
Ensemble learning combines multiple weak learners to build a strong learner.
Simple techniques
Majority voting
Majority voting is generally used in classification tasks: take the majority of the model predictions as the final prediction.
Averaging
Take the average of predictions from all the models as the final prediction, in regression or classification (the average of probabilities) tasks.
Weighted average
Assign different weights defining the importance of each model for different models.
Advanced ensemble techniques
Stacking
Stacking (a.k.a. Stacked Generalization, or Super Learner) employs a number of first-layer individual learners (model 1-5 / Tier-1 in the below figures) generated from the training data set, followed by a second-level learner (model 6 / Tier-2, a.k.a. meta-learner).
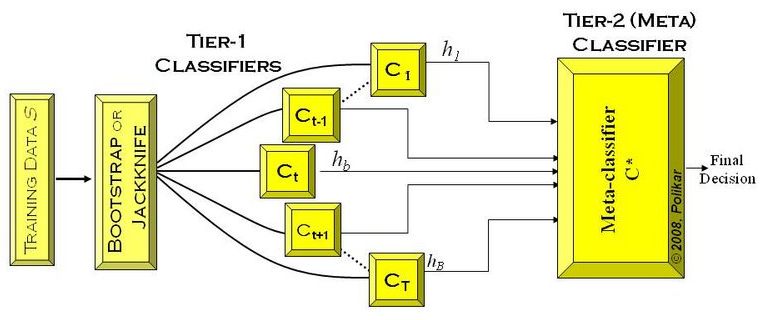


Blending
Similar to stacking, but use only a devset from the training set to make predictions. The devset and the predictions are used to build the model on test set.
Bagging
Bagging(Bootstrap aggregating):
- Bootstrapped subsampling;
- Fit the base model on each of these subsets;
- Models are run in parallel and independent of each other;
- The final prediction are determined by combining all model predictions.
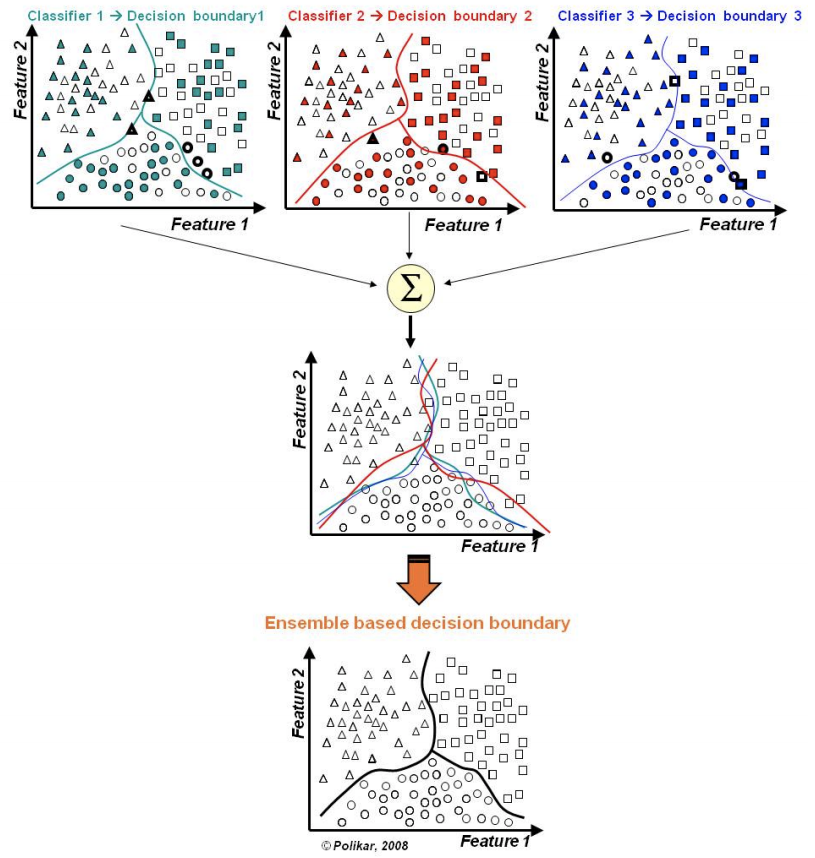
Random forest

Pros:
- Robust against outliers and noise;
- Reduce variance and typically avoids overfitting;
- Fast run time;
Cons:
- Can be slow to score as complexity increases;
- Lack of transparency due to the complexity of multiple trees;
Boosting
Boosting is a sequential process, where each subsequent model attempts to correct the errors of the previous model.
- Create a subset of all dataset.
- Initially, all data points are given the same weights.
- Fit a base model on this subset.
- Use this base model to predict on the whole dataset.
- Calculate errors using golden standard and predictions.
- The wrongly predicted data are given higher weights.
- Another model is created with step 3-6. (in order to correct the errors from the previous model)
- Multiple models are created, each correcting the error of the previous model.
- The final model (strong learner) is the weighted mean of all the models.
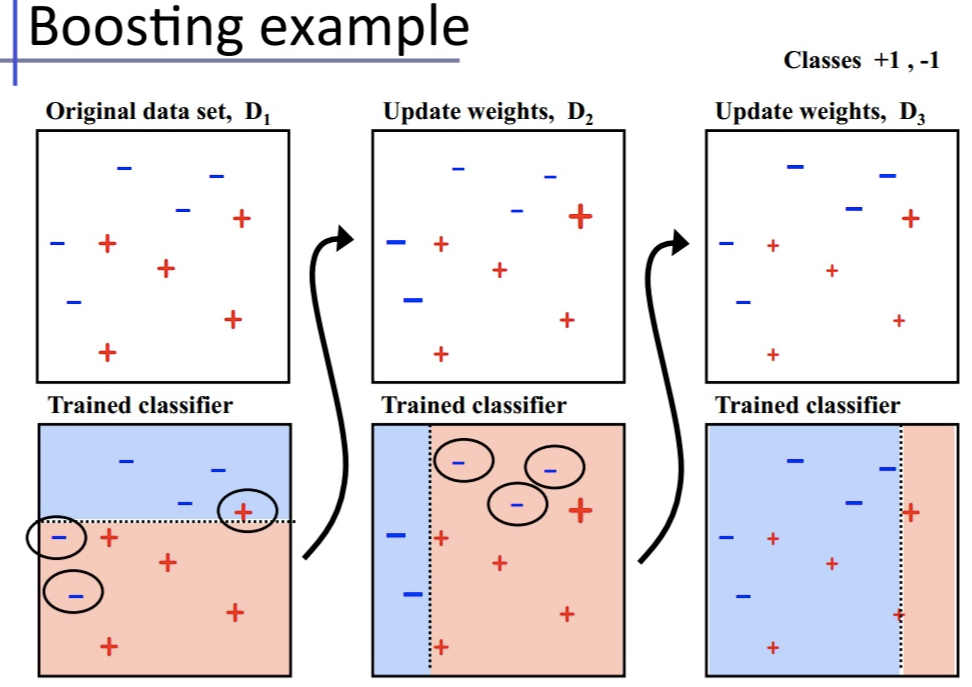

AdaBoost
Adaptive Boosting

Pros:
- Often the best possible model;
- Directly optimize the cost function;
Cons:
- Not robust against outliers and noise;
- Can overfit;
- Need to find proper stopping point;
Comparing bagging and boosting
Model error arises from noise, bias, and variance.
- Noise is error by the target function;
- Bias is where the algorithm cannot learn the target;
- Variance comes from sampling.
Boosting is recommended on models that have a high bias, not Bagging.
Conversely, Bagging is recommend for cases of high variance, rather than Boosting.
GBM(Gradient Boosted Models)
XGBoost
XGBoost[1]
Light GBM
It is useful for large-size dataset.
CatBoost
References
- 1.Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. KDD. ↩
- 2.Zhou Z. (2016) Ensemble learning ↩