
Summary of word tokenization, as well as coping with OOV words. (This is expanded based on my MT course lectured by Dr. Rico Sennrich in Edinburgh Informatics in 2018.)
Background
How to Represent Text?
- One-hot encoding
- lookup of word embedding for input
- probability distribution over vocabulary for output
- Large vocabulary
- increase network size
- decrease training and decoding speed
Problems
Open-vocabulary problems:
- Many training corpora contain millions of word types
- Productive word formation processes (compounding; derivation) allow formation and understanding of unseen words
- Names, numbers are morphologically simple, but open word classes
Word-based Tokenization
Limits:
- Very similar words have entirely different meanings, such as dog vs dogs.
- The vocabulary can end up very large.
- Large vocabularies result in enormous embedding matrix as the input and output layer.
Common methods include:
- Space and punctuation tokenization;
- Rule-based tokenization.
Non-solution: Ignoring Rare Words
- Replace OOV words with UNK
- A vocabulary of 50,000 words covers 95% of text: 95% is not enough !
OOV problem:
- If two very different words are both OOV, they wil get the same id ([UNK]).
- Large vocabulary will increase the embedding layer’s parameters.
Approximative Softmax
Compute softmax over “active” subset of vocabulary $\rightarrow$ smaller weight matrix, faster softmax[1]
- At training time: vocabulary based on words occurring in training set partition
- At test time: determine likely target words based on source text (using cheap method like translation dictionary)
Limitations:
- Allow larger vocabulary, but still not open
- Networks may not learn good representation of rare words
Back-off Models
- Replace rare words with UNK at training time [2]
- When system produces UNK, alight UNK to source word, and translate this with back-off method
Limitations:
- Compounds: hard to model 1-to-many relationships
- Morphology: hard to predict inflection with back-off dictionary
- Names: if alphabets differ, we need transliteration
- Alignment: attention model unreliable
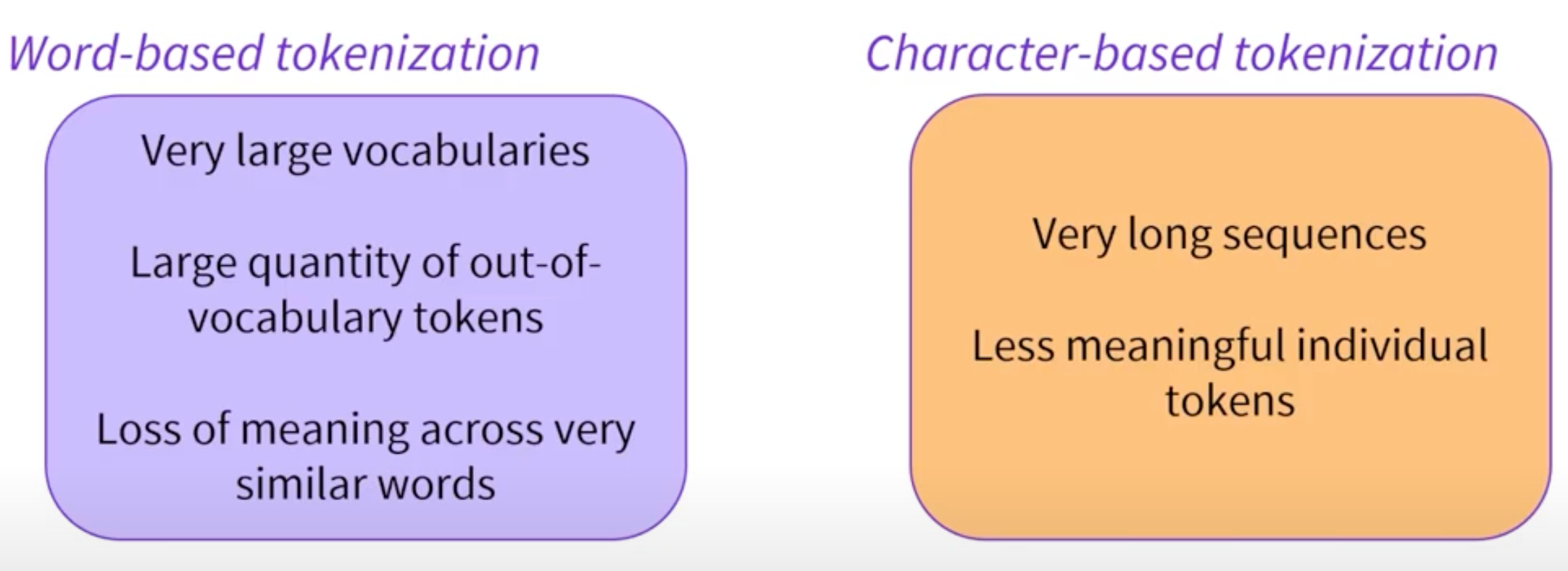
Character-based Tokenization
Advantages:
Character tokens solve the OOV problem with following benefits:
- Vocabularies are slimmer.
- Mostly open-vocabulary: fewer OOV words;
- No heuristic or language-specific segmentation;
- Neural networks can conceivably learn from raw char sequences.
Drawbacks:
Representing the input as a squences of characters can have following problems:
- Character tokens can increase sequence length, which will slow down the speed of training and decoding (x2 - x4 increase in training time), as well as make it difficult to learn relationships between characters to form meaningful words.
- It is harder for the model to learn meaningful input representations. E.g., learn the context-independent reprsentation for a single char “N” is much harder than learning a context-indepdent reprentation for the word “NLP”.
- Naive char-level encoder-decoders are currently resource-limited.
OPEN QUESTIONS:
- On which level do we represent meaning?
- On which level do attention operate?
Hierarchical Model: Backoff
- Word-level model produces UNKs [4]
- For each UNK, char-level model predicts word based on word hidden state
Pros:
- Prediction is more flexible than dictionary look-up
- More efficient than pure char-level translation
Cons:
- Independence assumptions between main model and backoff model
Char-level Output
- No word segmentation on target side [5]
- Encoder is BPE-level
Char-level Input
Hierarchical representation: RNN states represent words, but their representation is computed from char-level LSTM [6]
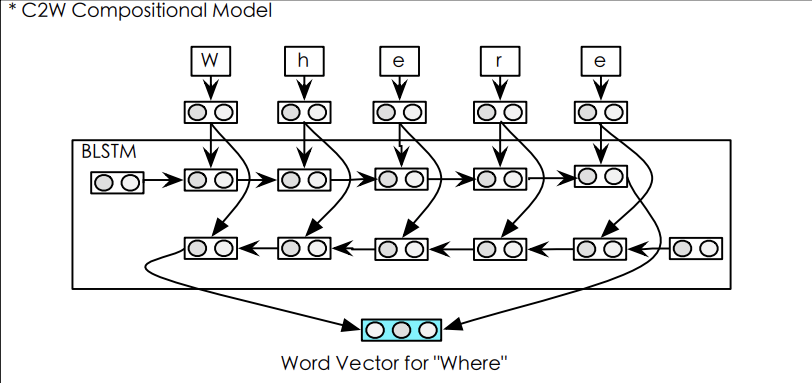
Fully Char-level
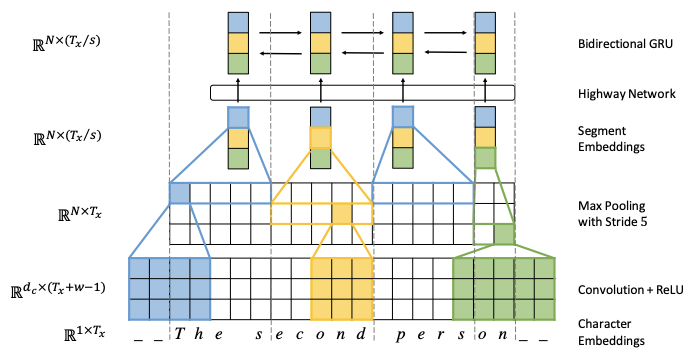
- Goal: get rid of word boundaries [7]
- Target side: char-level RNNs
- Source side: convolution and max-pooling layers
Subword-based Tokenization
The idea behind subword tokenization is that frequently occurring words should be in the vocabulary, whereas rare words should be split into frequent sub words.
Subword-based tokenization lies between character and word-based tokenization.
- Frequently used words should not be split into smaller subwords;
- Rare words should be decomposed into meaningful subwords.
- Subwords help identify similar syntactic or semantic situations in texts.
- Subword. tokenization can identify start of word tokens, such as “##” in WordPiece.
Byte-Pair Encoding
Byte-Pair Encoding (BPE) relies on a pre-tokenizer that splits the training data into words.

Why BPE? [13]
- Open-vocabulary: operations learned on the training set can be applied to
<UNK> - Compression of frequent character sequences improves efficiency $\rightarrow$ trade-off between text length and vocabulary size.
Pre-tokenization
Pretokenzation splits the texts into words, For example:
- Space tokenization, e.g. GPT-2, RoBERTa;
- Rule-based tokenization (using Moses), e.g., XLM, FlauBERT;
- Space and ftfy: GPT.
BPE Training
Given pre-tokenized tokens, we can train a BPE tokenizer as follows:
Bottom-up character merging: [3][13]
- Starting point: char-level representation $\rightarrow$ computationally expensive.
- Compress representation based on information theory $\rightarrow$ byte-pair encoding.
- Repeatedly replace most frequent symbol pair
('A', 'B')with'AB'. - Hyperparameter: when to stop $\rightarrow$ controls vocabulary size.
Step by step:
- Cut the pre-tokenized corpus into smallest units, usually characters, as a base vocabulary.
- Append
</w>at the end of original tokens. - Count the neighbor unit pairs, and merge the pair that occurs most frequently.
- Go to 2 until reach the maximum vocabulary size.
1 | import re, collections |
BPE Encoding
BPE encodes the input tokens one by one, progressively merging the pairs according to frequency during training (from high to low). In other words, merge according to the merge order bpe_codes in merge.txt (with decreasing frequency).1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65# subword-nmt/apply_bpe.py
# Author: R. Sennrich
def encode(orig, bpe_codes, bpe_codes_reverse, vocab, separator, version,
cache, glossaries_regex=None, dropout=0):
"""Encode word based on list of BPE merge operations,
which are applied consecutively
"""
if not dropout and orig in cache:
return cache[orig]
if glossaries_regex and glossaries_regex.match(orig):
cache[orig] = (orig,)
return (orig,)
if len(orig) == 1:
return orig
if version == (0, 1):
word = list(orig) + ['</w>']
elif version == (0, 2): # more consistent handling of word-final segments
word = list(orig[:-1]) + [orig[-1] + '</w>']
else:
raise NotImplementedError
while len(word) > 1:
# get list of symbol pairs; optionally apply dropout
pairs = [(bpe_codes[pair],i,pair) for (i,pair) in enumerate(zip(word, word[1:])) if (not dropout or random.random() > dropout) and pair in bpe_codes]
if not pairs:
break
#get first merge operation in list of BPE codes
bigram = min(pairs)[2]
# find start position of all pairs that we want to merge
positions = [i for (rank,i,pair) in pairs if pair == bigram]
i = 0
new_word = []
bigram = ''.join(bigram)
for j in positions:
# merges are invalid if they start before current position.
# This can happen if there are overlapping pairs: (x x x -> xx x)
if j < i:
continue
new_word.extend(word[i:j]) # all symbols before merged pair
new_word.append(bigram) # merged pair
i = j+2 # continue after merged pair
new_word.extend(word[i:]) # add all symbols until end of word
word = new_word
# don't print end-of-word symbols
if word[-1] == '</w>':
word = word[:-1]
elif word[-1].endswith('</w>'):
word[-1] = word[-1][:-4]
word = tuple(word)
if vocab:
word = check_vocab_and_split(word, bpe_codes_reverse, vocab, separator)
cache[orig] = word
return word
WordPiece
WordPiece was firstly proposed in Google’s Japanese and Korean voice search system[8], and was used in Google’s machine translation system[9]. It deals with an infinite vocabulary from large amounts of text automatically and increamentally by running greedy algorithms. This provides a user-specified number of word units which are chosen in a greedy way (without focusing on semantics) to maximize the likelihood on the language model (LM) training data - incidentally the same metric during decoding.
Example:
- Word: Jet makers feud over seat width with big orders at stake
- Wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
Procedure:
- Initialize the word unit inventory with basic unicode characters.
- Build a language model on the triaining data using the inventory from 1.
- Generate a new word unit by combinining two units out of the current word inventory to increment the word unit inventory by one. “Choose the new word unit out of all possible ones that increases the likelihood on the training data the most when added to the model”.
- Goto 2 unitil reach the predefined limit of word units, or the likelihood increase falls below a certain threshold.
How to choose which pair to merge?
Suppose we get $z$ after merging neibor subwords $x$ and $y$, the difference between LM loglikelihood is:
This is exactly the mutual infomation (MI) under the trained LM between the subword pair $(x,y)$. Therefore, WordPiece chooses the subword pair that has the maximum MI value.
Unigram Language Model
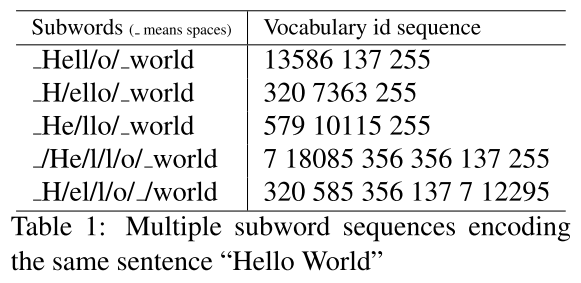
Motivation:
- A sentence can be represented into multiple subword sequences even with the same vocabulary using BPE. Subword regularization is a regularization method for open-domain NMT.
Subword Regularization based on a unigram language model[10] assumes that each subword occurs independently, and consequently, the probability of a subword sequence $\mathbf{x} = (x_1, \cdots, x_M)$ is formulated as the product of the subword occurence probablities $p(\mathbf{x})$:
where $\mathcal{V}$ is a pre-determined vocabulary. The most probable segmentation $\mathbf{x}^*$ for the input $X$ is given by:
where $\mathcal{S}(X)$ is a set of segmentation candidates built from the input sentence $X$. $\mathbf{x}^*$ is obtained from the Viterbi algorithm.
Procedure:
- Heuristically make a reasonably big seed vocabulary from the training corpus. Possible choices are:
- All chars and the most frequent substrings.
- BPE with sufficient mergence.
- Fix the vocab, optimize $p(x)$ with EM algorithm
- Compute the loss for each subword $x_i$ using a unigram language model, representing how likely the likelihood $\mathcal{L}$ is reduced when the subword $x_i$ is removed from the current vocabulary inventory.
- Sort the vocabularies by loss and keep top $\eta \%$ ($\eta = 80$) of subwords. (Always keep the single char set to avoid OOV).
- Goto 2.
Interpretation
- Subword regularization with unigram language model can be seen as a probabilistic mixture of characters, subwords, and word segmentations.
- I regard it as a post-regularization approach to subwords techniques, such as BPE units. This means we can use BPE word pieces as the initialization.
Comparison
| Subword tokenization | Merge rules | Trim rules | Frequency-based | Probability-based |
|---|---|---|---|---|
| BPE | ✔ | ✘ | ✔ | ✘ |
| WordPiece | ✔ | ✘ | ✘ | ✔ |
| Unigram | ✘ | ✔ | ✘ | ✔ |
Comparison between subword methods:
- BPE $\Uparrow$: start from char sets, incrementally merge according to (neighbor) subword pair co-occurrence.
- WordPiece$\Uparrow$: start from char sets, incrementally merge according to the decreased likelihood (Mutual Information) after mergence.
- Unigram Language Model (subword regularization)$\Downarrow$: starting from subword vocabularies, reducing the subword with likelihood reduction under a unigram LM after mergence.
For attribution in academic contexts, please cite this work as:1
2
3
4
5
6@misc{chai2019out-of-vocab,
author = {Chai, Yekun},
title = {{Word Tokenization: How to Handle Out-Of-Vocabulary Words?}},
year = {2019},
howpublished = {\url{https://cyk1337.github.io/notes/2019/03/08/NLP/How-to-handle-Out-Of-Vocabulary-words/}},
}
References
- 1.On Using Very Large Target Vocabulary for Neural Machine Translation ↩
- 2.Addressing the Rare Word Problem in Neural Machine Translation ↩
- 3.[BPE] Neural Machine Translation of Rare Words with Subword Units Rico ↩
- 4.Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models ↩
- 5.A Character-level Decoder without Explicit Segmentation for Neural Machine Translation ↩
- 6.Character-based Neural Machine Translation ↩
- 7.Fully Character-Level Neural Machine Translation without Explicit Segmentation ↩
- 8.[WordPiece] Japanese and Korean voice search (ICASSP 2012, Google) ↩
- 9.Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation ↩
- 10.Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates ↩
- 11.A comprehensive guide to subword tokenisers ↩
- 13.Rico Sennrich. MT lecture 07. Edinburgh Informatics 2018. ↩
- 14.Hugginface tokenizer ↩
- 15.[GPT-2]Language models are unsupervised multitask learners ↩