
The landscape of algorithms in modern RL.
A taxonomy of RL algorithms (OpenAI SpinningUp)

Types of RL algorithms (UCB CS294-112)
- Policy gradient: directly differentiate the above objective
- Value-based: estimate value function or Q-funtion of the optimal policy (no explicit policy)
- Actor-critic: estimate value function or Q-function of the curent policy, use it to improve policy
- Model-based RL: estimate the transition model, and then
- Use it for planning (no explicit policy)
- Use it to improve a policy
- Something else
Model-free v.s model-based RL
- Branching point:
whether the agent has access to (or learns) a model of the environment. By a model of the environment, we mean a function which predicts state transition and rewards.
Advantages of having a model:
- Allows the agent to plan by thinking ahead, seeing what would happen for a range of possible choices, and explicitly deciding between its options. Agents can then distill the results from planning ahead into a learned policy. E.g. AlphaZero [1].
Disadvantages of having a model:
- A ground-truth model of the environment is usually not available to the agent. Agents have to learn he model purely from the experience, and the model-learning is fundamentally hard.
What to learn
Branching point: what to learn, include
- Policies, (stochastic or deterministic)
- Action-value functions (Q-functions)
- Value functions
- and/or environment models
What to learn in model-free RL
Policy optimization
The policy is denoted as . Optimize the parameters $\theta$ either
- directly by
gradient ascenton the performance objective
or - indirectly by
maximizing local approximationof
on-policy: each update uses data collected from the most recent version of the policy. Policy optimization also usually involves learning an approximator for the on-policy value function $V^{\pi}(s)$.
Example algorithms:
- A2C / A3C: performs gradient ascent to directly maximize the performance [2]
- PPO: updates indirectly maximize performance, by instead maximizing a surrogate objective function, which gives a conservative estimate for how much $J(\pi_{\theta})$ will change as a result of the update. [3]
Q-learning
Methods learn an appoximator for the optimal action-value function, $Q^*(s,a)$.
- Typically the objective function is based on the Bellman equation
Off-policy: each update can use data collected at any point during training. regardless of how the agent was choosing to explore the environment when the data is obtained.
The actions taken by the Q-learning:
Example algorithms:
Trade-offs between policy gradient and Q-learning
Policy optimization:
- Strength: directly optimize the thing you want(i.e. policy); stable and reliable
Q-learning
- Indirectly optimize for agent performance by training to satisfy a self-consistency equation
- less stable
- more sample efficient
Trade-of algorithms:
- DDPG: concurrently learns a deterministic policy and a Q-function by using each to improve the other [5]
- SAC: a variant using stochastic policies, entropy regularization, and other tricks to stablize learning [7]
What to learn in model-based RL
Pure planning
- MBMF [14]
Expert iteration
- ExIt [16].
- AlphaZero
Data augmentation for Model-free methods
Embedding planning loops into policies
- I2A [13]
RL problems
a. Different tradeoffs
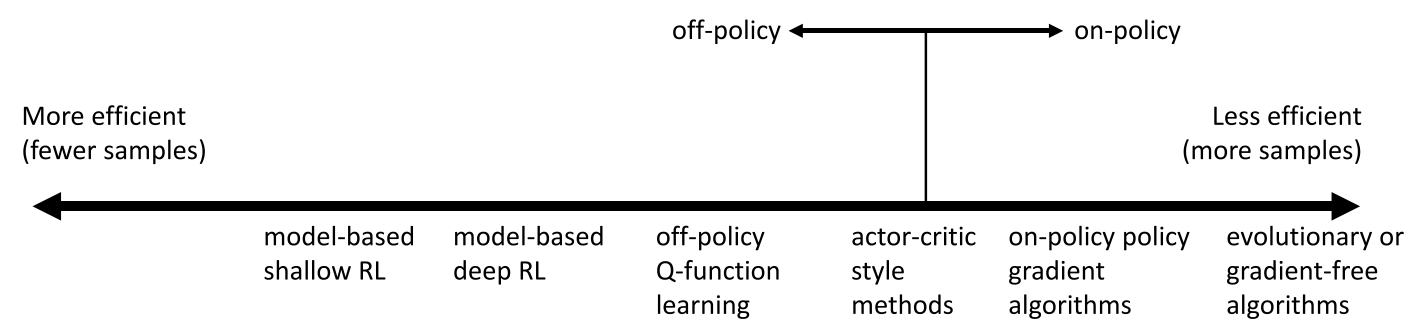
Sample efficiency
- Sample efficiency = how many samples do we need to get a good policy?
![upload successful]()
- Most important question: is the algorithm off policy?
- Off policy: able to improve the policy without generating new samples from that policy
- On policy: each time the policy is changed, even a little bit, we need to generate new samples
Stability & ease of use
- Does it converge?
- And if it converges, to what?
- And does it converge every time?
- Supervised learning: almost
alwaysgradient descent - Reinforcement learning: often
notgradient descent- Q-learning: fixed point iteration
- Model-based RL: model is not optimized for expected reward
- Policy gradient:
isgradient descent, but also often the least efficient!
- Value-function fitting
- At best, minimizes error of fit
"Bellman error"- Not the same as expected reward
- At worst, doesnot optimize anything
- Many popular deep RL value fitting algorithms are not guaranteed to converge to anything in the non-linear case
- At best, minimizes error of fit
- Model-based RL
- Model minimizes error of fit
- This will converge
- No gurantee that better model = better policy
- Model minimizes error of fit
- Policy gradiuent
- The only one that actually performs gradient descent(ascent) on the true objective
b. Different assumptions
- Stochastic or deterministic?
- Continuous or discrete?
- Episodic or infinite horizon?
- Full observability
- Generally assumed by value function fitting methods
- Can be mitigated by adding recurrence
- Episodic learning
- Often assumed by pure policy gradient methods
- Assumed by some model-based RL methods
- Continuous or smoothness
- Assumed by some continuous value function learning methods
- Often assumed by some model-based RL methods
c. Different things are easy or hard in different settings?
- Easier to represent the policy?
- Easier to represent the model?
References
- 1.AlphaZero : Silver et al, 2017 ↩
- 2.A2C / A3C (Asynchronous Advantage Actor-Critic): Mnih et al, 2016 ↩
- 3.PPO (Proximal Policy Optimization): Schulman et al, 2017 ↩
- 4.TRPO (Trust Region Policy Optimization): Schulman et al, 2015 ↩
- 5.DDPG (Deep Deterministic Policy Gradient): Lillicrap et al, 2015 ↩
- 6.TD3 (Twin Delayed DDPG): Fujimoto et al, 2018 ↩
- 7.SAC (Soft Actor-Critic): Haarnoja et al, 2018 ↩
- 8.DQN (Deep Q-Networks): Mnih et al, 2013 ↩
- 9.C51 (Categorical 51-Atom DQN): Bellemare et al, 2017 ↩
- 10.QR-DQN (Quantile Regression DQN): Dabney et al, 2017 ↩
- 11.HER (Hindsight Experience Replay): Andrychowicz et al, 2017 ↩
- 12.World Models: Ha and Schmidhuber, 2018 ↩
- 13.I2A (Imagination-Augmented Agents): Weber et al, 2017 ↩
- 14.MBMF (Model-Based RL with Model-Free Fine-Tuning): Nagabandi et al, 2017 ↩
- 15.MBVE (Model-Based Value Expansion): Feinberg et al, 2018 ↩
- 16.Anthony, T., Tian, Z., & Barber, D. (2017). Thinking Fast and Slow with Deep Learning and Tree Search . NIPS. ↩
- 17.OpenAI, Spinning Up, Part 2: Kinds of RL algorithms ↩