
A survey of the normalization tricks in Neural Networks.
Feature Normalization
Data Preprocessing
Normalization: subtract the mean of the input data from every feature, and scale by its std deviation.
PCA (Principal Components Analysis)
- Decorrelate the data by projecting onto the principal components
- Also possible to reduce dimensionality by only projecting onto the top $P$ principal components.
Whitening
- Decorrelate by PCA
- Scale each dimension
Batch Normalization
Problems:
Internal covariate shift: the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful parameter initialization, and make it notoriously hard to train models withsaturating nonlinearities.
- Intuition : To reduce the
internal covariate shift, by fixing the distribution of the layer inputs $x$. - Idea: The NN converges faster if the inputs is whitened, i.e. linearly transformed to have zero mean and unit variance, and decorrelated.
Solution: batch normalization (BN) [1].
- Use mini-batch statistics to normalize activations of each layer.
- Parameter $\gamma$ and $\beta$ can scale and shift (a.k.a. bias) the normalized activations.
- BatchNorm depends on the current training example - and on examples in mini-batch (for computing mean and variance)
Training
- Set parameters $\gamma$ and $\beta$ by gradient descent - require gradients $\frac{\partial E}{\partial \gamma}$ and $\frac{\partial E}{\partial \beta}$
- TO backpropagate gradients through the batchNorm layer aliso require: $\frac{\partial E}{\partial \hat{u}}$, $\frac{\partial E}{\partial \sigma^2}$, $\frac{\partial E}{\partial \mu}$, $\frac{\partial E}{\partial u_i}$
Runtime: use the sample mean and variance computed over the complete training data as the mean and variance parameters for each layer - fixed transform:
- Backprop: see [2]

- Input: values of $x$ over a mini-batch:
Outputs:
mini-batch mean:
mini-batch variance:
normalize:
scale and shift:
Parameters: $\gamma$ and $\beta$ are trainable parameters with size $C$ (where $C$ is the channel size). By default, the elements of $\gamma$ are set to 1s and the elements of $\beta$ are set to 0s.
1 | class BatchNorm(nn.Module): |
- Benefits
- Make training many-layered networks easier.
- allow
higher learning rates weight initializationless cruc
- allow
- Can act like a regularizer: can reduce need for techniques like dropout
- Make training many-layered networks easier.
Pros:
- Prevent small changes to the parameters from amplifying into larger and suboptimal changes in activations in gradients, e.g. it prevents the training from getting stuck in the saturated regimes of nonlinearities.
- More resilient to the the parameter scale. Large learning rates may increase the scale of layer parameters, which then amplify the gradient during back-propagation and lead to the model explosion.
Drawbacks:
- BN performs different in training and test time.
- It is not legitimate at
inference time, so the mean and variance are pre-computed from the training set, often by runningaverage.
Different opinion at NIPS 2018: [7]
- Argument: BatchNorm cannot handle
internal covariate shift, i.e. no link between the performance gain of BatchNorm and the reduction of internal covariate shift. It makes theoptimization landscape significantly smoother. - Experiment: inject random noise with a severe covariate shift after batch normalization, which still performs better when training.
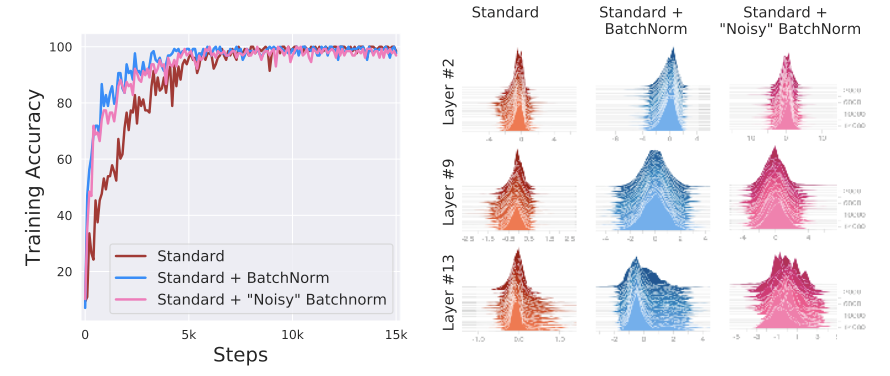
- BatchNorm makes the landscape significantly more smooth: improvement in the Lipschitzness of the loss function. i.e. the loss exhibits a significantly better “effective” $\beta$-smoothness.
- Reparametrization make it more stable (in the sense of loss Lipschitzness)
- more smooth (in the sense of “effective” $\beta$-smoothness of the loss)
Layer Normalization
Problems:
- Batch normalization is dependent on the mini-batch size, i.e. cannot apply on extremely small minibatches.
- Not obvious how to apply on RNNs. It can easily applied on FFNN because of the fixed length of inputs.
Solution: layer normalization (LN)[3].
- Compute the layer normalization statistics over all hidden units in the same layer:
where $H$ denotes the # of hidden units in a layer. Under layer norm, all hidden states in a layer share the same normalization terms $\mu$ and $\sigma$. Furthermore, it does not impose any constraint on the size of a mini-batch, and it can be used in the pure online regime with batch size 1.
where the mean and standard deviation are calculated seperately over the last certain number dimensions which have to be of the shape specified by the last dim. $\gamma$ and $\beta$ are learnable affine transform parameters. Denoting the hidden dim as $D$, the parameter count of LN is $2*D$.
1 | import torch |
Layer Normalization on RNNs
In a std RNN, $h^{t-1}$ denotes previous hidden states, $x^t$ represents the current input vector:
Do layer normalization:
where is the recurrent hidden to hidden weights and are the bottom up input to hidden weights, $\odot$ is element-wise multiplication between to vectors.
Differences between batch normalization and layer normalization:
- LN: neurons in the same layer have the same mean and variance; different input samples have different mean and variance.
- BN: input samples in the same batch have the same mean and variance; different neurons.
Unlike BN, layer norm performs exactly the same computation at training and test times.
RMSNorm
Root Mean Square Normalization (RMSNorm)[8] hypothesize that the rescaling invariance is the reason for success of LayerNorm, rather than re-centering invariance. RMSNorm rescales invariance and regularizes the summed inputs using root mean square (RMS) statistic:
RMSNorm simplifies LayerNorm by totally removing the mean statistic at the cost of sacrificing the invariance that mean normalization affords. When the mean of summed inputs is zero, RMSNorm is exactly equal to LayerNorm.
Implementation:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47# Code source: https://github.com/bzhangGo/rmsnorm/blob/master/rmsnorm_torch.py
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
def __init__(self, d, p=-1., eps=1e-8, bias=False):
"""
Root Mean Square Layer Normalization
:param d: model size
:param p: partial RMSNorm, valid value [0, 1], default -1.0 (disabled)
:param eps: epsilon value, default 1e-8
:param bias: whether use bias term for RMSNorm, disabled by
default because RMSNorm doesn't enforce re-centering invariance.
"""
super(RMSNorm, self).__init__()
self.eps = eps
self.d = d
self.p = p
self.bias = bias
self.scale = nn.Parameter(torch.ones(d))
self.register_parameter("scale", self.scale)
if self.bias:
self.offset = nn.Parameter(torch.zeros(d))
self.register_parameter("offset", self.offset)
def forward(self, x):
if self.p < 0. or self.p > 1.:
norm_x = x.norm(2, dim=-1, keepdim=True)
d_x = self.d
else:
partial_size = int(self.d * self.p)
partial_x, _ = torch.split(x, [partial_size, self.d - partial_size], dim=-1)
norm_x = partial_x.norm(2, dim=-1, keepdim=True)
d_x = partial_size
rms_x = norm_x * d_x ** (-1. / 2)
x_normed = x / (rms_x + self.eps)
if self.bias:
return self.scale * x_normed + self.offset
return self.scale * x_normed
Llama Implementation:
1 | # source: https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/llama/modeling_llama.py#L75C1-L89C59 |
Instance Normalization
Image style transfer
- Transfer a style from one image to another, which relies more on a specific instance rather than a batch.
Solution:
- Instance normalization (IN) [4] , a.k.a. contrast normalization, do instance-specific normalization rather than batch normalization.
- It performs the same at training and test time.
Group Normalization
Problems:
- BN’s error increases rapidly when the
batch sizebecomes smaller because ofinaccurate batch statistics estimation.
Solution: Group Normalization (GN)[5]. GN divides the channels into groups and computes within each group the mean and variance for normalization. GN’s computation is independent of batch sizes, and its accuracy is stable in a wide range of batch sizes.
GN divides the set as:
where $G$ is the number of groups, $C/G$ is the number of channels per group, $k$, $i$ is the index. GN compute the $\mu$ and $\sigma$ along the (H,W) axes and along a group by $\frac{C}{G}$ channels.
1 | def GroupNorm(x, gamma, beta, G, eps=1e-5): |
Switchable Normalization
Problems:
- Existing BN, IN, LN employed the same normalizer in all normalization layers of an entire network, rendering suboptimal performance.
- Different normalizers are used to solve different tasks, making model design cumbersome.
Solution:
- Switchable Normalization (SN) [6]. It combines three distinct scopes to compute statistics (i.e. mean and variance): channel-wise, layer-wise and minibatch-wise, by using IN, LN and BN respectively. SN switches them by learning their importance weights end-to-end.
Given a 4D tensor [N,C,H,W], denoting the # of samples, # of channels, heights and weights. Let and be a pixel before and after the normalization, where $n \in [1,N]$, $c \in [1,C]$, $i \in [1,H]$ and $j \in [1,W]$. $\gamma$ and $\beta$ are a scale and shift parameter respectively, $\epsilon$ is a small constant to preserve numerical stability.
where $\Omega = { \text{in, ln, bn} }$:
Different normalizers estimate statistics along different axes.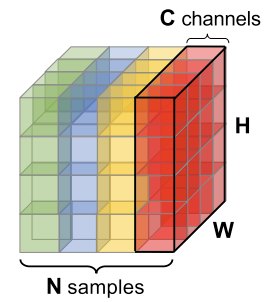
1 | def SwitchableNorm(x, gamma, beta, w_mean, w_var, eps=1e-5): |
Comparison
The mini-batch data has the shape [N, C, H, W], where
- $N$ is the batch axis
- $C$ is the channel axis (rgb for image data)
- $H$ and $W$ are the spatial hight and weight axis
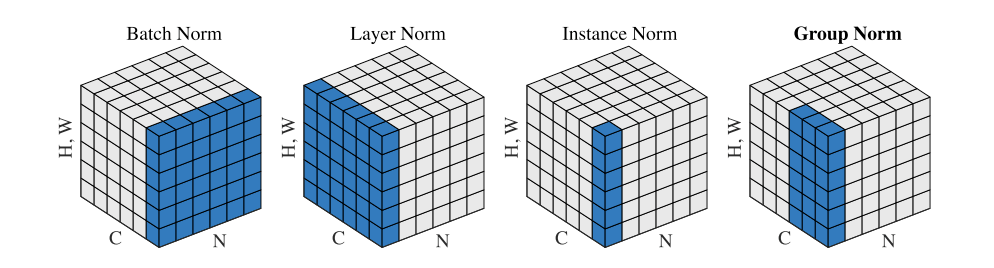
Comparison:
- Batch Norm is applied on batch, normalizing along (N, H, W) axis, i.e. compute the mean and variance for the whole batch of input data. (It performs badly for small batch size)
- Layer Norm is on channel, normalizing along (C,H,W) axis, i.e. it is independent with batch dimension, by normalizing the neurons. (It is obvious for RNNs).
- Instance Norm is applied on image pixel, doing normalization along (H,W) axis, i.e. compute $\mu$ and $\sigma$ for each sample and channel. (It is for style transfer)
- Group Norm: divide the channel into groups, normalizing along the (H,W) axis and along a group of $\frac{C}{G}$ channels.
- Switchable Norm: dynamically learn weights for IN/LN/BN statistics in the e2e manner (c.f. ELMo).
References
- 1.Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift ↩
- 2.What does the gradient flowing through batch normalization looks like ? ↩
- 3.Layer normalization ↩
- 4.Instance Normalization: The Missing Ingredient for Fast Stylization ↩
- 5.Group Normalization ↩
- 6.Differentiable learning-to-normalize via Switchable Normalization ↩
- 7.How Does Batch Normalization Help Optimization? ↩
- 8.Zhang, Biao, and Rico Sennrich. "Root mean square layer normalization." Advances in Neural Information Processing Systems 32 (2019). ↩