Compute the vector embedding of each individual word in the context of the whole document. The word embedding is a look-up table $V$.
- Dot product between the question embedding and the contextual embedding. Select the most likely answer.
EpiReader
Pointer Nets
Problems:
- Conventional seq2seq architecture can only applies softmax distribution over a fixed-sized output dictionary. It cannot handle problems where the size of the output dictionary is equal to the length of the input sequence.[8]
where is a sequence of $n$ vectors and is a sequence of $m(\mathcal{P})$ indices.
The parameters are learnt by maximizing the conditional probabilities of the training set:
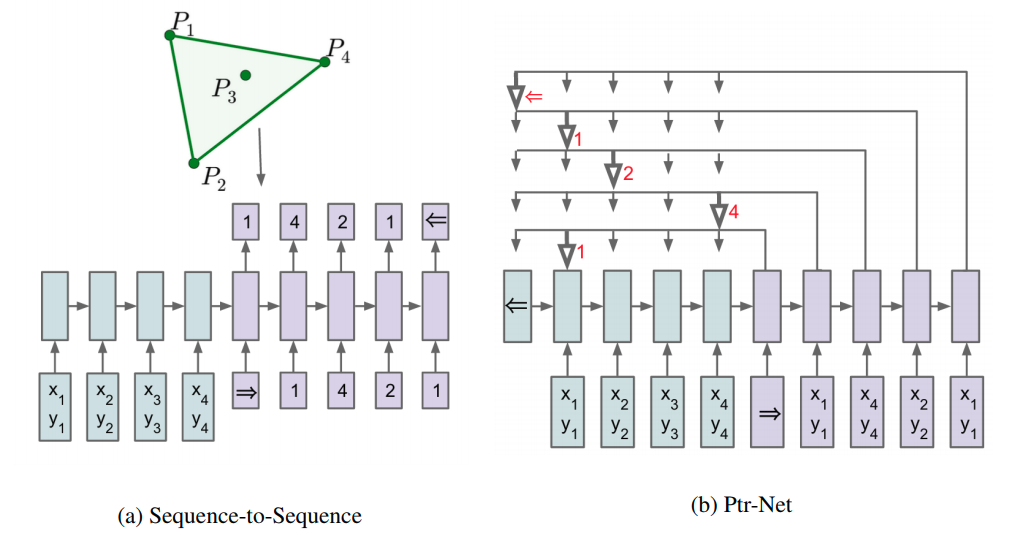
Solution: Pointer Net.
Applies the attention mechanism:
where softmax normalizes the vector $u^i$ (of length $n$) to be an output distribution over the dictionary of inputs. And $v$,, are learnable parameters of the output model.
Here, we do not blend the encoder state to propagate extra information to the decoder. Instead, we use as
pointers to the input elements.
Ptr Netscan be seen as an application ofcontent-based attention mechanisms.
EpiReader
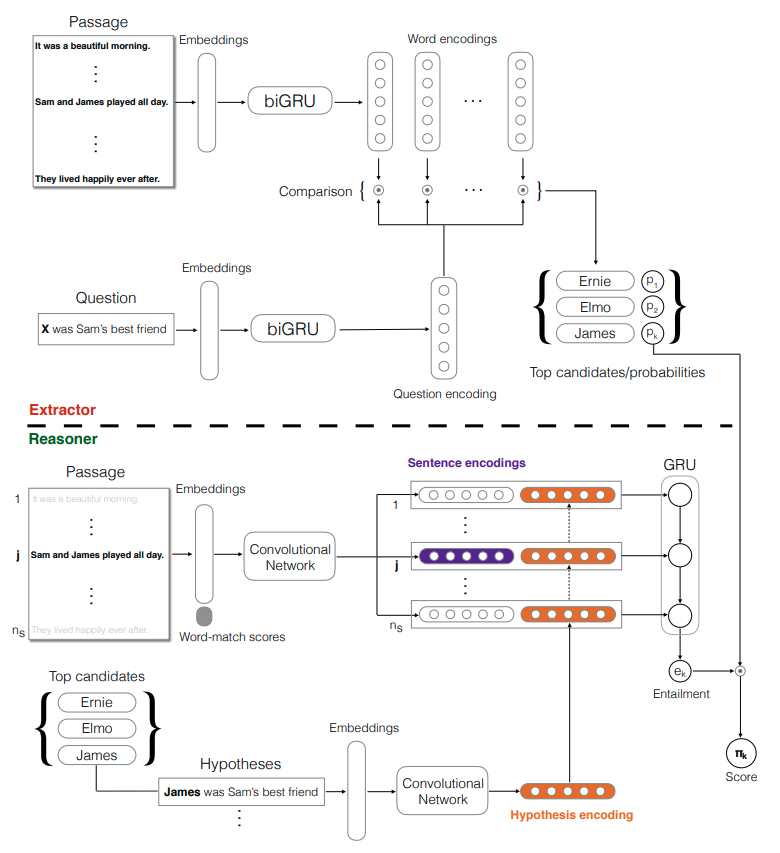
Extractor: Pointer Nets
- Use bi-RNNs to encode passage and question , where and represents the parameters of the text and question encoders, and are matrix representations of the texts and questions (comprising $N$ words and words separately) . Concatenate the last hidden states of forward and backward GRU, denoted
Take the inner product of text and question representations, followed by a softmax. The probability that the $i$-th word in text $\tau$ answers :
Compute the total probability that word $w$ is the correct answer:
- The extractor take the $K$ highest word probabilities with the corresponding $K$ most probable answer words
Reasoner
- Insert the answer candidates into the question sequence $\mathcal{Q}$ at the placeholder location, which forms $K$ hypotheses ${ \mathcal{H}_1, \cdots, \mathcal{H}_K }$
- For each hypothesis and each sentence of the text: whose columns are embedding vectors for each word of sentence , whose columns are the embedding vectors for each word in the hypothesis
- Augment with
word-matching features. The first row is the inner product of each word embedding in the sentence with the candidate answer embedding; the second row is the maximum inner product of each sentence word embedding with any word embedding in the question. - Then the augmented and are fed into two different ConvNets, with filters and , where $m$ is the filter width. After ReLU and maxpooling op, we can obtain the representations of the text sentence and the hypothesis: , , where is the number of filters.
Then compute a scalar similarity score representations using bilinear form:
where is a trainable parameter.
Concat the similarity score with the sentence and hypothesis representations to get:
- Pass to a GRU, and the final hidden state is given to an FC layer, followed by a softmax op.
Finally, combine the output of the Reasoner and the Extractor at the same time when minimizing the loss function. (See the original paper[9] for details)
Bi-Directional Attention Flow (BiDAF)
Highway Networks
- A plain feedforward NN consists of $L$ layers where the $l^{th}$ layer $(l \in { 1,2,\cdots,L})$ applies a non-linear transformation $H$ (with parameter ) on its input $\pmb{x}$ to the output $\pmb{y}$.
$H$ is usually a affine transformation followed by a non-linear activation function.
Highway Network:
- Additionally define $T$ as the
transform gate, $C$ as thecarry gate. Intuitionally, these gates express how much of the output is produced by transforming the input and carrying it. For simplicity we set $C = 1 - T$, giving
In particular,
- Additionally define $T$ as the
BiDAF
Problems:
Previous models summarized the context paragraph into a fixed-size vector, which could lead to the information loss.
Solution: the attention is computed at each time step, and the attended vector at each time step, along with the representations from previous layers, is allowed to flow through to the subsequent modeling layer.
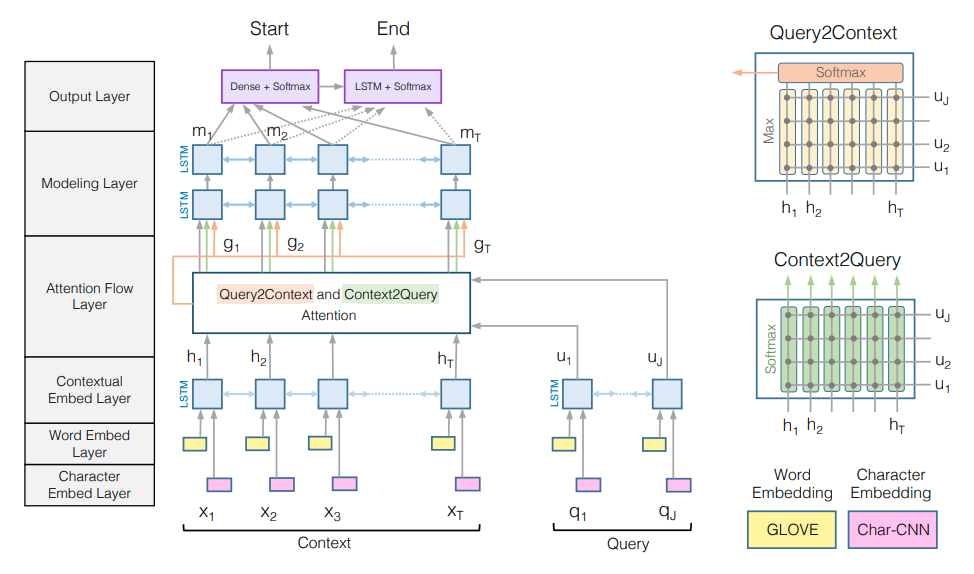
Char embedding layer
Let and represent the words in the input context paragraph and query. Use TextCNNs to encode the char-level inputs, followed by a max-pooling over the entire width to obtain a fixed-size vector for each word.
Word embedding layer
Applied pretrained word embeddings, GloVe.
Then concatenate the char and word embedding vectors, feed them into a 2-layer Highway Network. The outputs are $\pmb{X} \in \mathbb{R}^{2d \times T}$ for the context, and $\pmb{Q} \in \mathbb{R}^{d \times J}$ for the query.
Contextual embedding layer
Use bi-LSTMs to encode the context and query representations, by concatenating the last hidden states of each direction. We obtain $\pmb{H} \in \mathbb{R}^{2d \times T}$ from the context word vectors $\pmb{X}$, $\pmb{U} \in \mathbb{R}^{2d \times J}$ from query word vectors $\pmb{Q}$
The first three layers are used to extract features form the query and context at different levels of granularity, akin to mlti-stage feature computation of CNNs in computer vision field.
Attention flow layer
- Inputs: the context $\pmb{H}$ and the query $\pmb{U}$.
- Outputs: query-aware vector representation of context words, $\pmb{G}$, along with previous contextual embedding
- Similarity matrix between the contextual embeddings of the context($\pmb{H}$) and the query ($\pmb{U}$), where $\pmb{S}_{tj}$ indicates the similarity between the $t$-th context word and $j$-th query word:where $\alpha$ is a trainable scalar function that encodes the similarity between its input vectors, is $t$-th column vector of $\pmb{H}$ and is $j$-th column vector of $\pmb{U}$.
Then use $\pmb{S}$ to obtain the attentions and the attended vectors in both directions.
- Context-to-query Attention: context-to-query(C2Q) attention signifies which query words are most relevant to each context word. Let represent the attention weights on the query words by $t$-th context word, for each $t$. The attention weight: Each attended query vector: Here $\tilde{\pmb{U}}$ is a 2$d$-by-$T matrix.
- Query-to-context Attention: query-to-context(Q2C) attention signifies which context words have the closest similarity to one query word and hence crucial for answering. The attention weights on the context words: where the maximum function () is performed across the column.
The attended context vector is
Finally, concatenate the contextual embeddings and attention vectors:
where is the $t$-th column vector, $\beta$ is a trainable vector function that fuses three input vectors. In the experiments,
Modeling layer
- Use bi-LSTMs to encode, obtaining a matrix
Output layer
- Application-specific
For QA-tasks, find the sub-phrase of the paragraph to answer the query. We obtain the start index over the entire paragraph by:
For the end index of the answer phrase, we pass $\pmb{M}$ into another bi-LSTM and obtain $\pmb{M}^2 \in \mathbb{R}^{2d \times T}$
Training: minimize the sum of the negative log probabilities of the true start and end indices by the predicted distributions, averaged over all examples:
Match-LSTM and Answer pointer
Match-LSTM
- It is used for textual entailment (RTE). In RTE, given two sentences, one premise and another hypothesis, predict where the premise entails the hypothesis.
- Match-LSTMs go through the hypothesis sequentially. At each position of the hypothesis, apply attention mechanism to obtain a weighted vector representation of the premise. This weighted vector is combined with current token representation of the hypothesis, then fed to an LSTM.
- Match-LSTMs sequentially aggregates the matching of the attention-weighted premise to each token of the hypothesis.
Architecture
- Given the matrix of passage $\pmb{P} \in \mathbb{R}^{d \times P}$, question $\pmb{Q} \in \mathbb{R}^{d \times Q}$, where the $P$ and $Q$ os the length (# of tokens) of the passage and question, $d$ is the dimension of word embeddings.
- The answer is a sequence of inteegers , where each is an integer between 1 and $P$, indicating the certain region in the passage. Or select only the start and end index from input passages, represented as , where and are integers between 1 and $P$.
- Overall, given .
- Goal: identify a subsequence from the passage as the answer to the question.
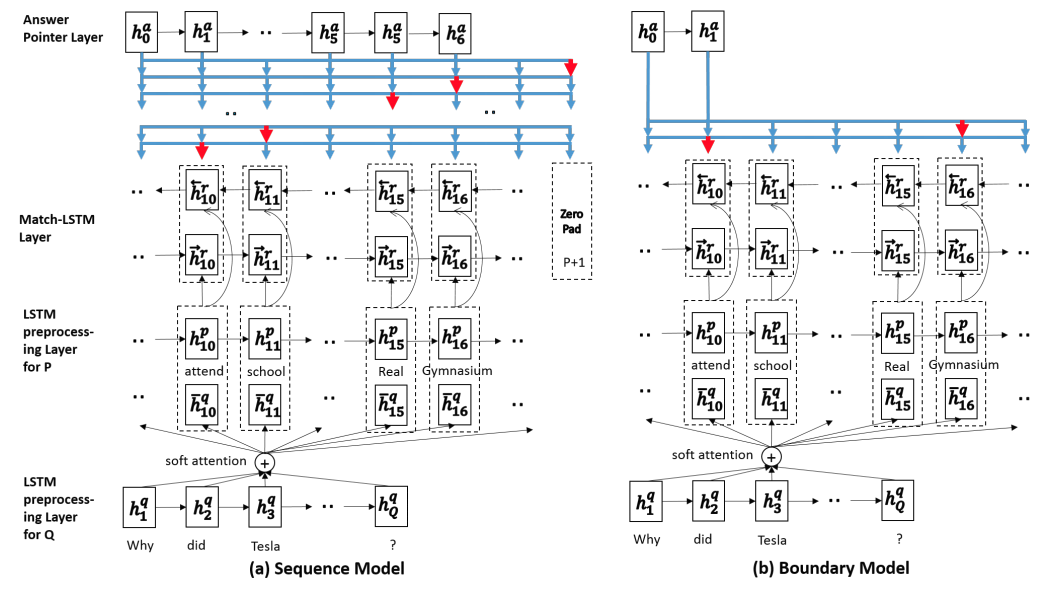
LSTM Preprocessing layer
- In order to incorporate contextual information to the representation of each token, apply one-dimensional LSTM to process the passage and the question separately. The output and are hidden representations of the passage and the question, where $l$ is the hidden dimension.
Match-LSTM layer
- Apply match-LSTM model by sequentially goes through the passage, obtaining the weighted representation of question.
At position $i$ of the passage, it first uses the standard word-by-word attention mechanism to obtain attention weight :
where , , , $\pmb{b}^p, \pmb{w} \in \mathbb{R}$ are learnable, is the hidden vector of the one-directional match-LSTM at previous position. The outer product () generates a matrix or row vector by repeating the vector or scalar on the left for $Q$ times.
Then combine the weighted vector with original representations:
The vector is fed to a one-directional LSTM, so-called match-LSTM:
where
Further apply a match-LSTM in the reverse direction.
Let represent the hidden states and represent .
Define as the concatenation:
Answer pointer layer
The sequence model
- Compute the attention weight vector :where is the concatenation of $\pmb{H}^r$ with a zero vector, defined as
Then model the probability of generating the answer sequence as:
- Minimize the loss:
The boundary model
- Predict the start and end index from input sequences. The probability is modeled as:
Gated self-matching networks
- Firstly, apply bi-RNNs to process the question and passage separately; then match the question and passage with gated attention-based RNNs, obtaining question-aware representation for the passage. On top of that, apply self-matching attention to aggregate evidence from the whole passage and refine the passage representation, which is then fed to the output layer to predict the boundary of the answer span.
Question and passage encoder
- Given question and passage .
- Concatenate the respective word-level embeddings ( and ) and char-level embeddings ( and ). The char-level embedding is generated by concatenating the final hidden state of bi-directional RNNs, which is helpful to handel OOV words.
- Then use a bi-RNN to produce the new representation of all words in the question and passage respectively:
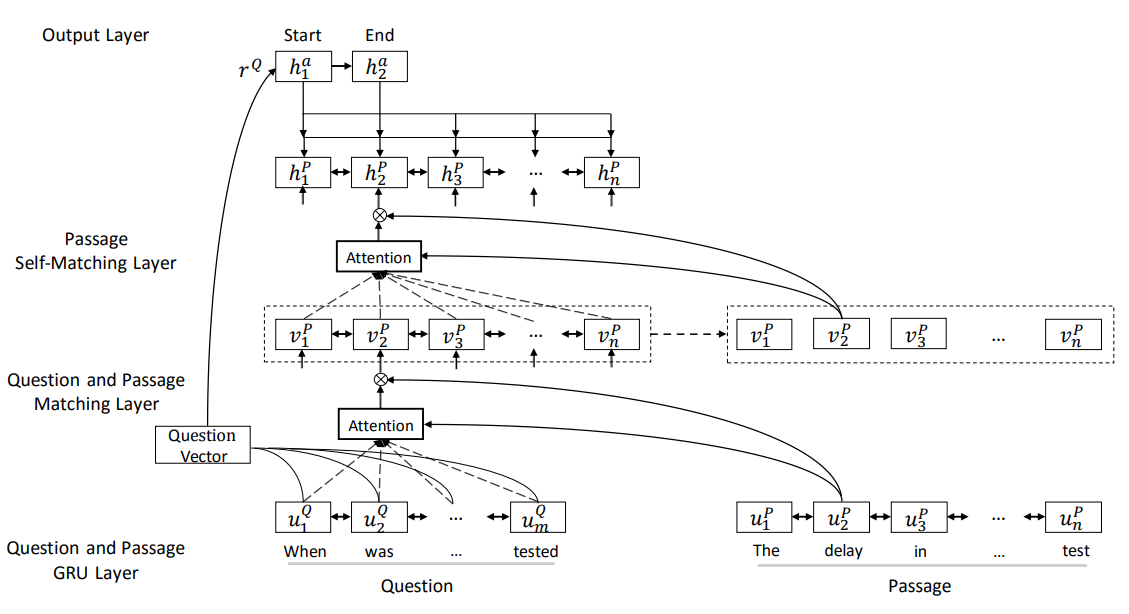
Gated attention-based RNNs
- Incorporate an additional gate to determine the importance of information in the passage regarding a question.
Rocktäschel et al.(2015)[15] proposed generating sentence-pair representation via soft-alignment of words in the question and passage:
where is an attention-pooling vector of the whole question $u^Q$:
Match-LSTM(Wang and Jiang, 2016) takes as an additional input into the recurrent network:
To determine the importance of passage parts and attend to the ones relevant to the question, add another gate to the input of RNNs:
Self-matching attention
Match the question-aware passage representation against itself.
where is an attention pooling vector of the whole passage $v^P$:
An additional gate as in gated attention-based RNNs is applied to to adaptively control the input of RNNs.
Output layer
- Use pointer net to select the start position ($p^1$) and end position ($p^2$) from the passage:
- Utilize the question vector $r^Q$ as the initial state of the answer RNNs:
Attention-over-Attention Reader
Contextual embedding for document $\mathcal{D}$ and query $\mathcal{Q}$ using bi-GRUs: ,
Pair-wise matching score:
Given $i$-th word of the document and $j$-th word of query, we compute a matching score by dot product, forming a matrix $M \in \mathbb{R}^{\mathcal{D}*\mathcal{Q}} $, where the value of $i$-th row and $j$-th column is filled by $M(i,j)$:Individual document-level attentions
Apply acolumn-wise softmaxfunction to get distribution of each column, where each column is an individual document-level attention considering a single query word (one element in rows). Let $\alpha(t) \in \mathbb{R}^{|\mathcal{D}|}$ is aquery-to-document attentionat time $t$:
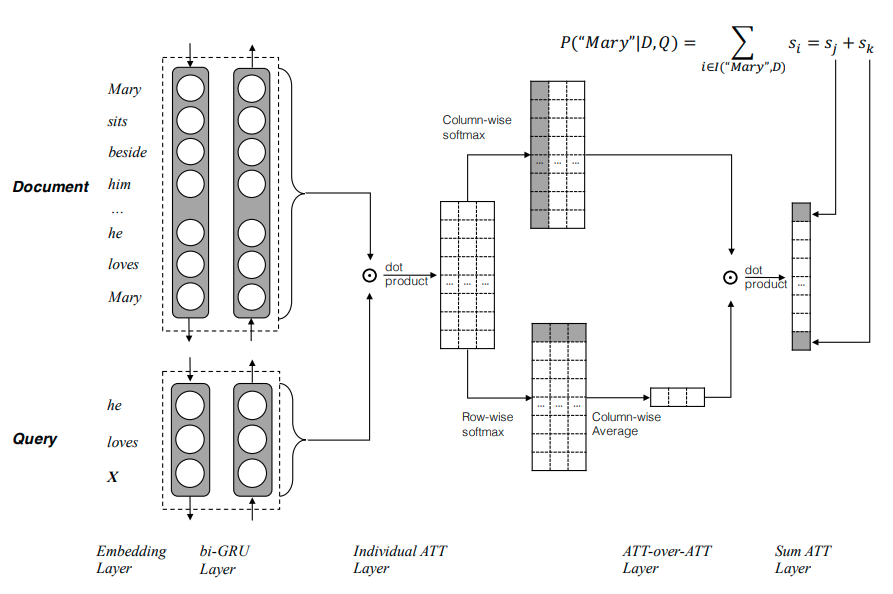
Attention-over-Attention [7]
- First, for each document word at time $t$, compute the “importance” distribution on the query, indicating which query words are most important given a single document word.
- Apply
row-wise softmaxfunction to the pair-wise matching matrix $M$ to get query-level attentions. The document-to-query attention $\beta(t) \in \mathbb{R}^{|\mathcal{Q}|}$ is; - We average the attention for each query word:
- Calculate the dot product of $\alpha$ and $\beta$ to get the
attended document-level attention:
Predictions
The final output is mapped to the vocabulary space $V$, rather than document-level attention $|\mathcal{D}|$:where $I(w, \mathcal{D})$ indicate the positions that word $w$ appears in the document $\mathcal{D}$.
The training objective is to maximize the log-likelihood of the correct answer:
R-Net
Overview:
- First, the question $Q$ and passage $P$ are processed by a bi-RNNs separately.
- Then, match the $Q$ and $P$ with gated attention-based RNNs, obtaining question-aware representation for the passage $P$
- Apply self-matching attention to aggregate evidence from the whole passage and refine the passage representation.
- Feed into the output layer to predict the boundary of the answer span.
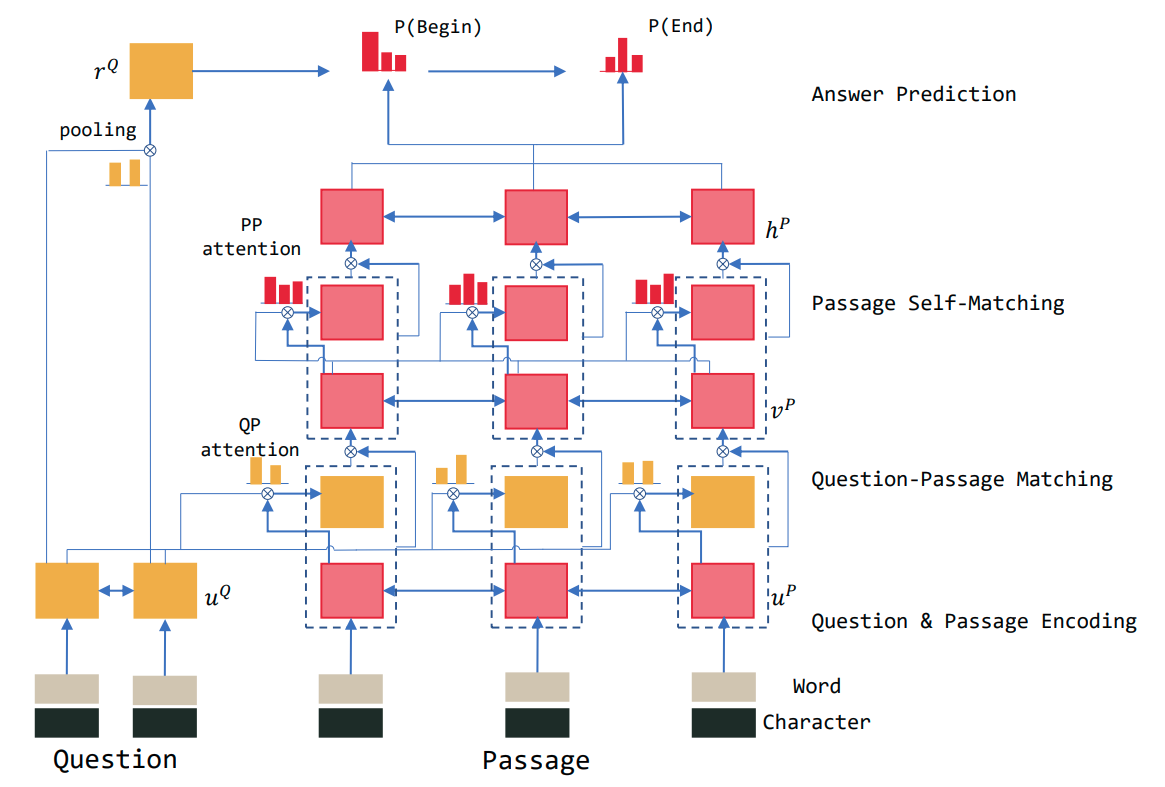
Question and passage encoder
Consider a question and a passage .
- First convert words to word-level embeddings and and char-level embeddings and (generated by the final hidden states of bi-RNNs, which benefits for OOV tokens)
- Then use a bi-RNN to encode the question and passage respectively:
Gated attention-based RNNs
Given question representation and passage representation .
- Generate sentence-pair representation with soft-alignment of words in the question and passage:[4]where is an attention-pooling vector of the whole question $(u^Q)$:
Each passage representation dynamically incorporates aggregated matching information from the whole question.
or
- match-LSTM[5]. Take as an additional input into the RNNs:To determine the importance of passage parts and attend to the ones relevant to the question, add another gate to the input of RNN:
Self-matching attention
Given question-aware passage representation . One problem is that, it has very limited knowledge of context,
Solution: match the question-aware passage representation against itself.
where is an attention-pooling vector of the whole passage $(v^P)$:
An additional gate as in gated attention-based RNNs is applied to to adaptively control the input of RNNs.
Output layer
Given the passage representation
Use pointer networks to predict the start and the end position of the answer.
Attention mechanism is utilized as the pointer to select the start position $(p^1)$ and end position $(p^2)$:
here represents the last hidden state of the answer RNNs(pointer net).
The input of the answer RNN is the attention-pooling vector:
When predicting the start position, represents the initial hidden state of the answer RNN. We use the question vector $r^Q$ as the initial state of the answer RNN. is an attention-pooling vector of the question based on the parameter :
- Loss: the sum of negative log probabilities of the label start and end position by the predicted distributions.
Reasoning Network (ReasoNet)
- ReasoNet mimics the inference process of human readers by introducing a termination state in the inference with reinforcement learning. The state can decide whether to continue the inference to the next turn after digesting intermediate information, or to terminate the whole inference when it concludes that existing information is sufficient to yield an answer.
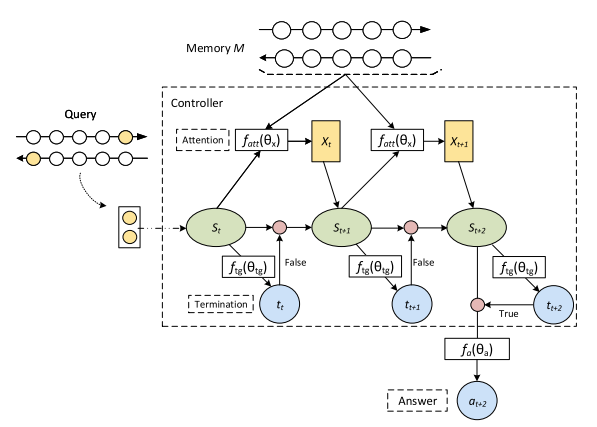
- The stochastic inference process can be seen as a POMDP. The state sequence is controlled by an RNN sequence model. The ReasoNet performs an answer action at $T$-th step, which implies that the termination gate variables .
- The ReasoNet learns a stochastic policy with parameters $\theta$ to get a distribution of termination actions if the model decides to stop at the current step.

The expected reward for an instance is:
The reward can only be received at the final termination step when an asnwer action is performed.
$J$ can be maximized by directly applying gradient based optimization methods:
Motivated by REINFORCE algorithm, we compute :
where and can be updated via online moving average approach:
Cross-passage answer verification
- Compute the question-aware representation for each passage. Employ a Pointer network to predict the start and end position of the answer in the module of answer boundary prediction.
- Meanwhile, with the answer content module, we estimate whether each word should be included in the answer.
- In the answer verification module, each answer candidate can attend to the other answer candidates to collect supportive information and compute one score for each candidate to indicate whether it is correct or not according to the verification.
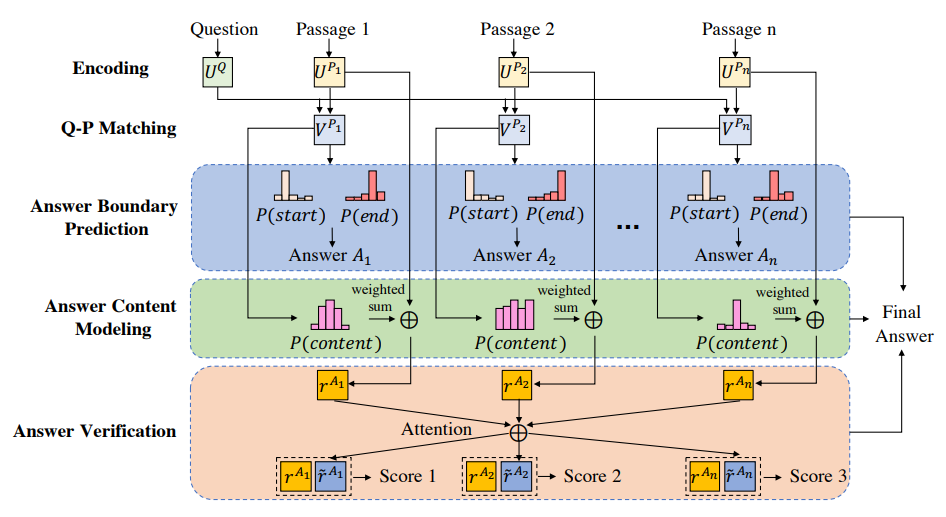
Question and passage modeling
Encoding: map each word into the vector space by concatenating the word embedding and sum of its char-embeddings. Then employ bi-LSTM to encode the question $\pmb{Q}$ and passages :
where , are word-level and char-level embeddings of the $t$-th word.
Q-P Matching: use the attention flow layer to conduct Q-P matching in two directions. The similarity between the $t$-th word in the question and $k$-th word in passage $i$ is:
Then the context-to-question attention and question-to-context attention is applied as aforementioned BiDAF to obtain the question-aware passage representation .
The match output:
Answer boundary prediction
Employ Pointer net to compute the probability of each word to be the start or end position of the span:
The probability of $k$-th word in the passage to be the start and end position of the answer is obtained as and
- Minimize the negative log probabilities of the true start and end indices:where $N$ is the # of samples in the dataset and , are the gold start and end positions.
Answer content modeling
We predict whether each word should be included in the context of the answer. The content probability of the $k$-th word is computed as:
Words within the answer span are labeled as 1 and the other 0. The loss is averaged cross entropy:
The content probabilities provide another view to measure the quality of the answer in addition to the boundary. Moreover, with these probabilities, we can represent the answer from passage $i$ as a weighted sum of all word embeddings:
Cross-passage answer verification
- The boundary and content model focus on modeling within a single passage, with little consideration of the cross-passage information.
- Given the representation of the answer candidates from all passages , each answer candidate then attends to other candidates to collect supportive information via attention mechanism:
Here is the collected verification information from other passages with attention weights. Then we pass it together with the original to a FC layer:
Then normalize the score:
The loss function:
where is the index of the correct answer in all the answer candidates of the $i$-th instance.
Joint training
The joint objective function:
QANet
Previous models relied on Recurrent neural nets, slowing down the training and inference speed. QANet[17] applied exclusively convolutions and self-attentions to speed up the training process.
QANet architecture
Input embedding layer
- Concatenate the pretrained word embedding and char embedding : . Also adopt a two-layer high-way network on top of the representation.
Embedding encoder layer
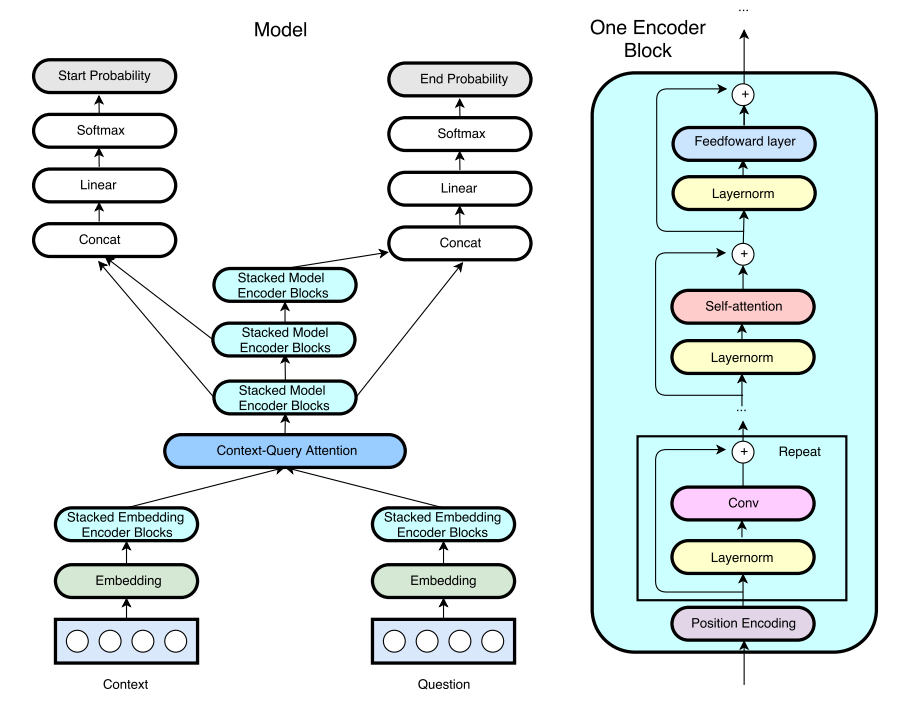
- A stack of the building block: [convolution-layer $\times$ # + self-attention layer + feed-forword layer]
Context-query attention layer
Firstly compute the similarity matrix $S$ between each word pair of context $C$ and query $Q$, i.e. $S \in \pmb{R}^{n \times m}$. We then normalize each row of $S$ by applying the softmax function, getting a matrix $\bar{S}$. Then the context to query attention is computed as: $A = \bar{S} \cdot Q^T \in \pmb{R}^{n \times d}$.
The similarity function is the trilinear function:
where $\odot$ is the element-wise multiplication and is a trainable variable.
The query-to-context attention is:
where $\overline{\overline{S}}$ is normalized matrix of $S$ along column with softmax function.
Model encoder layer
The input at each position is $[c,a, c \odot a, c \odot b]$, where $a$ and $b$ are respectively a row of attention matrix $A$ and $B$.
Output layer
Predict the probability of each position in the context being the start and end of an answer span
where , are two trainable variables and , , are the outputs of the three model encoders, from bottom to top.
Loss function
Tricks
- Data augmentation with back-translation
References
- 1.Jason Weston, Sumit Chopra, and Antoine Bordes (2014). Memory networks. arXiv preprint arXiv:1410.3916. ↩
- 2.Hermann, K.M., Kociský, T., Grefenstette, E., Espeholt, L., Kay, W., Suleyman, M., & Blunsom, P. (2015). Teaching Machines to Read and Comprehend. NIPS. ↩
- 3.Kadlec, R., Schmid, M., Bajgar, O., & Kleindienst, J. (2016). Text understanding with the attention sum reader network. CoRR, abs/1603.01547. ↩
- 4.Rocktäschel, T., Grefenstette, E., Hermann, K.M., Kociský, T., & Blunsom, P. (2016). Reasoning about Entailment with Neural Attention. CoRR, abs/1509.06664. ↩
- 5.Wang, S., & Jiang, J. (2016). Learning Natural Language Inference with LSTM. HLT-NAACL. ↩
- 6.Kadlec, R., Schmid, M., Bajgar, O., & Kleindienst, J. (2016). Text Understanding with the Attention Sum Reader Network. CoRR, abs/1603.01547. ↩
- 7.Cui, Y., Chen, Z., Wei, S., Wang, S., & Liu, T. (2017). Attention-over-Attention Neural Networks for Reading Comprehension. ACL. ↩
- 8.Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer Networks. NIPS. ↩
- 9.Trischler, A., Ye, Z., Yuan, X., Bachman, P., Sordoni, A., & Suleman, K. (2016). Natural Language Comprehension with the EpiReader. EMNLP. ↩
- 10.Seo, M.J., Kembhavi, A., Farhadi, A., & Hajishirzi, H. (2017). Bidirectional Attention Flow for Machine Comprehension. CoRR, abs/1611.01603. ↩
- 11.Wang, S., & Jiang, J. (2017). Machine Comprehension Using Match-LSTM and Answer Pointer. CoRR, abs/1608.07905. ↩
- 12.Wang, W., Yang, N., Wei, F., Chang, B., & Zhou, M. (2017). R-NET: Machine reading comprehension with self-matching networks. Natural Lang. Comput. Group, Microsoft Res. Asia, Beijing, China, Tech. Rep, 5. ↩
- 13.Shen, Y., Huang, P., Gao, J., & Chen, W. (2016). ReasoNet: Learning to Stop Reading in Machine Comprehension. CoCo@NIPS. ↩
- 14.Wang, W., Yang, N., Wei, F., Chang, B., & Zhou, M. (2017). Gated Self-Matching Networks for Reading Comprehension and Question Answering. ACL. ↩
- 15.Rocktäschel, T., Grefenstette, E., Hermann, K.M., Kociský, T., & Blunsom, P. (2016). Reasoning about Entailment with Neural Attention. CoRR, abs/1509.06664. ↩
- 16.Wang, Y., Liu, K., Liu, J., He, W., Lyu, Y., Wu, H., Li, S., & Wang, H. (2018). Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification. ACL. ↩
- 17.Yu, A.W., Dohan, D., Luong, M., Zhao, R., Chen, K., Norouzi, M., & Le, Q.V. (2018). QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. CoRR, abs/1804.09541. ↩