
Why is NER hard in the industry?
This blog dicusses several frequently occurred problems and possible solutions.
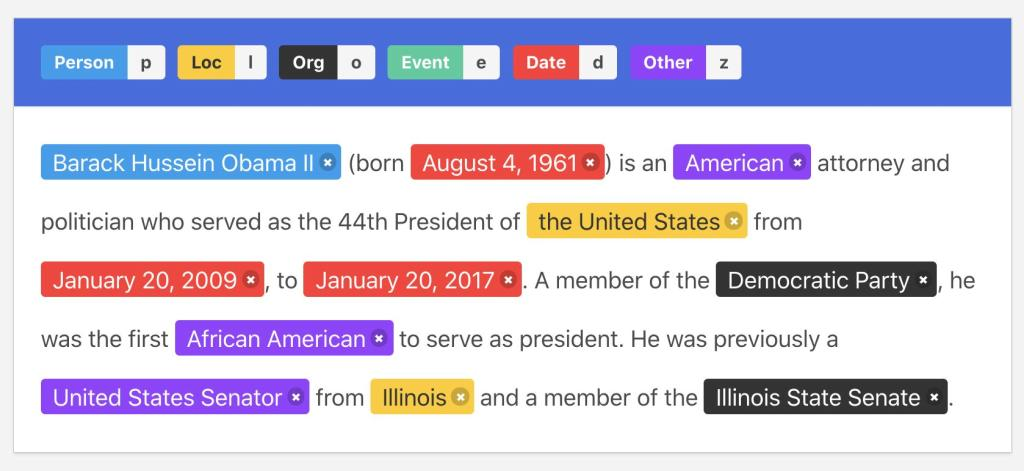
Related blog:
Industrial NER Problems
Background: Named Entity Recognition (NER) has always been a fundamental task in the NLP tasks, including information extraction, relation extraction, information retrieval, question answering, etc. The prevalent solution to NER is BiLSTM-CRF model, but there still exist several issues in the real scenario.

Possible problems including:
- Expensive cost for manual labeling
- Incapability of generalization and transferability. For example, transfer between different domains.
- Weak interpretability. In certain domains such as medical NER, the “black box” is not relable for decision making.
- Low computing resources. E.g., some medical data is confidential and only accessible on the deivices of a hospital, where there is no enough GPU resource for computing.
Q1. How to quickly improve the NER performance in the industry?
For vertical domain:
- Adopt BiLSTM-CRF models.
- Analyze bad cases;
- Consistently build the in-domain lexicon and improve the pattern-based method.
For general domain:
- Construct syntactic features to feed into NER. For Chinese/Japanese NER, also use segmented words.
- Combine lexicon.
Q2. How to improve towards neural models?
NER focus more on the bottom features. Try to introduce rich features, such as char, bi-gram, lexicon, POS tagging, ElMo, etc. In the vertical domain, we can pretrain a in-domain word embedding or language model. Try to build multiple features from different views.
Q3. How to incorporate lexicon embedding into Chinese NER?
- Simple-Lexicon
- FLAT
Q4. How to solve over-long entity span?
If certain type of spans are too long, try:
- Use rule for postfix.
- Adopt pointer network + CRF for multi-task learning.
Q5. How to treat BERT in NER?
In situations with no computing limit, in general domain, or few-shot problems.