
Notes of lectures by D. Silver.
Introduction
- Dynamic: sequential or temporal components to the problem
Programming: optimizing a “program”, i.e. a policy
c.f. linear programmingBreaking down the complex problems into subproblems
- Solve the problems
- Combine solutions to subproblems
Requirements for dynamic programming
Dynamic programming(DP) is general solution for problems with two properties:
- Optimal substructure
- Principle of optimality applies
- Optimal solution can be decomposed into subproblems
- Overlapping subproblems
- Subproblems recur many times
- Solutions can be cached and reused
MDP satisfy both properties:
- Bellman equation gives recursive decomposition
- Value function stores and reuses solutions
Planning by DP
- DP assumes full knowledge of the MDP
- It is used for planning in an MDP
- For prediction:
- Input: DMP $<\mathcal{S}, \mathcal{A},\mathcal{P},\mathcal{R},\mathcal{\gamma}>$ and policy $\pi$, or MRP $<\mathcal{S},\mathcal{P}^{\pi},\mathcal{R}^{\pi},\mathcal{\gamma}>$
- Output: value function
- For control:
- Input: MDP $<\mathcal{S}, \mathcal{A},\mathcal{P},\mathcal{R},\mathcal{\gamma}>$
- Output: optimal value function , and optimal policy
Other applications by DP
- Scheduling algorithms
- String algorithms (e.g. sequence alignment)
- Graph algorithms (e.g. shortest path algorithms)
- Graphical models (e.g. Viterbi algorithm)
- Bioinformatics (e.g. lattice model)
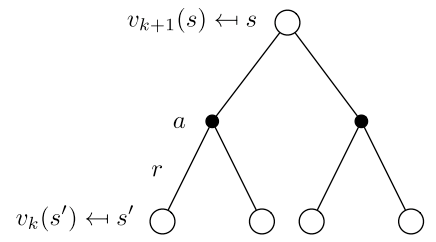
Iterative policy evaluation
- Problem: evaluate a given policy $\pi$
- Solution: iterative application of Bellman expectation backup
Using synchronous backups:
- At each iteration $k+1$
- For all states $s \in \mathcal{S}$
- Update from , where $s’$ is a successor state of $s$
Policy iteration
How to improve a policy
Given a policy $\pi$:
- Evaluate the policy $\pi$
- Improve the policy by acting greedily w.r.t
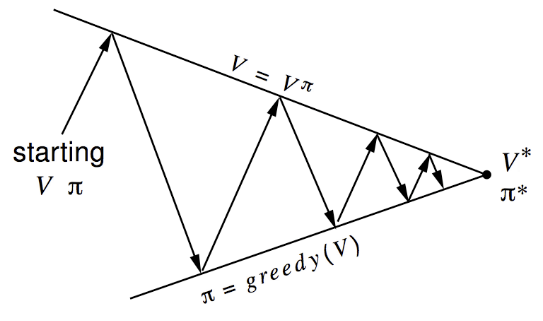
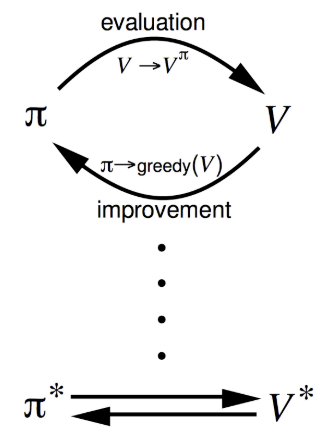
Policy evaluation: estimate (iterative policy evaluation)
Policy improvement: generate (greedy policy improvement)
Policy improvement
Consider a deterministic policy $a=\pi(s)$
- Improve the policy by acting greedily
This improves the value from any state $s$ over one step
It therefore improves the value function
- If improvements stop,
Then the Bellman optimality equation has been satisfied
Therefore for all $s \in \mathcal{S}$. So $\pi$ is an optimal policy
Value iteration
Value iteration in MDPs
Principle of Optimality
An optimal policy can be subdivided into two components:
- An optimal first action
- Followed by an optimal policy from successor state $S’$
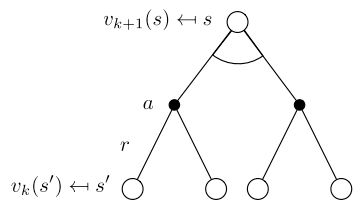
Deterministic value iteration
If we know the solution to subproblems , then solution can be found by one-step lookahead:
- The idea of value iteration is to apply these update iteratively
- Intuition: start with final rewards and work backwards
- Still works loopy, stochastic MDPs
Value iteration
- Problems: find optimal policy $\pi$
Solution: iterative application of Bellman optimality backup
Using synchronous backups at each iteration $k+1$, for all states , update from
- Unlike policy iteration , there is no explicit policy
Synchronous DP algorithms
| Problem | Bellman equation | Algorithm |
|---|---|---|
| Prediction | Bellman Expectation Equation | Iterative Policy Evaluation |
| Control | Bellman Expectation Equation + Greedy Policy Improvement | Policy Iteration |
| Control | Bellman Optimality Equation | Value Iteration |
Asynchronous DP
In-place DP
Synchronous value iteration stores two copies of value function for all $s$ in $\mathcal{S}$:
In-place value iteration only stores one copy of value function for all $s$ in $\mathcal{S}$:
Prioritized sweeping
Use magnitude of Bellman error to select state
Backup the state with the largest remaining Bellman error
Real-time DP
- Idea: only states that are relevant to agent
- Use agent’s experience to guide the selection of states
- After each time-step
- Backup the state